BifroMQ's Topic Subscription Mechanism

Introduction
Since BifroMQ became open source, we have frequently received inquiries about its implementation details for Topic subscription matching. In the MQTT Pub/Sub mechanism, Topic subscription matching is undoubtedly one of the core functionalities. In BifroMQ, the management of subscription information and the processing of message Topic matching are handled by a dedicated service module called Dist Service (bifromq-dist). Given that BifroMQ is designed to support the construction of large-scale, multi-tenant Serverless systems, this critical component faces many complex challenges, particularly in the distributed processing of subscription information (TopicFilter) and the associated Topic matching algorithms. This article will delve into the design decision behind the BifroMQ Topic subscription matching scheme and its implementation in Dist Service.
MQTT's Topic and TopicFilter
In this section, we shall briefly revisit two fundamental concepts in MQTT related to Topic subscription and matching: Topic and TopicFilter. During the publication (Pub) process in MQTT, a Topic is used to identify the specific subject of a message. Conversely, during the subscription (Sub) process, a TopicFilter is employed to denote the intention to subscribe to a series of subjects. This article will distinctly differentiate these two concepts: Topic and TopicFilter.
Both Topic and TopicFilter are UTF-8 strings, akin to file directory paths, examples being “/a/b/c”, “/a/b/c/”, “/+/b/c”, and “+/b/#”. In these strings, “/” serves as the separator for each 'directory' or TopicLevel. The primary difference between TopicFilter and Topic lies in the character set of the TopicLevel: TopicFilter permits the use of wildcard characters “+” and “#” as standalone TopicLevels. These wildcards represent the logic for matching a range of topics. The “+” symbol is a single-level wildcard character (Single-level Wildcard Character), which can appear in any position (e.g., “+”, “/+”, “+/+”) and is used to match all TopicLevels at that particular level. The “#” symbol, on the other hand, is a multi-level wildcard character (Multi-level Wildcard Character), and can only appear as the last TopicLevel (e.g., “#”, “/#”, “+/+/#”, “+/#”), used to match the specified level and all subsequent levels of TopicLevels.
TopicFilter matches Topics in a left-to-right sequence. Here are some examples from the MQTT specification to illustrate this point:
First, let's consider the application of the single-level wildcard “+”. Suppose a client subscribes to “sport/+/player1”; it will receive messages published under the following Topic names:
- “
sport/tennis/player1” - “
sport/badminton/player1” - “
sport/golf/player1” However, it will not receive messages for “sport/tennis/player2” or “sport/tennis/player1/ranking”. Similarly, if a client subscribes to “``+/tennis/player1`”, it will receive messages for: - “
sport/tennis/player1” - “
world/tennis/player1” But it will not receive messages for “sport/tennis/player2” or “sport/badminton/player1”. Next, let’s consider the multi-level wildcard “#”. For example, if a client subscribes to “sport/tennis/player1/#”, it will receive messages published under: - “
sport/tennis/player1” - “
sport/tennis/player1/ranking” - “
sport/tennis/player1/score/wimbledon”
Important points to note when using “#” include:
- “
sport/#” will also match the singular “sport”, as “#” includes the parent level. - Subscribing to “
#” alone will match all Topics and receive messages on all subjects. - “
sport/tennis/#” is valid, while “sport/tennis#” and “sport/tennis/#/ranking” are not valid.
These examples clearly demonstrate how TopicFilters in MQTT can precisely and flexibly match specific ranges or types of messages.
It is noteworthy that the process of matching TopicFilter to a Topic can logically organize the TopicFilter into a Trie(or Tree) data structure, with the matching process being accomplished through tiered searching within the TopicFilter Trie. Special handling rules are applied when encountering special wildcard characters such as “+” and “#”. Below is a brief description of this process:
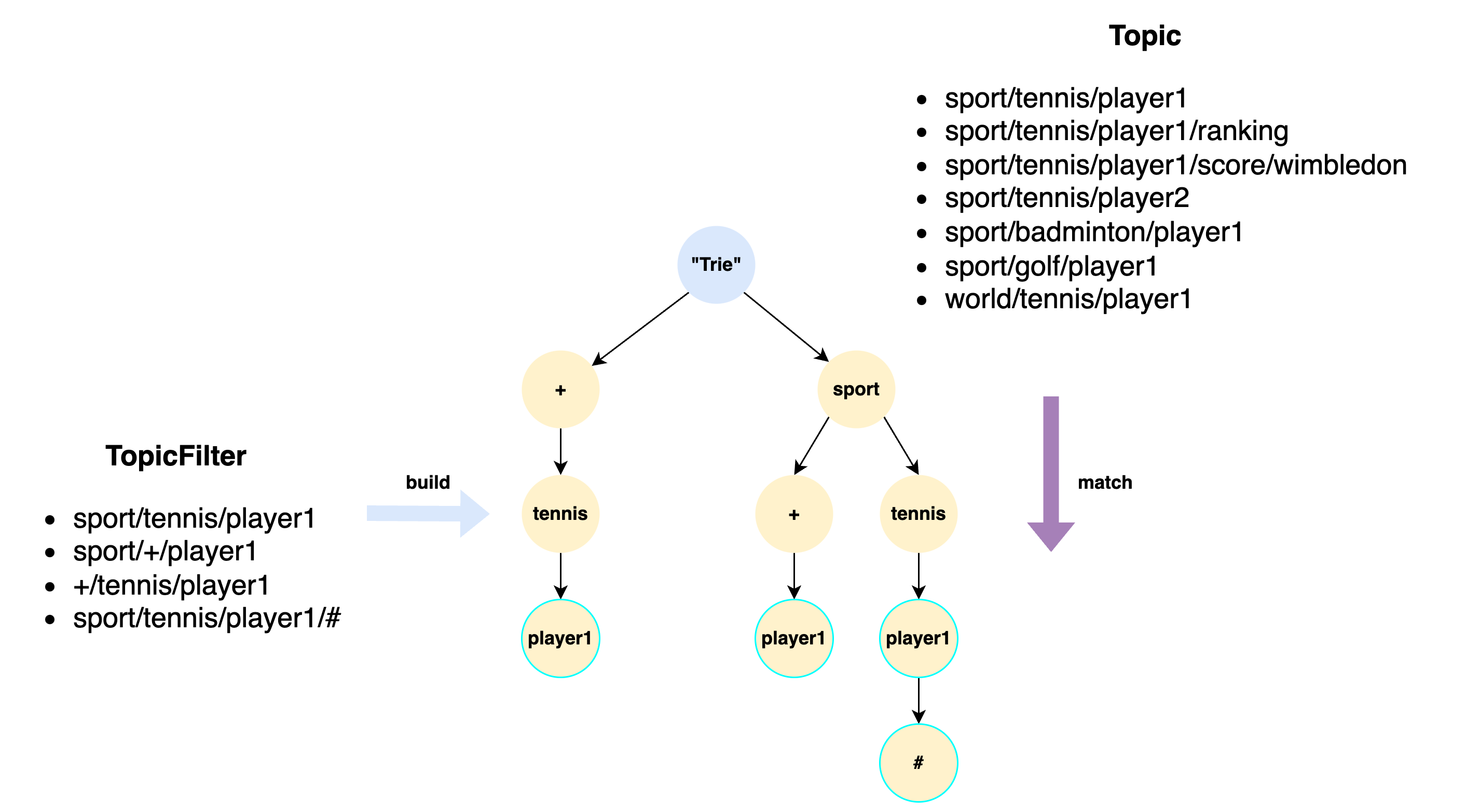
Note:
- Each node within the TopicFilter Trie represents a string of a TopicLevel, which is different from the traditional String Prefix 'Trie' where each node denotes a single character.
- When a TopicFilter does not contain any wildcard characters, its matching scope is limited to specific message topic. In such cases, a simple Map structure can be employed for subscription matching.
- As per MQTT protocol, Topics starting with “$” are considered specially reserved system topics. These topics are not matched by wildcards and are specifically ignored during the search process.
Scenarios Faced by BifroMQ
In this chapter, we will explore the specific scenarios and challenges BifroMQ faces when dealing with the TopicFilter Trie. In typical implementations, the TopicFilter Trie is physically organized as a Trie (or Tree) structure in memory. In a distributed environment, each MQTT Broker node locally stores a complete replica of the TopicFilter Trie and maintains consistency among the nodes through inter-cluster communication. Given that read requests (i.e., matching operations) for the TopicFilter Trie are much more frequent than write requests (updates), traditional implementations allow the topic matching process to occur entirely locally, thus saving the round-trip time of remote access. However, this approach has two potential limitations:
- The size of the TopicFilter Trie is limited by the storage resources of a single node.
- When adding new nodes, it is necessary to fully synchronize the TopicFilter Trie from other nodes, and the preparation time for the startup process is directly proportional to the size of the Trie.
For most enterprise-level application scenarios, these potential issues are usually not a concern, as the scale of subscriptions is unlikely to reach the upper limit of a single node's resources. However, in cloud service environments, especially in Multi-Tenant Serverless service scenarios that BifroMQ aims to support, this traditional approach is no longer suitable. The main reasons include:
- One common issue in multi-tenant scenarios is that the TopicFilter Trie becomes too large, exceeding the resource limits of a single node. This situation is especially prevalent in scenarios with a large number of IoT devices, such as SmartHome business, or due to improper subscription behavior and testing activities.
- A large TopicFilter Trie usually indicates a business peak hours, necessitating rapid scaling so that new nodes can be quickly in service. However, fully synchronizing the Trie consumes preparation time during startup.
Therefore, BifroMQ needs to explore solutions different from the classic approach to better adapt to the needs of building Multi-Tenant Serverless services. The core challenges of this new solution include:
- How to achieve the distribution of the TopicFilter Trie.
- How to efficiently perform matching operations in a distributed environment.
Addressing these challenges involves a completely new design of the storage mode and algorithms for the TopicFilter Trie, which we refer to as the 'OnePass' method.
The "OnePass" Solution
In an in-depth analysis of MQTT's topic matching rules, we observe a significant characteristic: for any given Topic, all possible TopicFilters that can match that Topic form a specific set. We refer to this set as the TopicFilter ExpansionSet(or ExpansionSet briefly) for a particular Topic. The following figure illustrates this concept:

The ExpansionSet of particular Topic can also be represented using a Trie structure. In this structure, nodes at the same level are sorted in byte order. By performing an in-order traversal of the Trie of the ExpansionSet, we can obtain all possible TopicFilter strings arranged in lexicographical order. It's important to note that during the comparison process, the delimiter '/' is not considered, or it can be replaced with a Unicode null character ('\u0000'). The size of the ExpansionSet (i.e., the number of possible TopicFilters) is related to the number of levels in the Topic and can be determined by the formula F(x) = 6*2^x - 1, with its space complexity being O(2^x), increasing geometrically with the number of levels.
However, for a specific Topic, the actual subscriptions that occur are just a small subset of its ExpansionSet. Therefore, we can store the subscriptions that actually occur within the system, using TopicFilter as a key prefix, in an ordered KV storage engine. In BifroMQ, this storage engine is implemented by base-kv -- The embedded distributed KV storage engine for building stateful services in BifroMQ. The storage mode of the TopicFilter Trie, formed by subscriptions, can be simplified as follows:
- key:
<TenantId><0x00><TopicFilter><SessionId> - value:
<MetadataAboutTheSubscription>
Using ordered KV storage, it is easy to achieve the distribution of the TopicFilter Trie logically formed by actual subscriptions. In BifroMQ, we utilize the sharding capability of base-kv to achieve this: subscriptions are distributed and balanced among nodes based on certain strategies, according to the load characteristics of topic subscription matching. During system scaling, new nodes only need to synchronize a portion of the shard replicas, eliminating the need to synchronize all subscription data, thereby meeting the requirements for rapid scaling.
After organizing subscription data into an ordered KV form, the next question is how to implement MQTT's Topic matching logic. Specifically, when an MQTT Pub message is received, how can we find all the subscription records matching the message's Topic through the read operation of KV storage? This process can be transformed into a mathematical Set problem: finding the intersection of the set formed by the Topic's ExpansionSet and the set of TopicFilters from the actual subscriptions in the current system. This is easily achievable!

As shown in the figure, the left side displays the lexigraphical order ExpansionSet for the topic "a/b/c", while the right side shows the current subscription relationships in the system, presented in an ordered KV storage format.
The core workflow of the matching algorithm involves sequentially scanning the subscription relationship KV on the right from top to bottom, and locating the position of the currently subscribed TopicFilter in the ExpansionSet on the left. If the TopicFilter exists in the left ExpansionSet, a match is considered found. If it does not exist, and assuming the next possible matching TopicFilter in the left ExpansionSet is T, the algorithm can skip all parts in the right-side ordered KV of subscription relationships that have a lexicographical order less than T, and then continue scanning.
This algorithm operates unidirectionally on both the left and right sets, so the completion of scanning in either set signifies the end of the algorithm.
From the perspective of space complexity, the left ExpansionSet essentially serves as an 'index' and does not need to be actually expanded in memory. It only needs to identify the next possible TopicFilter that might appear in the right set according to the lexicographical order expansion rule, hence the space overhead of the left set can be neglected. The right set represents the actual existing subscription relationships in the current system, with its space complexity being O(N)``, where N` is the number of subscriptions.
The time complexity of the algorithm is related to the number of actual subscription relationships, with an upper limit of approximately O(N*log(X))``, where X` is the number of levels in the Topic. Of course, the worst-case scenario occurs when the right set includes every possible subscription for all Topics.
Since the algorithm only requires a single efficient scan of the subscription relationship KV storage data during execution, we have named this approach 'OnePass'.
The Dist Service
Dist Service (bifromq-dist) is a key sub-service within BifroMQ for handling subscriptions and message routing distribution, with the 'OnePass' scheme forming the core of its sub-service architecture.
Dist Service comprises two server modules: DistServer and DistWorker. DistServer is a stateless RPC service module responsible for handling request scheduling; whereas DistWorker is a stateful module, incorporating a KV storage engine (base-kv), within which distributed storage of subscriptions data is implemented.
To reduce the latency costs associated with internal communication during message routing and distribution, Dist Service is designed to tightly couple data with computation. The term 'data' here has a dual meaning: it refers both to the MQTT Pub messages themselves and to subscriptions data. 'Computation,' on the other hand, pertains to the subscription matching and message distribution process. Dist Worker encapsulates the topic matching and distribution process of messages into the base-kv's Range CoProcessor, ensuring that the matching and distribution processes occur locally where the subscription information is stored. Such a design effectively prevents additional data transmission from impacting the latency of messages within the BifroMQ system.

The above figure demonstrates the role played by DistService in handling MQTT Pub/Sub. To enhance the efficiency of subscription matching, Dist Worker has further optimized the 'OnePass' scheme, notably through the introduction of a caching mechanism. Under this mechanism, for messages continuously published under the same Topic, only a single execution of the 'OnePass' algorithm process is required. The results of the matching are cached for use in subsequent similar requests. This introduction of caching not only speeds up processing but also reduces the overhead of repeated computations and local IO. It is important to note, however, that the invalidation and update strategies associated with caching are complex and fall beyond the scope of this discussion, thus they are not elaborated in detail in this article.
Conclusion
Topic subscription matching is a core feature of the MQTT protocol, and its flexibility is a key factor in MQTT's widespread application. However, the implementation solutions accumulated over the years by the community and industry have shown certain limitations in dealing with Multi-Tenant Serverless service scenarios. BifroMQ's 'OnePass' scheme, based on First Principle and starting from an architectural perspective, is an attempt to address this issue. We hope this approach can bring new inspiration to the community and drive the development and innovation of technology.