BifroMQ: Unveiling the Technology for Building Efficient and Available Clusters


Introduction
The cluster version of BifroMQ has been launched in the community lately, meeting the core demands of users for horizontal scaling and high availability in cluster deployment. We have previously detailed the capabilities of BifroMQ StandardCluster in terms of performance scaling. In this article, we will focus on a deep analysis of the technical features adopted by BifroMQ to ensure high availability.
Decentralized Clusters
In the architecture of BifroMQ, we have meticulously designed a scheme for partitioning the MQTT protocol workload. This strategy allows each type of workload to operate in its own independent sub-cluster. These functional sub-clusters are all built upon a sophisticated decentralized base-cluster framework. The cluster framework of BifroMQ consists of two logical layers: the Underlay Cluster and the Overlay Cluster. Such a construction makes the architecture clear and decoupled. For more details about this design, please refer to the 'BifroMQ Technical Architecture Overview'.
Underlay Cluster
The Underlay Cluster is the core of the BifroMQ cluster system, with its members representing a running BifroMQ process, and members can communicate directly using the host network address bound to the process. We adopt a Gossip-based Membership protocol (SWIM Protocol) for cluster member failure detection, and have further optimized the synchronization mechanism for Membership information, providing the following technical characteristics:
- Cluster construction does not depend on traditional registration centers or naming services, effectively eliminating the operational risks of single points of failure, significantly enhancing the cluster's high availability.
- Using the SWIM protocol, the Underlay Cluster ensures the accuracy of node probing mechanisms between nodes, maintaining the final consistency of the cluster topology.
- Using CRDT technology to synchronize Membership information between nodes, achieving extremely low bandwidth usage and timely synchronization.
Cluster Construction Process
In a decentralized cluster architecture, each cluster member has an equal status, with no special node designated to manage cluster topology information. From a higher perspective, any node running the BifroMQ StandardCluster service process can be seen as an independent cluster with a "single node." Thus, the construction of the cluster is essentially the fusion of these independent clusters. To facilitate this process, the base-cluster framework provides a "join" operation for the effective merging of these independent clusters.
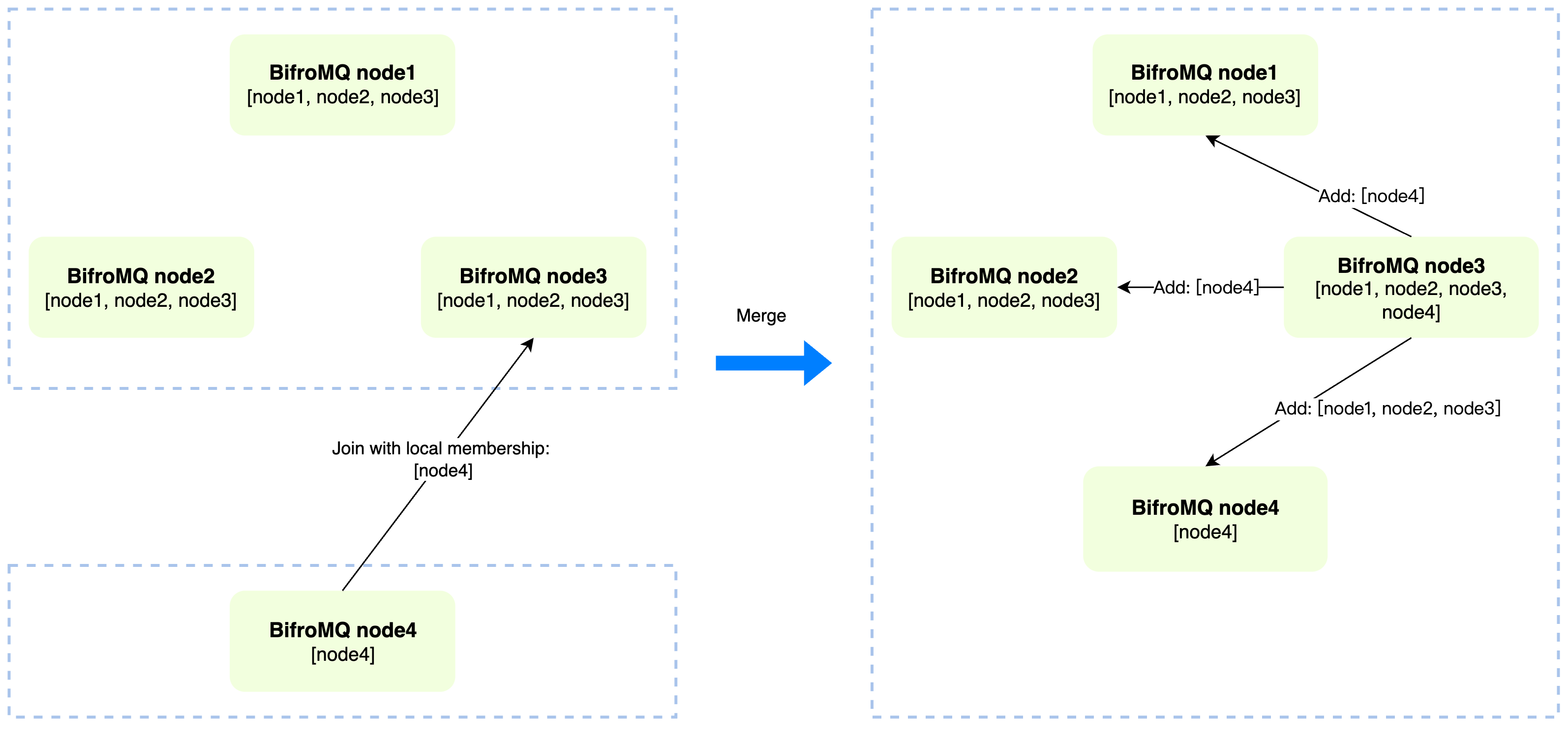
As shown in the illustration above, the join operation of a cluster can be initiated by any node to any node in the target cluster. For simplicity, we refer to the nodes targeted in the join operation as "seeds." In a typical deployment process, the addresses of these seed nodes are usually configured in the configuration file (seedEndpoints) of the new nodes joining the cluster. After the successful merging of the clusters, each node in the BifroMQ cluster can obtain complete cluster Membership information locally.
Attentive readers may have noticed that directly specifying seed addresses in node configuration may have certain limitations in a containerized environment. To address this issue, the base-cluster framework has built-in DNS resolution functionality. In container environments, we can simplify the cluster deployment process by including all nodes in a fixed network Domain (such as External DNS or Kubernetes Service). Thus, new nodes can use any Remote address resolved from this Domain as the seed to complete the join process.

FailureDetection and Auto-Eviction
In BifroMQ, when a node exits normally, it actively clears its registered identity in the cluster and synchronizes this change with other nodes in the cluster. Additionally, each node continuously performs failure detection of other nodes. Once anomalies are detected, the node immediately removes the relevant information of that node from its local cluster Membership and quickly completes the synchronization of Membership information across the cluster, preventing these inactive nodes from affecting the normal function of the cluster.
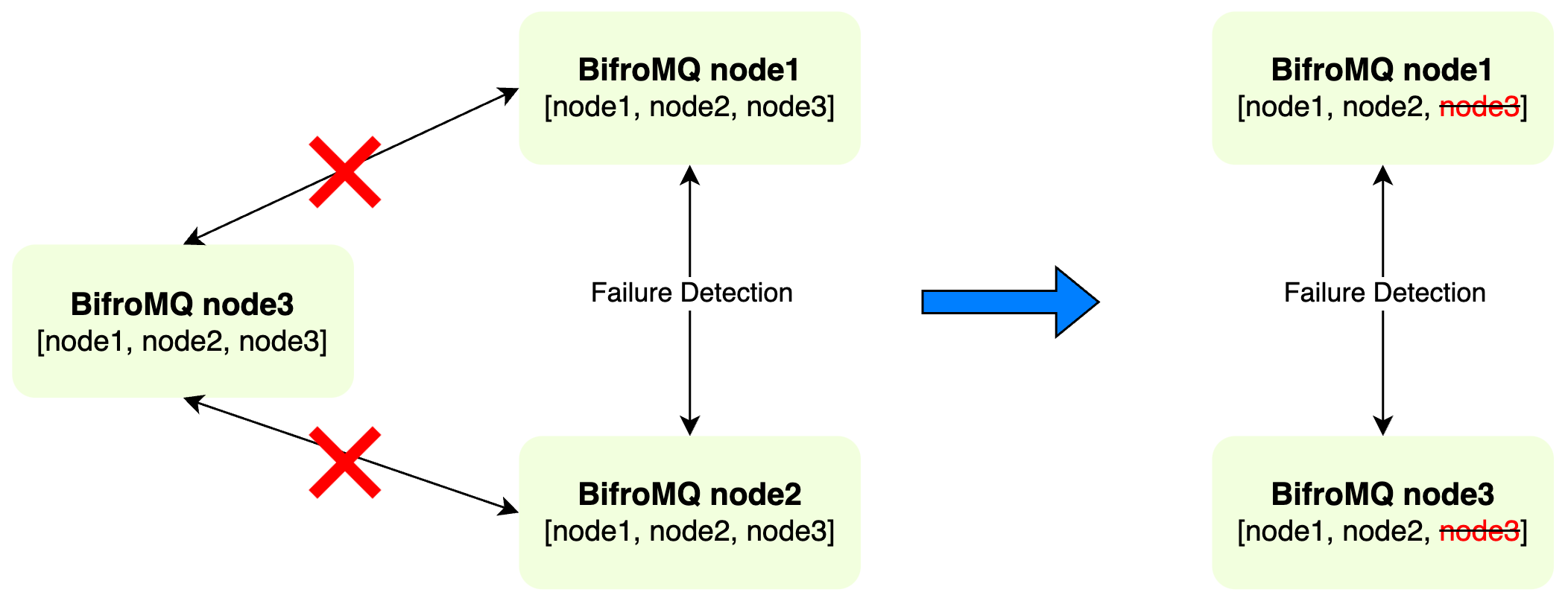
In conjunction with the automatic eviction mechanism, BifroMQ also has a built-in self-healing mechanism which effectively prevents the erroneous removal of registration information of healthy nodes due to network jitters or misjudgments: each node re-examines its registration information when it observes changes in cluster information. If missing information(about itself) is found, the node will actively supplement it, thus ensuring the integrity and final consistency of cluster information.
Recovery from Split-Brain
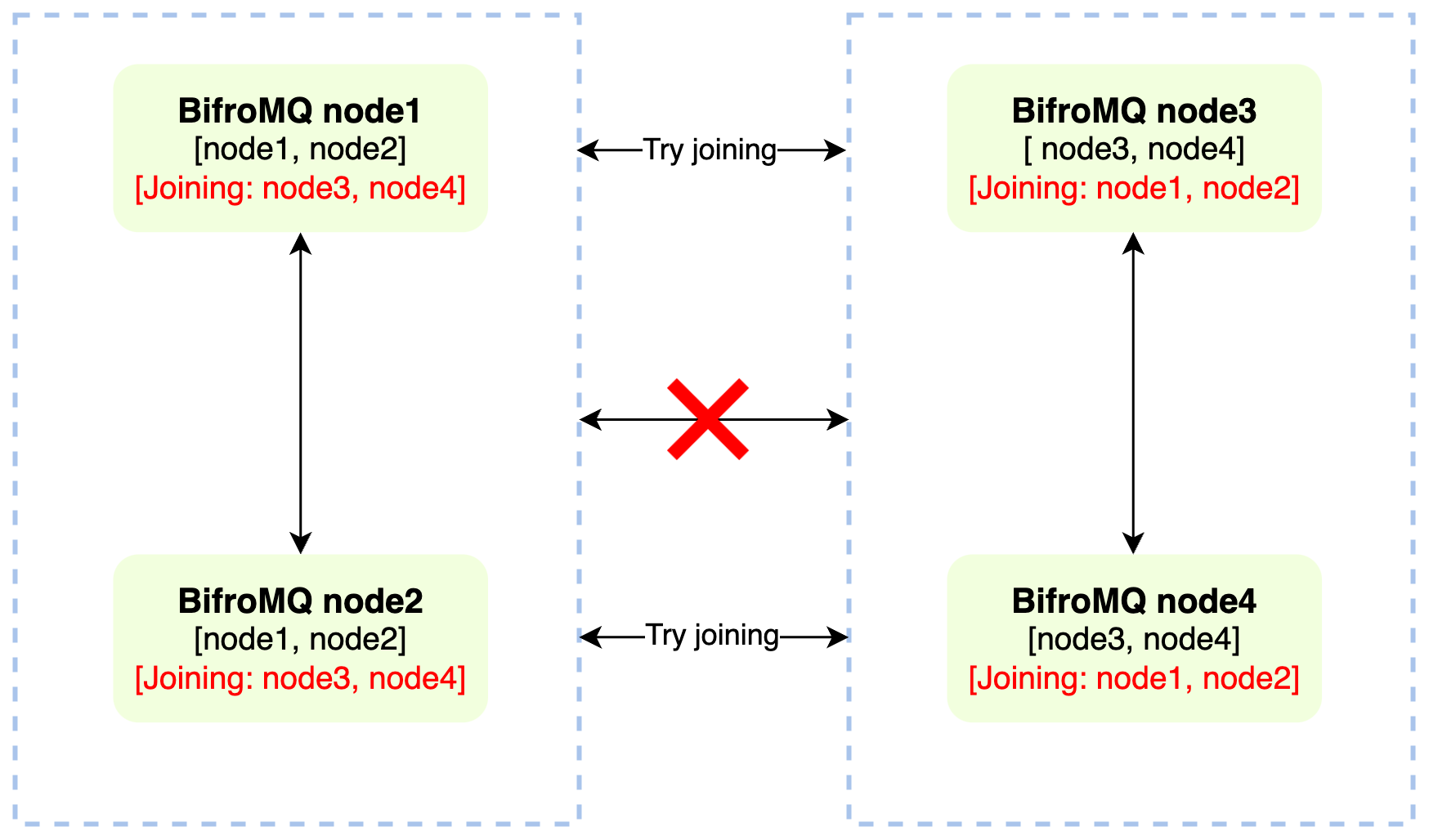
For decentralized cluster services, network partition-induced brain splits, where a single cluster divides into multiple isolated clusters, are an unavoidable issue.
The base-cluster ensures protection against potential brain split failures, further enhancing the high availability of cluster deployment. Here's how it works: When a network partition happens, the isolated cluster segments detect node failures in the other segments. These failed nodes get added to a 'healing list' in their respective segments. The system periodically tries to rejoin these nodes from the list until the time exceeds the MTTR(Mean Time To Repair) set during deployment. Notably, this recovery process from brain splits follows a similar pattern to the initial cluster construction.
Overlay Cluster
The Overlay Cluster, also known as the Agent Cluster, is built on top of the Underlay Cluster. It utilizes the capabilities of the Underlay Cluster for Membership management and inter-member communication, primarily serving as the cluster for specific functional services. Thanks to the efficient construction mechanism of the Underlay Cluster, the Agent Cluster can automatically form the cluster, significantly simplifying the deployment and operational processes.
In BifroMQ, the functional service clusters implemented by the Agent Cluster can be classified into two categories: stateless clusters mainly comprising RPC services, and stateful clusters typically built on the embedded distributed KV storage engine(base-kv).
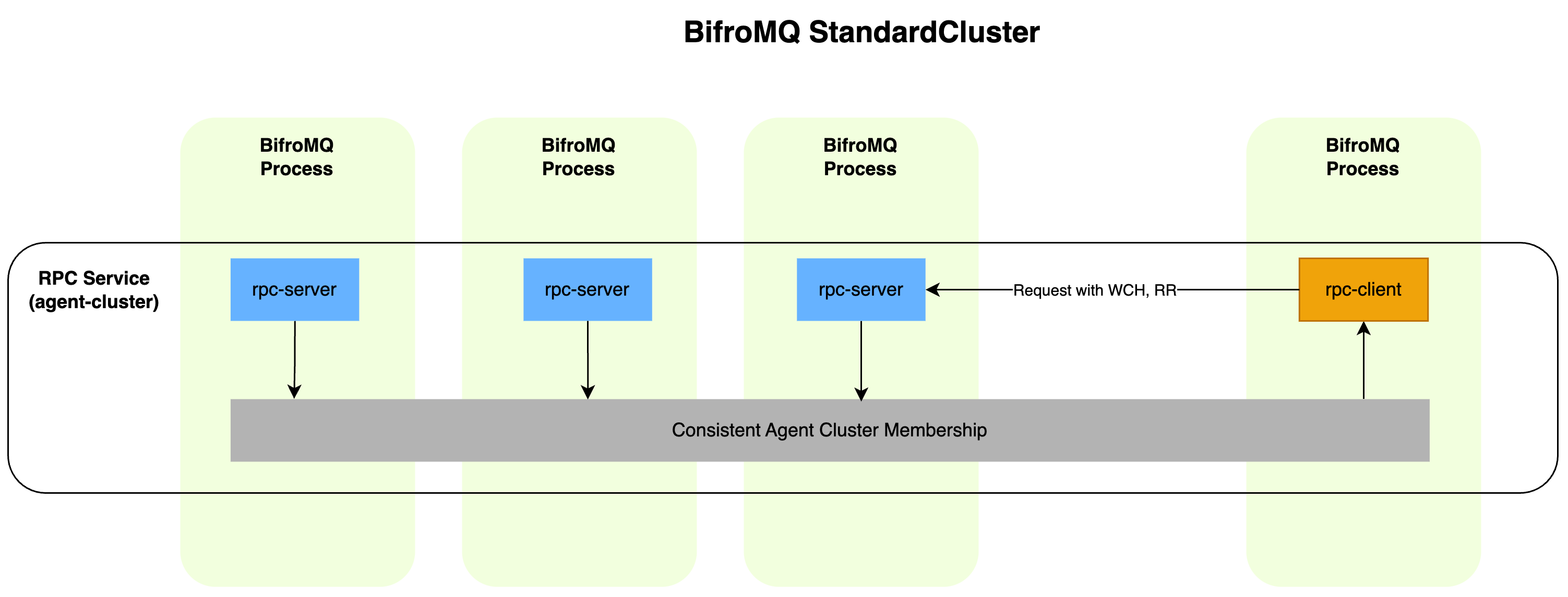
RPC Service Cluster
Members of the RPC service cluster are usually defined as client and server roles. With the features of the Agent Cluster, the client and server of the RPC do not depend on external registration centers, enabling efficient server discovery and flexible client request routing logic.
Stateful Service Cluster and Distributed KV Storage Engine
BifroMQ's stateful service cluster is built on top of the strong consistency distributed KV storage engine--base-kv. This engine features sharding capabilities based on Multi-Raft, making it a key component of BifroMQ's high reliability. The Membership information of the cluster is maintained by the Agent Cluster, while each Range shard within the cluster achieves strong consistency synchronization through the Raft protocol. Therefore, to ensure the high reliability of stateful services, it is essential to fully utilize and comply with the characteristics of the Raft protocol.
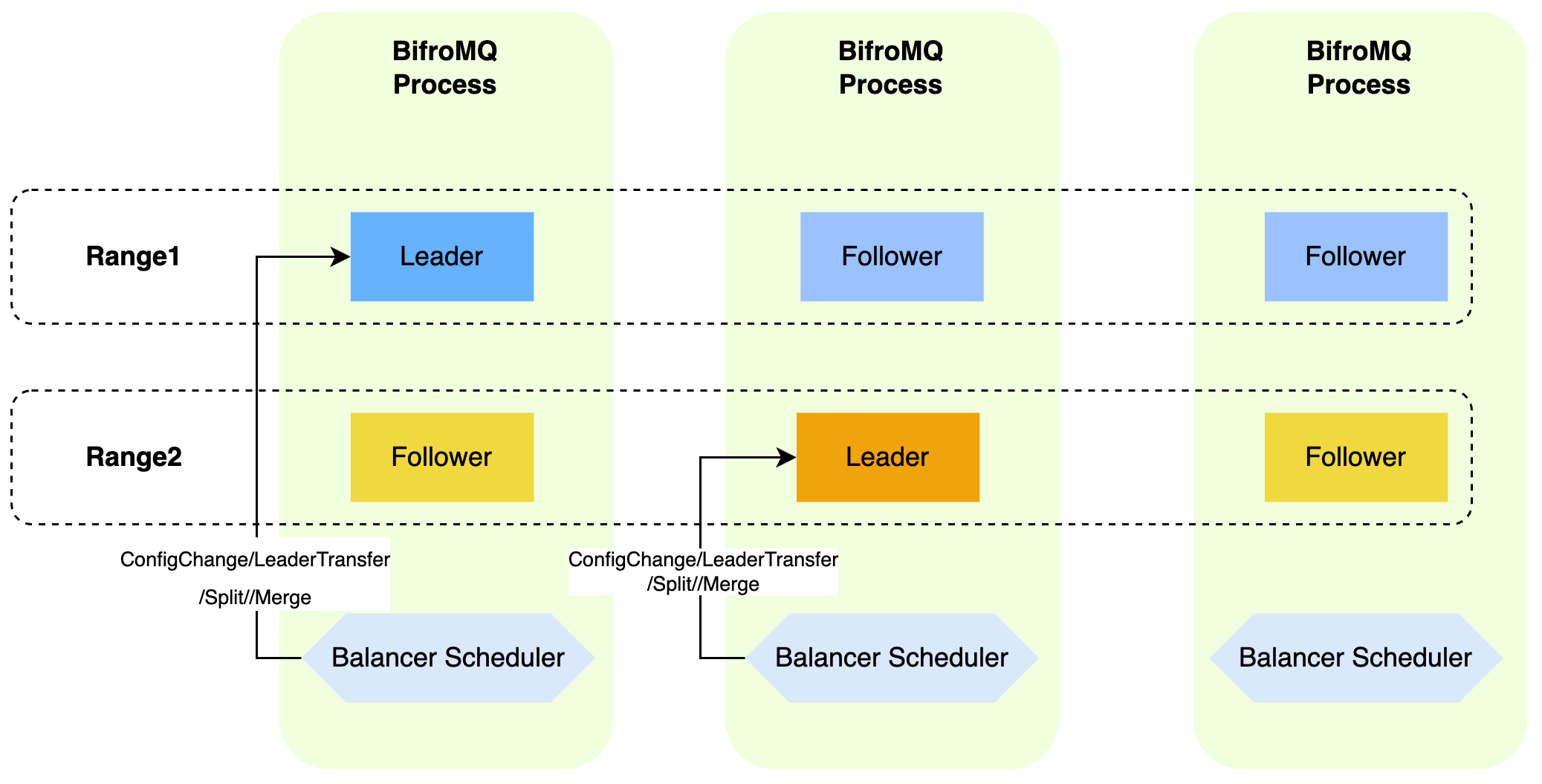
KVRange Balancer
The base-kv uses a built-in Range Balancer framework for efficient management of Range replicas. This framework takes into account the current cluster topology and various real-time load information to generate commands for balancing the Range replica set. These commands include LeaderTransfer, MemberConfigurationChange, RangeSplit, and RangeMerge. Through this series of operations, base-kv can effectively balance the cluster load, optimize throughput, and achieve the goal of high availability. It is worth mentioning that the Range Balancer also adopts a decentralized design principle. In each node of base-kv, the Balancer is only responsible for managing the local Leader Range. This design allows Balancers on multiple nodes to operate in parallel, ultimately achieving a globally consistent balancing goal.
BifroMQ has pre-built a range of common load balancing strategies for out-of-box usage. However, for advanced users with specific needs, BifroMQ also offers the capability to customize load balancing strategies (via Balancer SPI), allowing for optimization according to specific application workload scenarios. Below is a brief introduction to the built-in open-source balancers. Users can activate these strategies as needed through configuration.
ReplicaCntBalancer
The primary function of the ReplicaCntBalancer is to adjust and balance the number of replicas of a Range within a cluster deployment. Once enabled, this feature allows the number of Range replicas to be flexibly adjusted according to the number of deployment nodes in the BifroMQ StandardCluster cluster. This means that the ReplicaCntBalancer can automatically optimize and achieve the best availability configuration according to the current scale of the cluster, to reduce the cluster operation work.
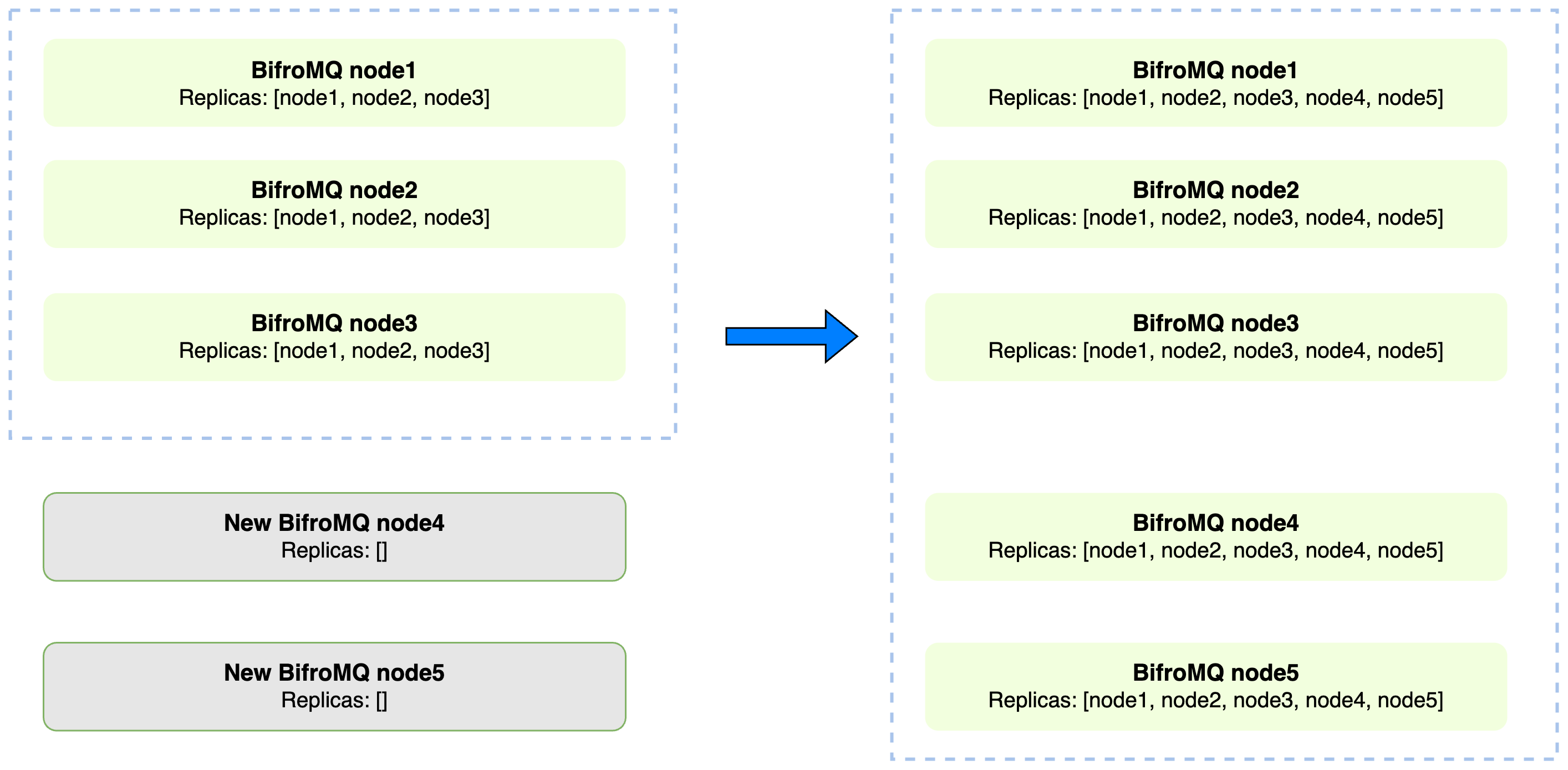
As shown above, the working process is as follows:
- Cluster scale-up: Suppose initially there are 3 nodes in the BifroMQ cluster, and the number of Range replicas is also 3, allowing the cluster to tolerate the failure of 1 node. When 2 more nodes are added to the cluster, the ReplicaCntBalancer automatically incorporates these new nodes into the replica configuration, and after data synchronization, the number of replicas increases to 5. This allows the cluster to tolerate the unavailability of 2 nodes, thus enhancing the cluster's fault tolerance.
- Cluster scale-down: In another scenario, when the BifroMQ cluster contains 5 nodes and the number of Range replicas is also 5, if two nodes crash, the cluster can still operate normally according to the Raft algorithm. However, if the replica configuration remains unchanged, another node's crash will cause the entire Raft cluster to become inoperable. At this point, the ReplicaCntBalancer will adjust the replica configuration to include only the remaining 3 available nodes. This adjustment ensures that the cluster remains highly available even if one more node becomes unavailable.
RangeSplitBalancer
In BifroMQ, each Range's replica set is managed through the Raft protocol, and its load capacity is limited by the WAL replication mechanism, thus having a certain performance ceiling. Especially when application workloads are highly concentrated on a single Range, this limitation becomes particularly apparent. In such cases, splitting a Range into multiple parts is an effective way to enhance the system's parallel task handling capability, thereby improving the overall system performance.
The RangeSplitBalancer is the built-in load balancing strategy in base-kv that implements this functionality. It analyzes the actual application workload and timely generates Range splitting instructions, thereby optimizing system processing capacity and enhancing performance.

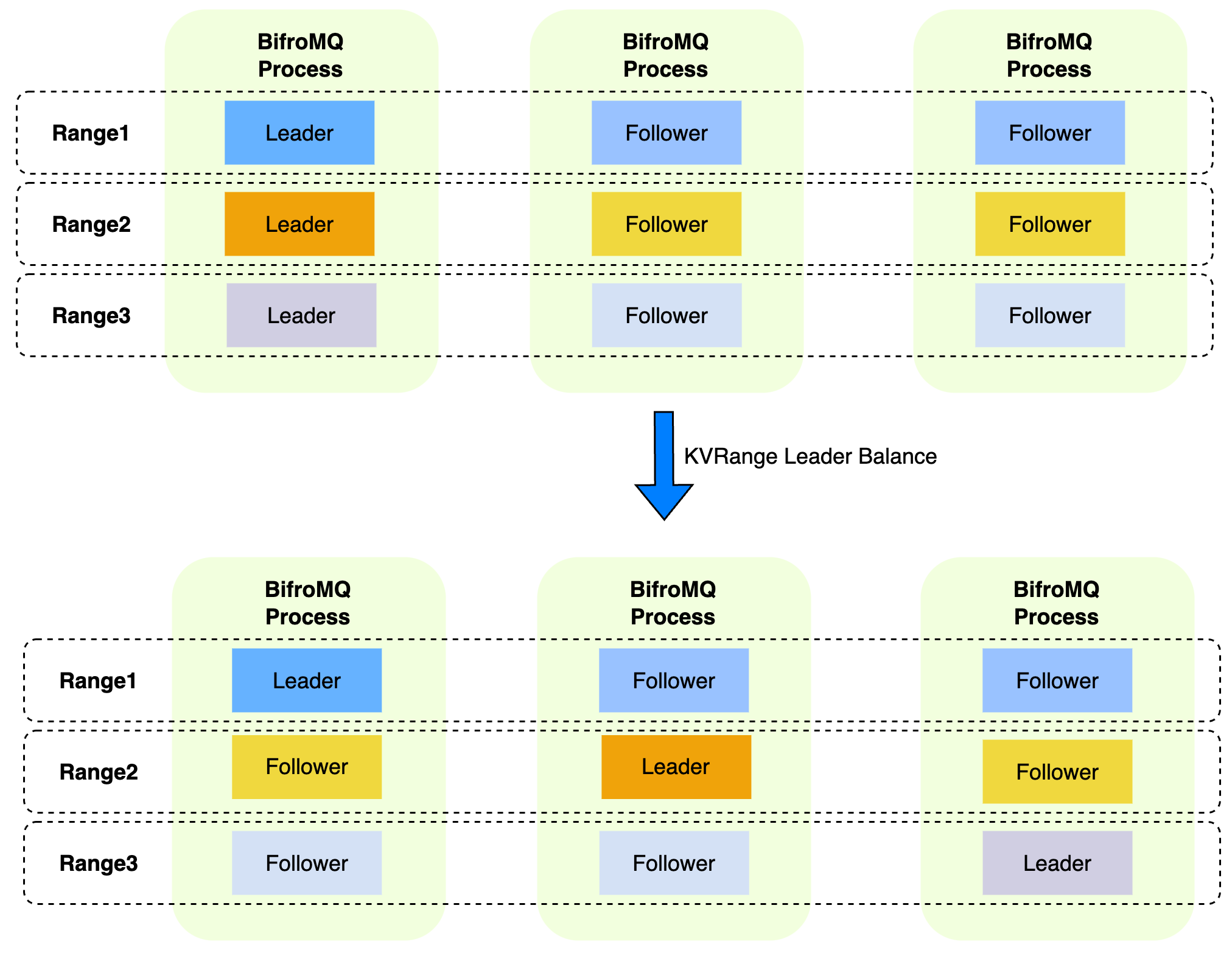
RangeLeaderBalancer
In the Raft protocol, the Leader node handles all write requests and some read requests. Therefore, when the Leader replicas of multiple Ranges are concentrated on the same node, it can easily create load hotspots, affecting system performance. To address this issue, the base-kv cluster can activate the RangeLeaderBalancer in situations where multiple Ranges are splitting.
The RangeLeaderBalancer is specifically responsible for monitoring and adjusting the distribution of Range leader replicas across nodes. It achieves balance by migrating Ranges between nodes, ensuring an even distribution of Leader replicas on each base-kv node.
RecoveryBalancer
In non-Byzantine fault-tolerant strong consistency protocols, the number of functioning nodes n must satisfy the condition n ≥ 2f+1, where f represents the number of fail-tolerant nodes. Based on this principle, any Range replica must be located in more than half of the normal cluster nodes to ensure proper operation. However, in actual deployment, when there are many Ranges in the cluster and a single base-kv node may carry replicas of multiple different Ranges, simultaneous failures of multiple cluster nodes could lead to a situation where n < 2f+1, known as Lost Majority. In the event of Lost Majority, the affected Ranges will be unable to operate normally.
To deal with this situation, the RecoveryBalancer provides a opt-in capability. It allows nodes to detect if they are in a Lost Majority state and, if necessary, actively reduce the replica list configuration to ensure that at least half of the nodes are alive, thus enabling the Range to continue functioning. However, it is important to note that the recovery process is beyond the scope of Raft protocol when using RecoveryBalancer to automatically recover Ranges in a Lost Majority state, if the originally failed nodes rejoin the cluster without manual intervention, it may lead to data loss and inconsistency issues. In such cases, users need to carefully consider and combine actual operational strategies to decide whether to enable the RecoveryBalancer in their deployment.

Stateful Functional Services
BifroMQ's stateful sub-services come in three types: MQTT subscription routing, offline message queues, and retain message storage. These are implemented by corresponding modules: dist-worker, inbox-store, and retain-store, respectively. Each module, once deployed, forms an independent base-kv cluster.
To adapt to various workload demands, BifroMQ allows each independent cluster to select and initiate suitable Balancer strategies based on its specific conditions. This flexible configuration of strategies ensures that each cluster maintains high availability while achieving optimal data processing and throughput performance.
dist-worker
In BifroMQ's architecture, the dist-worker module is responsible for managing subscription information (Sub) and message distribution (Pub). In normal use cases, this is typically a scenario dominated by read operations with fewer write operations.
Considering this workload pattern, the dist-worker adopts the following default Balancer strategies:
- Enabling dynamic replica count: This strategy ensures that the number of KVRange replicas is consistent with the number of cluster nodes, maximizing query throughput efficiency.
- Limiting voter replica count: While ensuring high availability, the number of Raft Voters is limited to a maximum of three. Other replicas serve as Learners, reducing the response latency of write operations.
In most common use cases, the number of subscribers that a Publish message matches is usually not large, and the matching process is relatively fast. Given this, the dist-worker module does not activate the Range splitting strategy in its default configuration.
However, in scenarios where messages require large-scale Fanout, especially when low latency is also a requirement, the query efficiency of a single Range could become a bottleneck for overall performance. To address these challenges, we plan to enhance this aspect of processing capability in future versions of BifroMQ to optimize performance in handling message fanout to large scale subscribers.
retain-store
Normally retain-store has similar workload characteristic as dist-worker, so the default Balancer strategy same and will not be reiterated here.
inbox-store
In BifroMQ, the inbox-store module takes on the role of managing offline messages for each connection with cleanSession=false. For these connections, inbox-store creates a dedicated persistent offline message queue. Subscribed messages are first written into this queue. When the connection goes back online, messages are pulled from the queue for delivery and subsequently deleted. This is a typical scenario with frequent read and write, where the workload is mainly concentrated on the Leader replica, and the IO latency of storage significantly impacts system message throughput.
Considering this kind of workload pattern, the default Balancer strategies for the inbox-store are as follows:
- Limiting the Voter to 1 by default: As a higher number of replicas can lead to increased write response latency, the default setting limits the number of Range replicas to 1. This prioritizes rapid message processing but comes with some reliability trade-offs. Users can adjust the number of replicas based on their needs.
- Enabling range split and leader balancing: This strategy allows the inbox-store to dynamically shard and expand as the workload gradually increases, ultimately achieving a more balanced load distribution.
Notes on BifroMQ StandardCluster Deployment
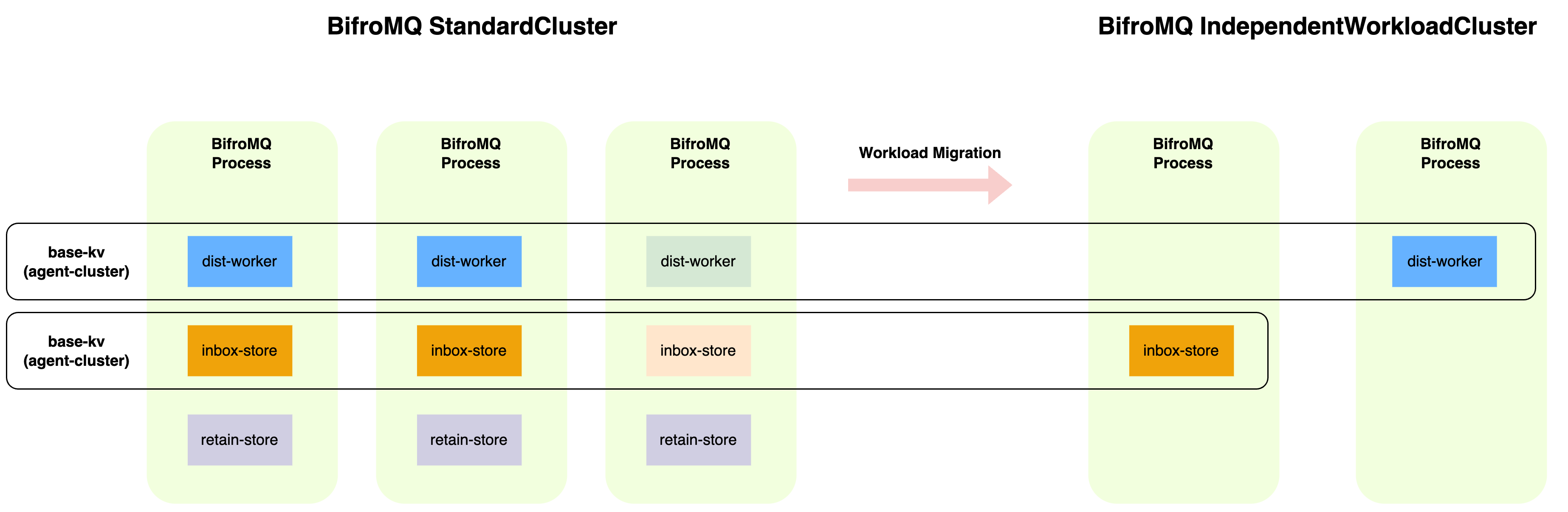
BifroMQ StandardCluster adopts a deployment strategy that integrates all functional modules into a single process. This strategy simplifies the configuration and deployment process, similar to the 'SharedNothing' cluster architecture commonly used in the industry. However, because multiple modules share the same system resources allocated for one process, this limits the ability to "fine-tune" the allocation based on actual application needs. All modules need to be scaled up or down uniformly, which may not be suitable for cloud scenarios, where different types of workload fluctuations are time-related and require more detailed and flexible resource management.
From BifroMQ StandardCluster To IndependentWorkload Cluster
The unique architectural design of BifroMQ enables it to easily implement a deployment mode of 'independent process per module', which we call the IndependentWorkload Cluster (to be introduced in future versions). This mode not only offers greater flexibility and more precise resource management capabilities, but it also helps users to gradually transition from the StandardCluster mode to the IndependentWorkload Cluster mode in line with the development of business. Such a progressive deployment change can optimize resource allocation and respond to fluctuations in business demands while maintaining business continuity.
Conclusion
The above content provides a comprehensive introduction to the high-availability technology of BifroMQ. BifroMQ ensures the overall high availability of its clusters through the implementation of various mechanisms. Please look forward to a series of upcoming specialized articles where we will delve deeper into the various components of BifroMQ and their design principles, offering you more in-depth technical insights.