测试报告
测试目的
BifroMQ Standard模式开始支持集群部署,集群在不同使用场景及配置下的性能表现差异性较大。
本报告目的是为了给出BifroMQ在标准集群模式部署下,各常见使用场景的性能指标及结果分析,为使用者提供集群部署、规格评估、参数配置等方面的参考。
测试环境
发压工具
基于vertx-mqtt开发的测试工具,具有较灵活的使用方式及优良的性能表现,后续会一并开源。
部署机规格
BifroMQ部署机:CentOS release 7.6, 32核, 128G内存(实际配置JVM内存40G) 发压机:CentOS release 7.6, 16核, 128G内存(实际配置JVM内存32G)
集群构建配置及步骤
BifroMQ内置了消息路由及持久化消息的存储引擎,�属于有状态服务,因此初次构建集群时需要按照一定的顺序进行。
下面以三节点部署为例进行介绍。
node1: 192.168.0.11
node2: 192.168.0.12
Node3: 192.168.0.13
修改conf文件夹下的standalone.yml
node1最简配置:
bootstrap: true
mqttServerConfig:
tcpListener:
port: 1883
clusterConfig:
env: Test
host:
port: 8899
clusterDomainName:
seedEndpoints: 192.168.0.11:8899,192.168.0.12:8899,192.168.0.13:8899
node2 & node3最简配置:
bootstrap: false
mqttServerConfig:
tcpListener:
port: 1883
clusterConfig:
env: Test
host:
port: 8899
clusterDomainName:
seedEndpoints: 192.168.0.11:8899,192.168.0.12:8899,192.168.0.13:8899
按顺序依次启动node1、node2、node3即可。
注:整个集群生命周期中,仅第一次启动第一个节点时需要将bootstrap置为true,以进行持久化存储元数据的初始化,后续无需再关注此配置及启动顺序。
测试说明
场景介绍
测试维度介绍:
- cleanSession:true | false,对应MQTT协议中连接时的Clean Session标志位,false代表支持离线订阅及消息存储。
- Pub & Sub比例
- 1对1:表示每个pub客户端的消息只由一个sub客户端接收。
- 共享订阅:表示较多个pub客户端的消息,由n个sub客户端共同分享,每个客户端接收 1/n 份消息。
- fan-out订阅:表示一个pub客户端的消息,由较多数量sub客户端接收,类似于广播。
- QoS:0 | 1,pub消息与sub订阅采取同样的消息等级。
- payload大小:每条测试消息的大小,单位byte。
- 单连接消息频率:低频指每个pub连接每秒发送一条消息,高频指每个pub连接每秒发送50 ~ 100条消息。
各个场景的测试由以上维度组合而来。
注:默认单个连接的每秒进出口带宽为512KB/s,超出带宽限制会引起消息的延迟。此限制主要用作系统保护而并非性能瓶颈,可以通过启动时的配置参数进行修改。
cleanSession=true与false
BifroMQ对MQTT协议进行了完整的支持,尤其是保留会话方面。服务端会持久化所有客户端的订阅信息、cleanSession=false的客户端在线及离线时的所有QoS级别的消息,因此对于cleanSession=true和false的连接及消息的处理方式有很大区别。
BifroMQ采取了基于磁盘而非内存的持久化策略,在宕机或重启时不会丢失数据,在集群模式下可以根据需要配置持久化数据的副本数量,进一步的提高数据的高可用性。
基于以上设计,cleanSession=false连接使用时的资源消耗与true相比较重,且在离线后仍会占用一定的系统资源。因此相同部署规格下true和false能达到的性能指标会存在较大的差异,需要根据实际需求情况合理选取。
注:BifroMQ的离线持久化设计是为了保证服务SLA而非作为存储引擎使用,因此需要避免反协议的非常规使用方式。例如在cleanSession=false的模式下,每次连接使用不同的clientId,这样既无法真正利用到离线持久化的能力�,又会造成脏数据给系统带来额外的负载。
持久化消息性能影响因素
BifroMQ在集群化部署时,存储引擎也同样会组成分布式集群,BifroMQ的存储引擎是基于RAFT协议的多副本架构,同时支持多分片。
每个BifroMQ实例内部有三个独立的存储引擎,分别负责订阅信息、cleanSession=false连接消息、retain消息的存储,每个存储引擎可以分别进行配置。其中对于cleanSession=false连接的消息收发来说,分片数及副本数对性能均会有较大的影响。
持久化消息存储引擎的副本数可以通过启动时附带系统变量(inbox_store_replica_voter_count,详见配置手册)进行配置,默认为1。若要保持高可用,副本数需要大于等于3。
注:增加副本数会将写入的数据量放大N倍,因此消耗的系统资源及消息延迟都会随之增大。
存储引擎的多分片是基于Multi-RAFT协议实现的,每个分片及其副本组成一个RAFT复制集群,在未达到系统资源瓶颈之前,适当的增加分片数可以有效的提高存储引擎的写入及查询效率。
持久化消息存储引擎内置了基于负载的自动化分片策略,每个分片会根据当前读写负载及系统的繁忙情况决定是否进行分裂,一般无需额外进行配置。若对BifroMQ代码及分片原理有一定的研究了解,可通过在启动时附带以下系统变量进行调优:
-
inbox_store_io_nanos_limit:存储引擎IO延迟限制,默认30,000纳秒,内部读写延迟超过此值后暂停分裂。
-
inbox_store_max_io_density:存储引擎IO负责情况,若当前分片的实时负载统计超过此限制则开始规划分片。
分片策略采用插件化机制进行加载并配置生效,对于深度使用用户来说,可以自行开发适合自身使用场景的分片策略。
测试报告
参数说明
场景名称由测试用例中各维度参数组合而来,例如30k_30k_qos1_p256_1mps_3n_3v表示:
-
30,000个Pub MQTT client
-
30,000个Sub MQTT client
-
消息及订阅质量使用QoS1
-
单个消息payload大小256 bytes
-
单个Pub client每秒发送1条message至BifroMQ,并转发至Sub client
-
3n表示部署三个BifroMQ节点
-
3v表示持久化引擎中的数据为三副本存储,主要影响cleanSession=false场景
结果分析及说明
-
cleanSession=true高频场景单节点消息总吞吐(pub客户端发送消息与sub客户端接收消息之和)可达40W/s以上,三节点部署消息吞吐可达100W/s以上;低频场景单节点消息吞吐最高可达20W/s以上,三节点部署消息吞吐可达60W/s以上;吞吐量可以随节点数进行水平扩展。 注:低频场景达到预设吞吐值时,需要维持的连接数较多,会消耗更多的服务资源,因此与高频发送场景相比能够达成的吞吐上�限会有所降低。
-
cleanSession=true的共享订阅及fanOut能力可以随着节点数进行水平扩展。
-
cleanSession=false高频场景单节点消息吞吐可达3W/s以上,三节点单副本部署消息吞吐可达9W/s以上;低频场景单节点消息吞吐可达2W/s以上,三节点单副本部署消息吞吐可达6W/s以上;基本达到水平扩展的效果。
-
cleanSession=false在三节点三副本部署的情况下,高频及低频场景消息吞吐均可达3W/s以上,与单节点单副本部署场景类似。原因是三副本部署时会将持久化消息写入的负载放大三倍,因此三节点处理三倍负载与单节点单副本能支撑的性能类似。若要对多副本部署的cleanSession=false消息吞吐能力进行拓展,可根据以上规律进行大致计算,得出合适的节点数及副本数部署集。
-
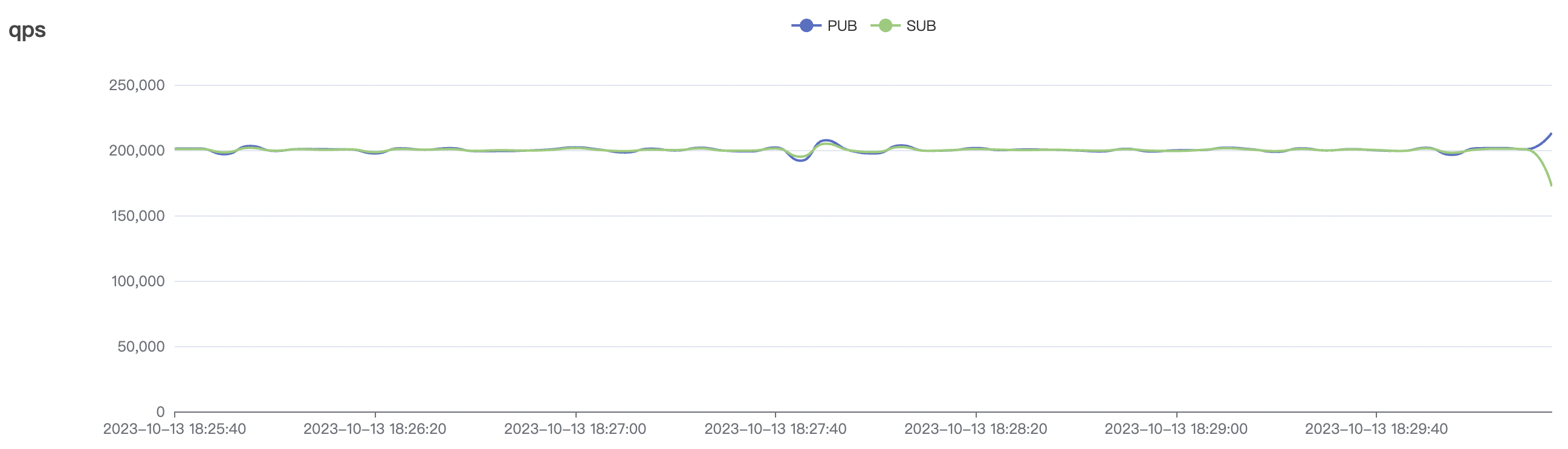
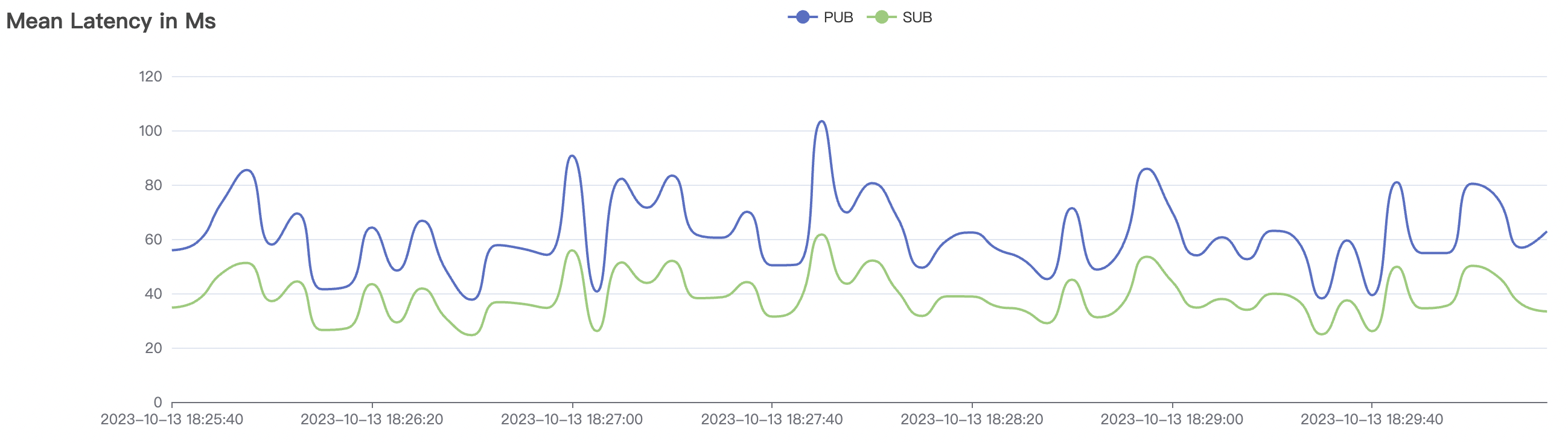
系统吞吐及时延指标会受消息及订阅QoS质量影响,相同的测试载荷下,QoS1场景比QoS0场景消耗更多的系统资源略,消息延迟稍也会有所增加,增加量为毫秒量级,且尽在较高吞吐及系统负载的情况下,才会表现出可观测到的区别。
-
cleanSession=false与cleanSession=true场景的性能结果存在数倍的差距。原因是BifroMQ的架构是为构建serverless云服务而设计的,离线消息的可靠性是云服务SLA的重要指标,因此BifroMQ选择了基于磁盘而非内存的持久化策略,在宕机或重启时不会丢失数据。存储引擎性能受到当前测试机器本地磁盘 IO 性能的限制,采用高性能磁盘替换,或在集群环境下搭配合适的负载策略,都可以有效提升性能。
-
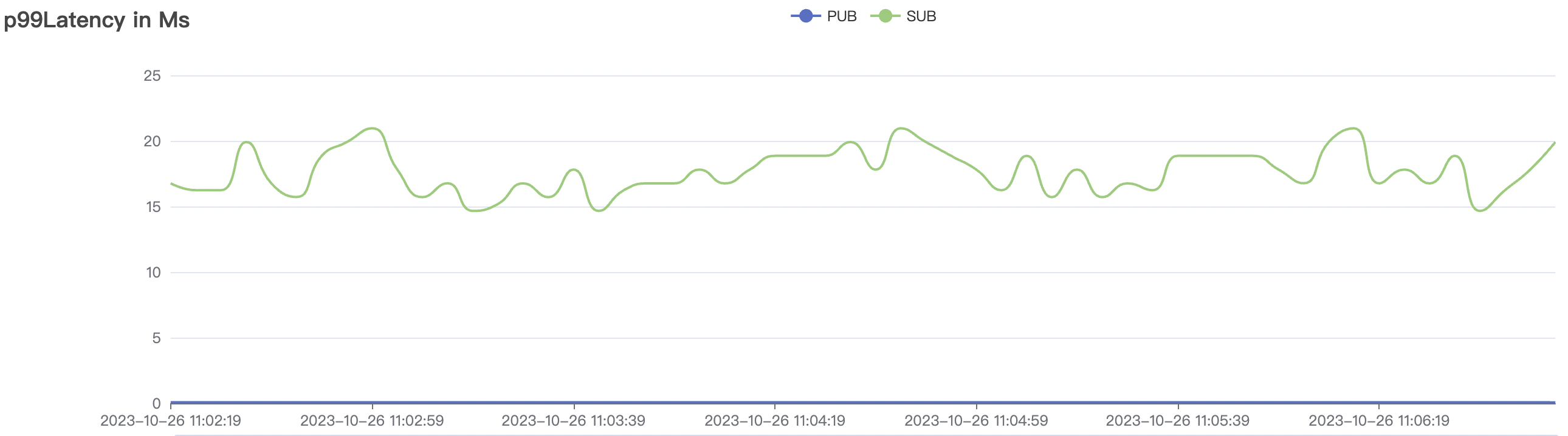
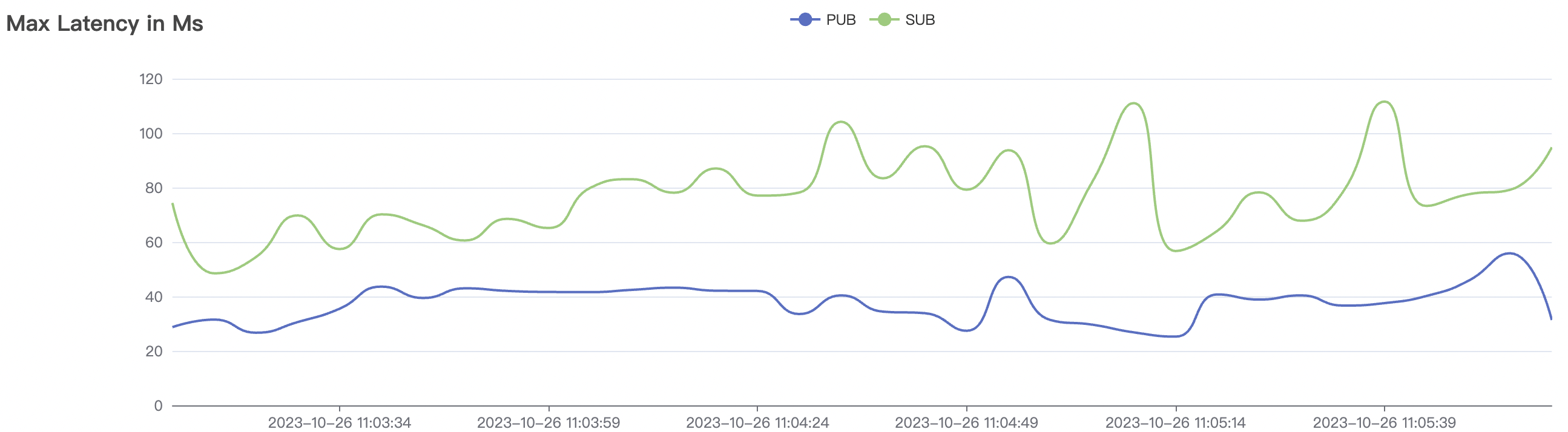
结果附图的p99及max视图中会有偶发的毛刺,与测试发压端的实现有关(Java GC)。
-
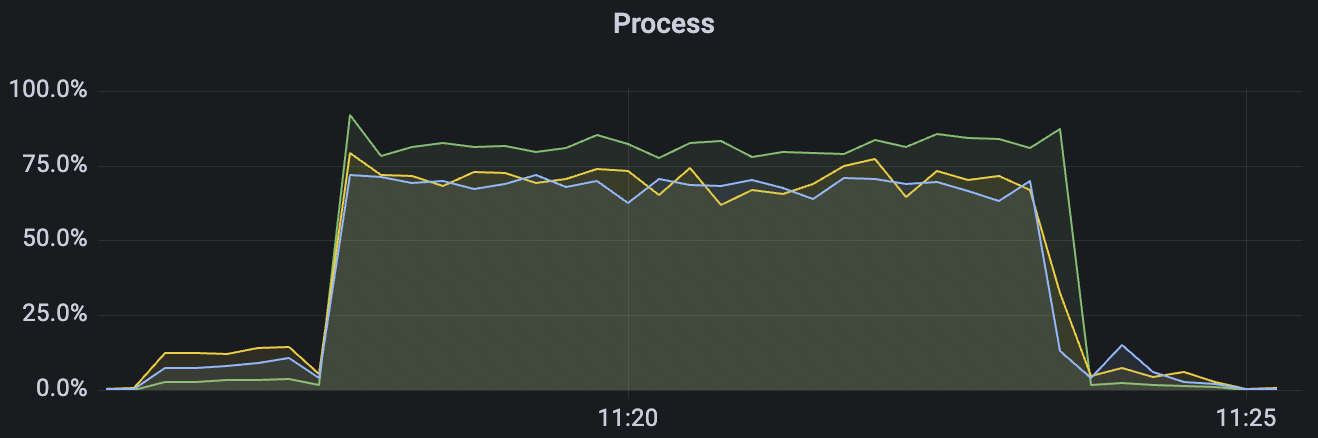
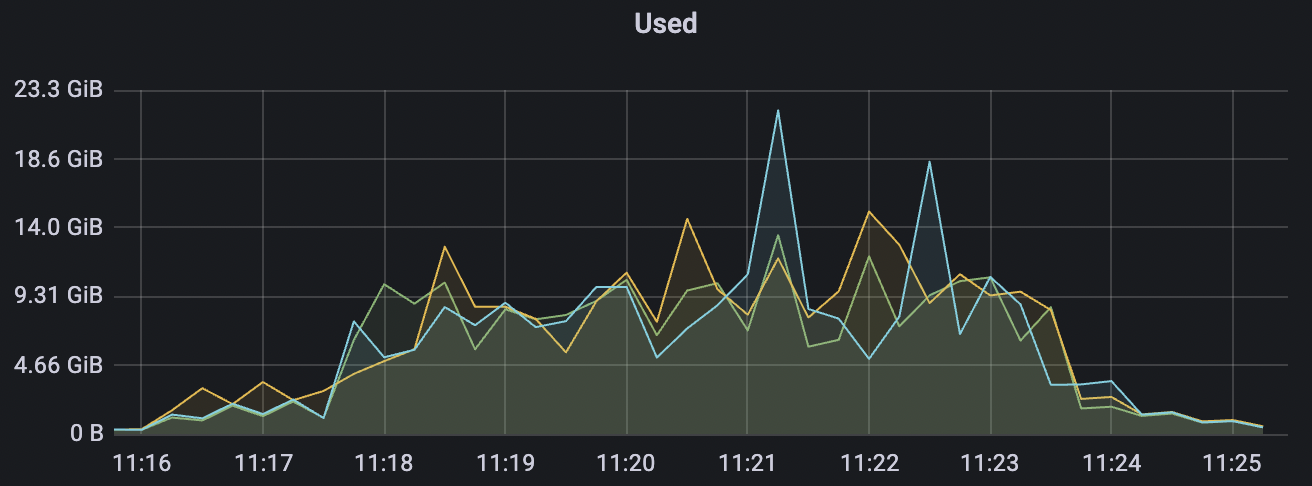
BifroMQ内部消息链路采用全异步实现,能够充分的利用CPU多核的能力。此报告所列测试场景属于压力测试,已经将系统负载使用时较高水平,因此消息时延指标会有所增大,BifroMQ在无压力下的消息时延可以控制在1ms左右。同时在更高可用CPU核数的运行环境中,BifroMQ可以达到比报告中更高的吞吐及时延指标。
cleanSession=true
高频场景
| 场景组合 | QoS | 单连接m/s | 消息byte | 连接数C | 总消息m/s | 平均响应时间ms | P99响应时间ms | CPU | 内存占用GB |
|---|---|---|---|---|---|---|---|---|---|
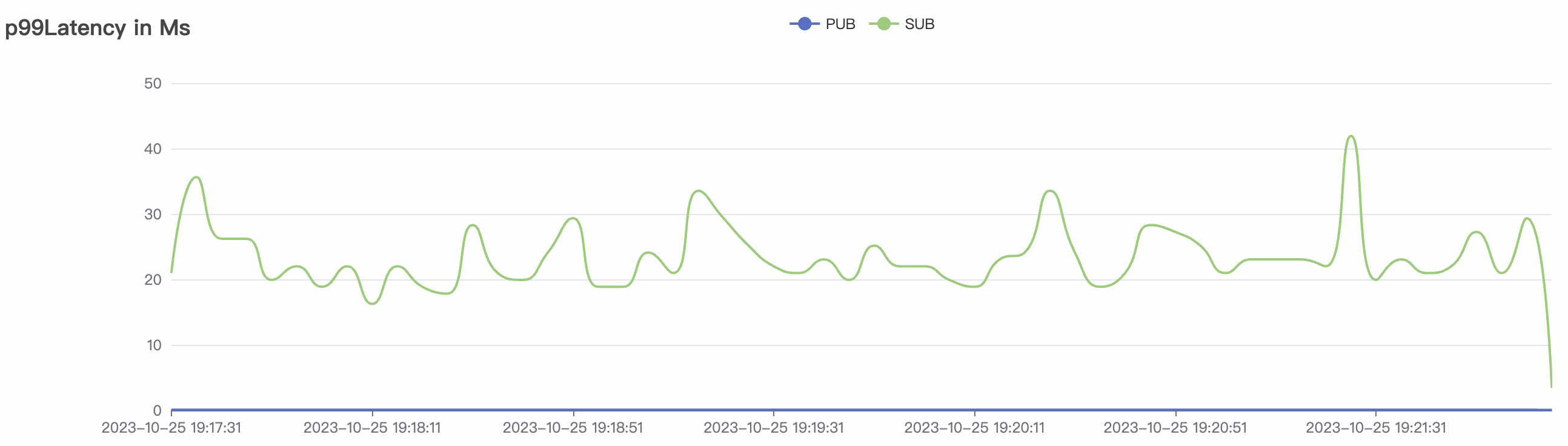
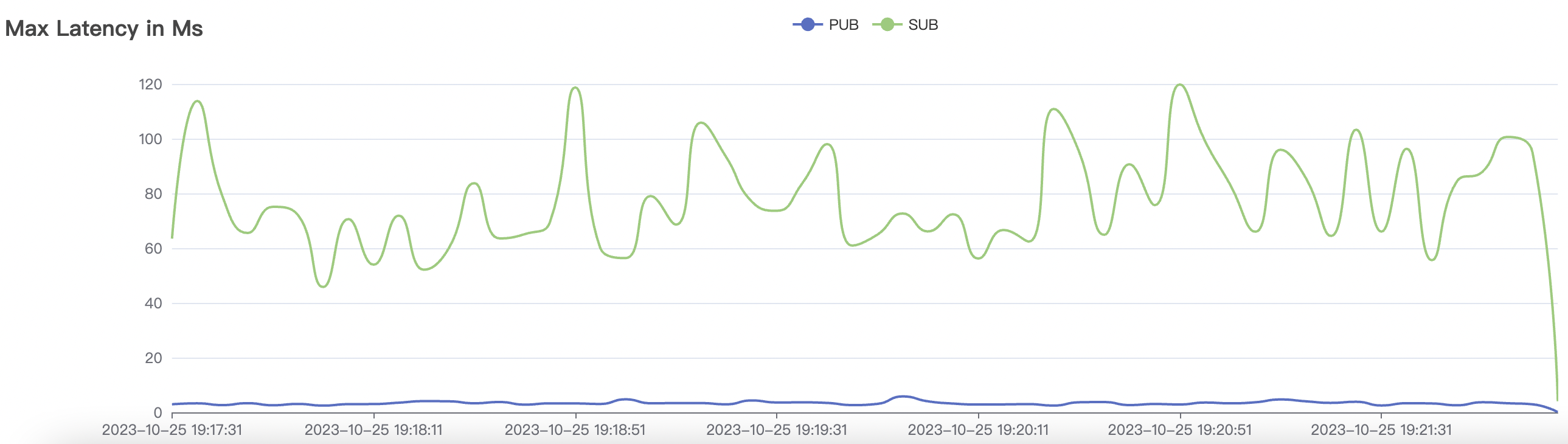
| 2k_2k_qos0_p32_100mps_1n | 0 | 100 | 32 | 4k | 200k | 3.22 | 24.11 | 80% | 5 ~ 10 |
| 2k_2k_qos1_p32_100mps_1n | 1 | 100 | 32 | 4k | 200k | 38.92 | 184.54 | 85% | 5 ~ 15 |
| 5k_5k_qos0_p32_100mps_3n | 0 | 100 | 32 | 10k | 500k | 3.38 | 24.11 | 83% | 5 ~ 20 |
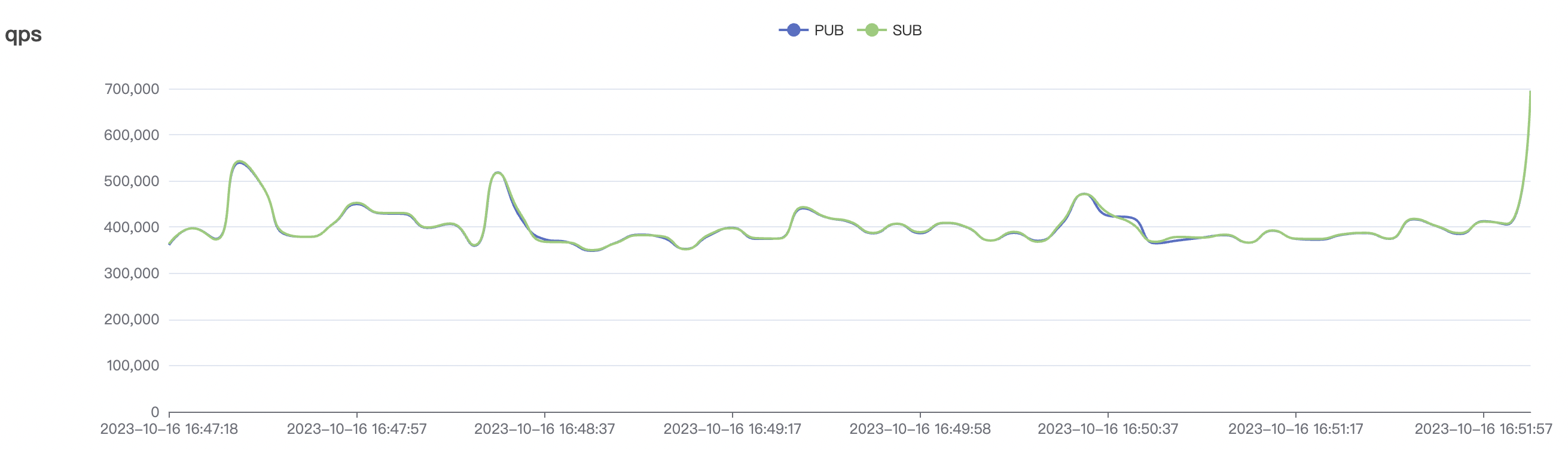
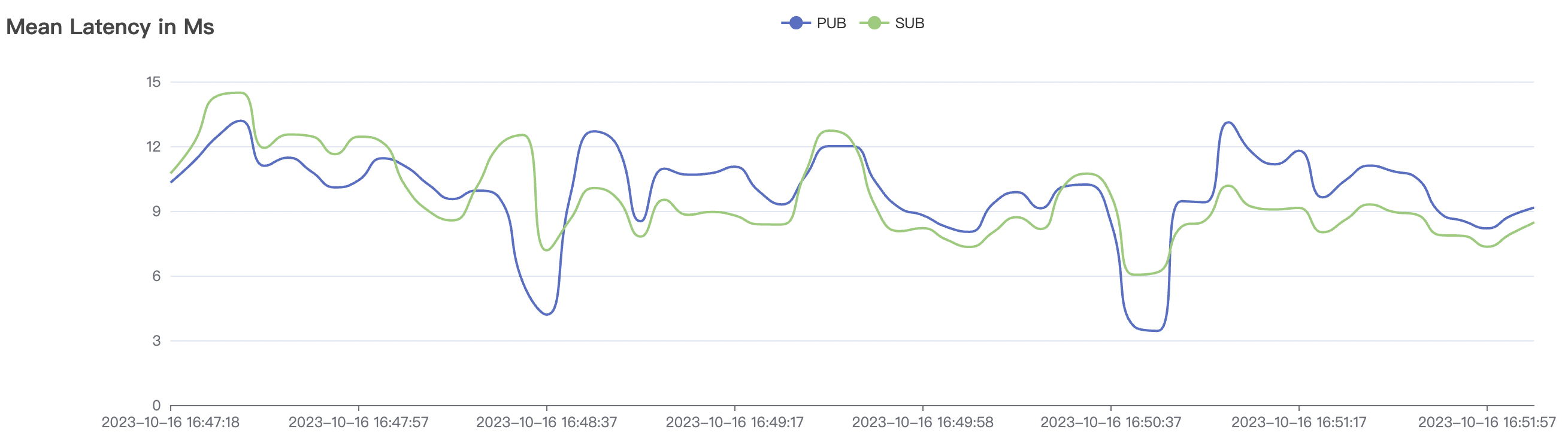
| 4k_4k_qos1_p32_100mps_3n | 1 | 100 | 32 | 8k | 400k | 9.62 | 65.0 | 85% | 5 ~ 18 |
2k_2k_qos0_p32_100mps_1n场景附图:
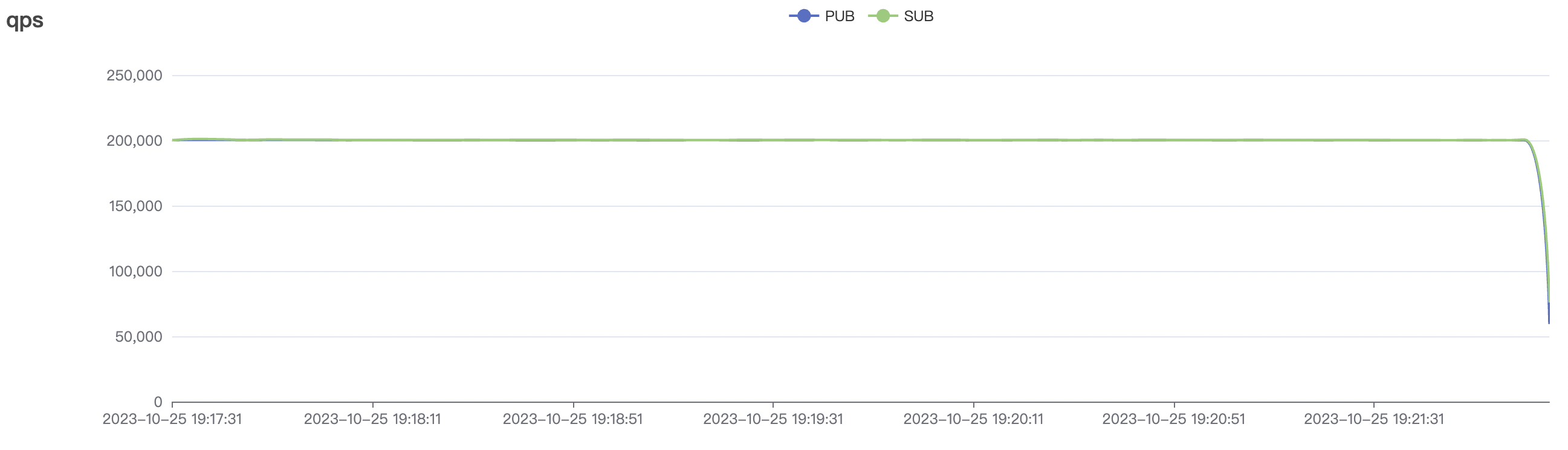 | 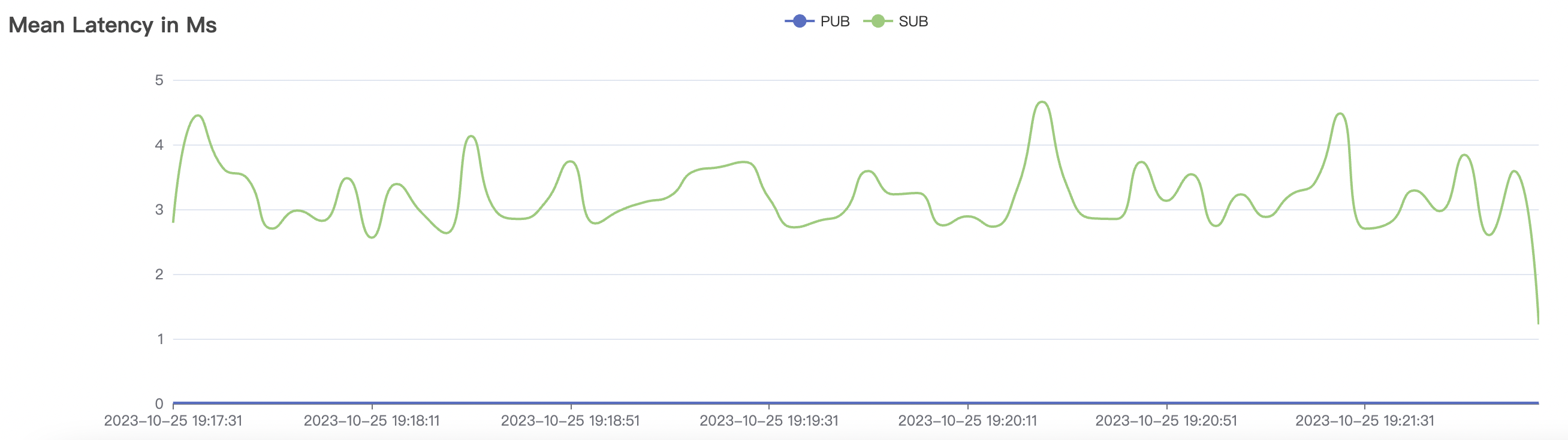 |
|---|---|
 |  |
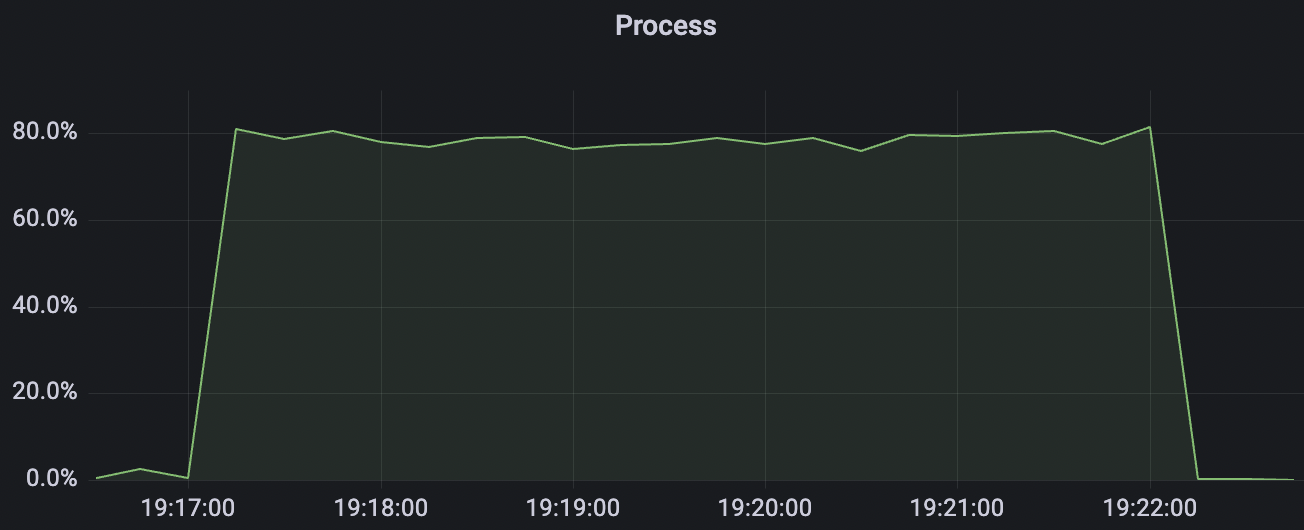 | 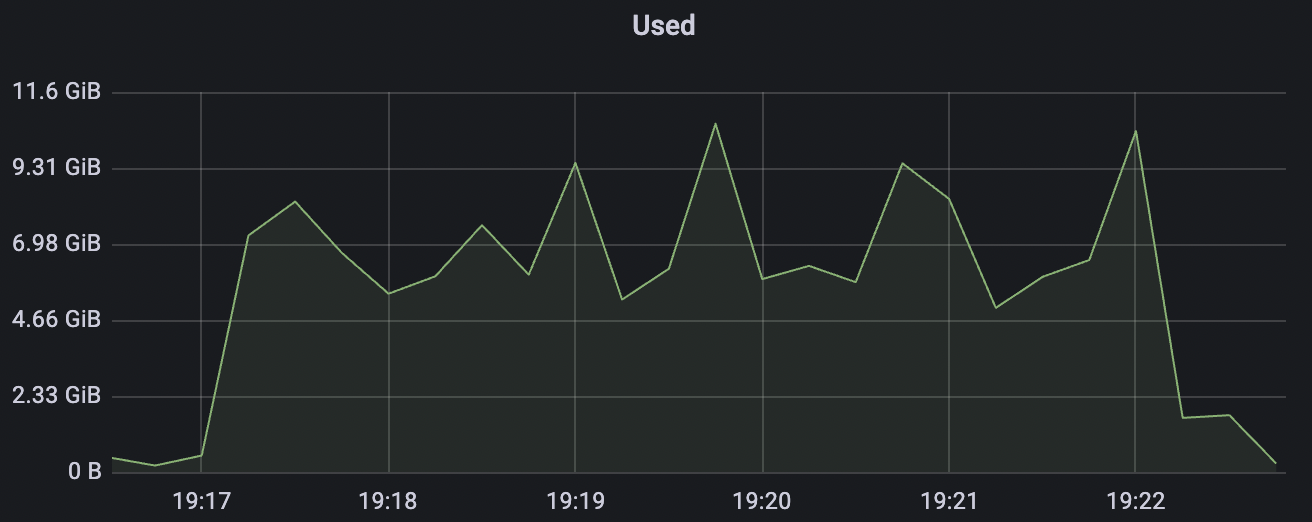 |
2k_2k_qos1_p32_100mps_1n场景附图:
 |  |
|---|---|
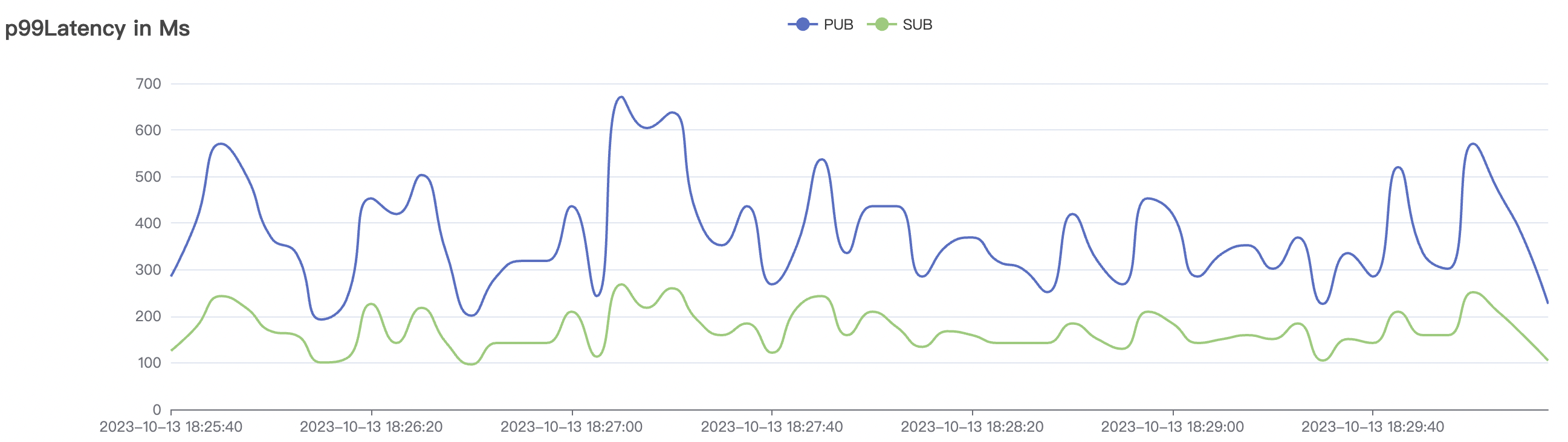 | 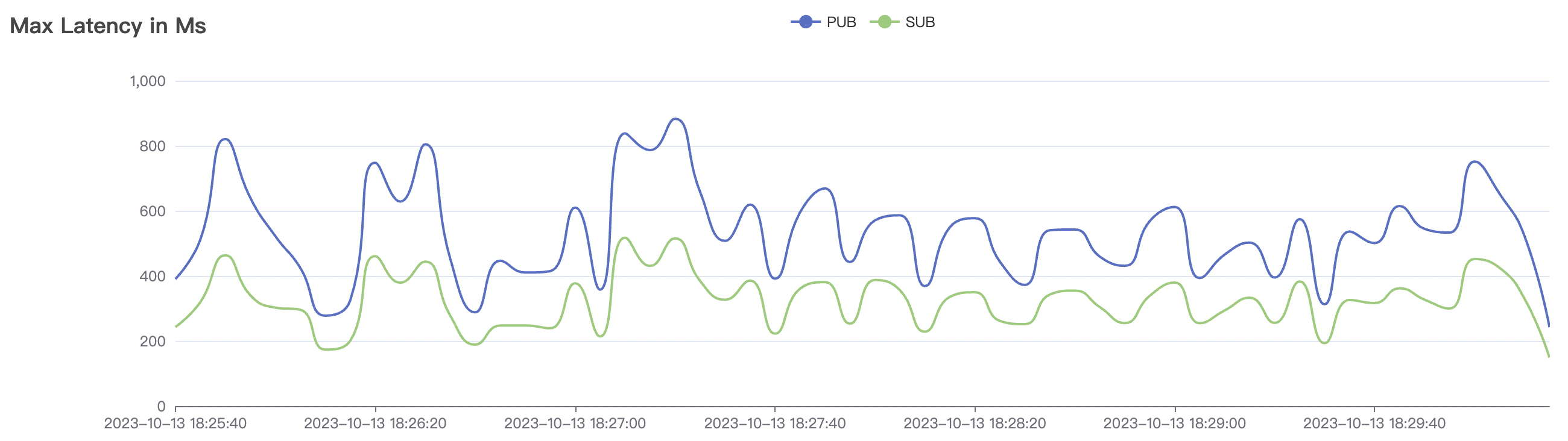 |
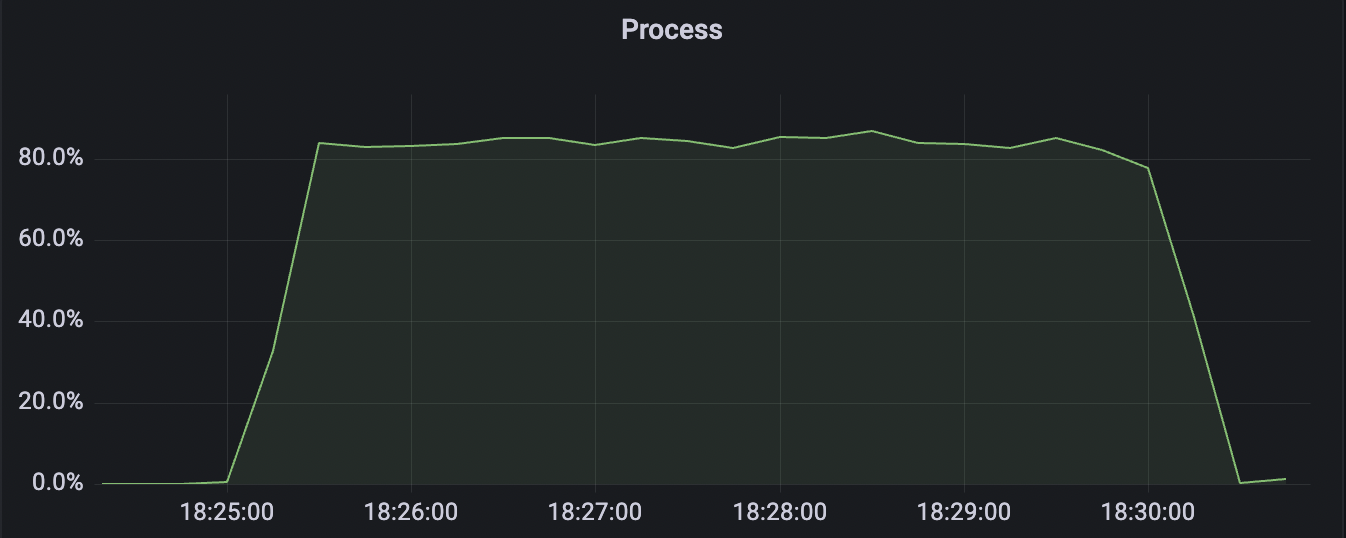 | 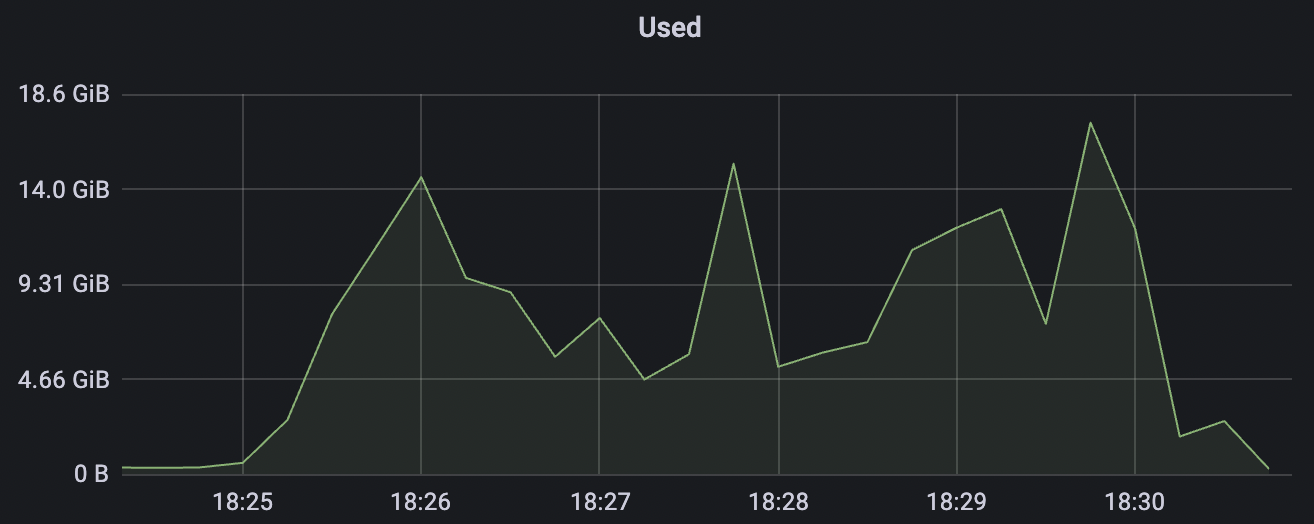 |
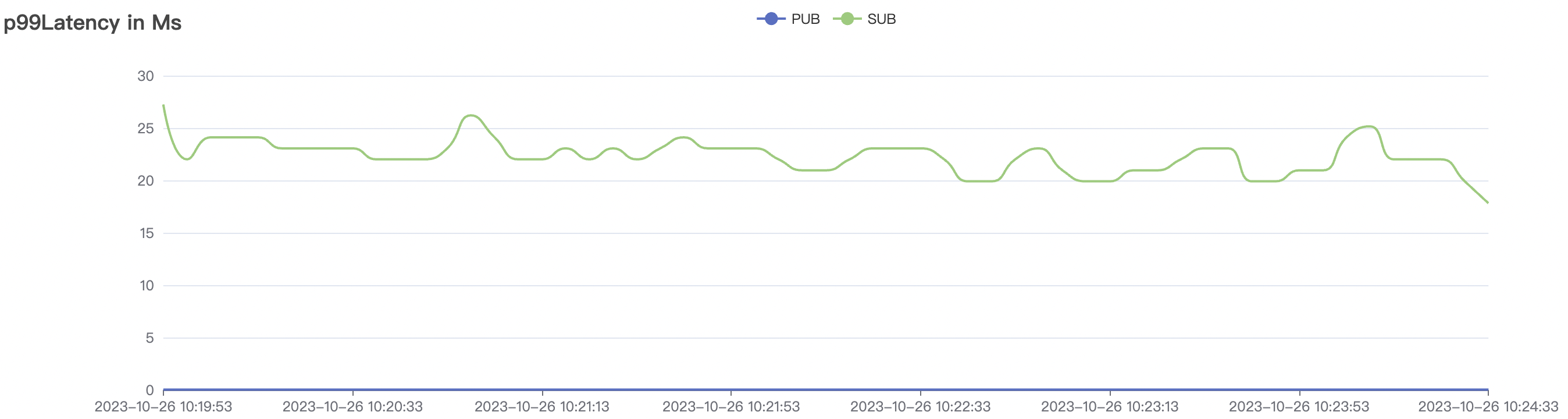
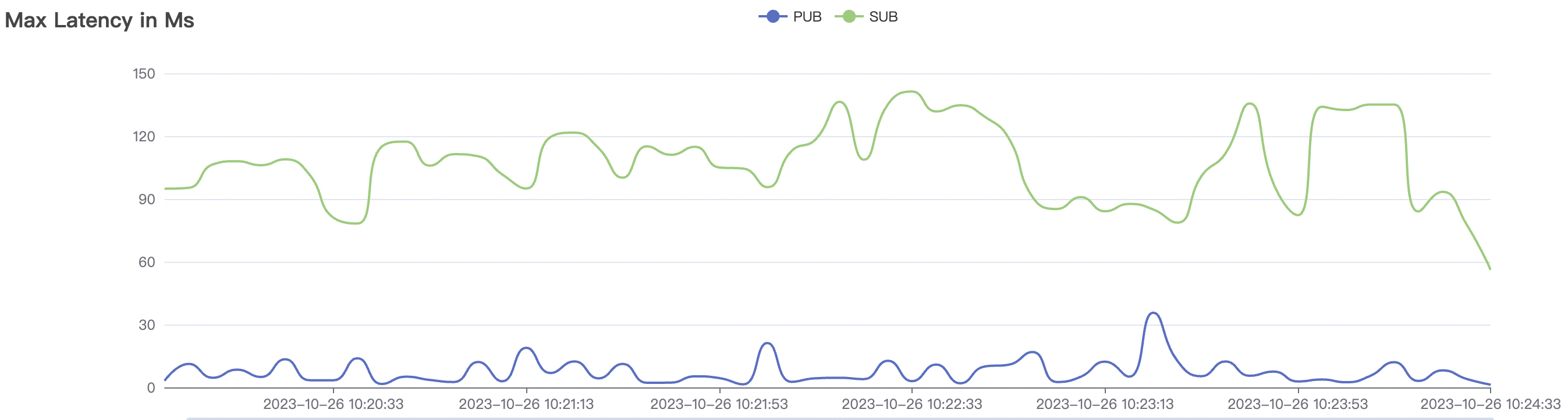
5k_5k_qos0_p32_100mps_3n场景附图:
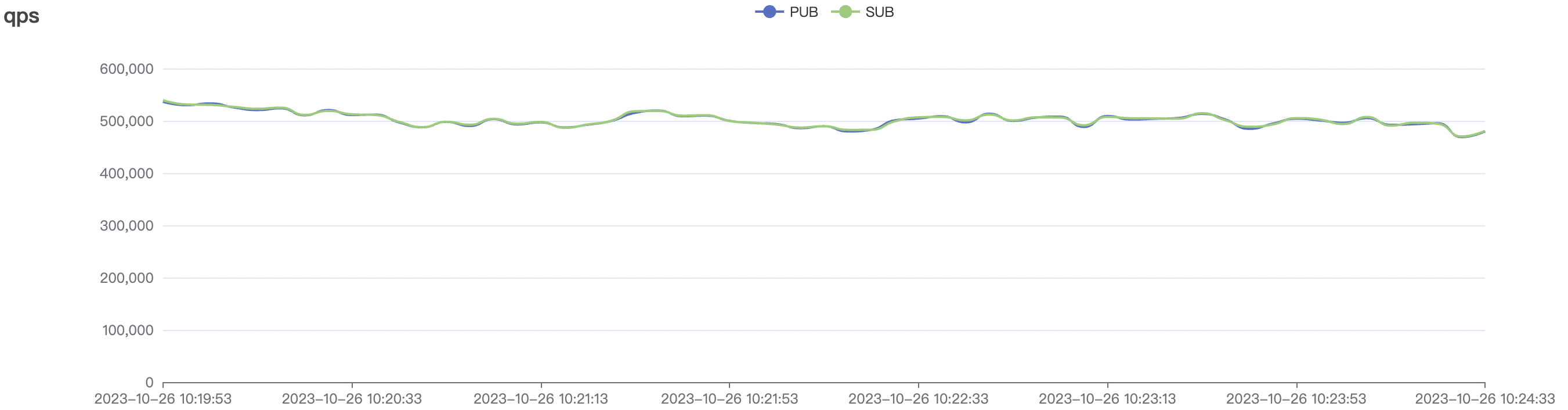 | 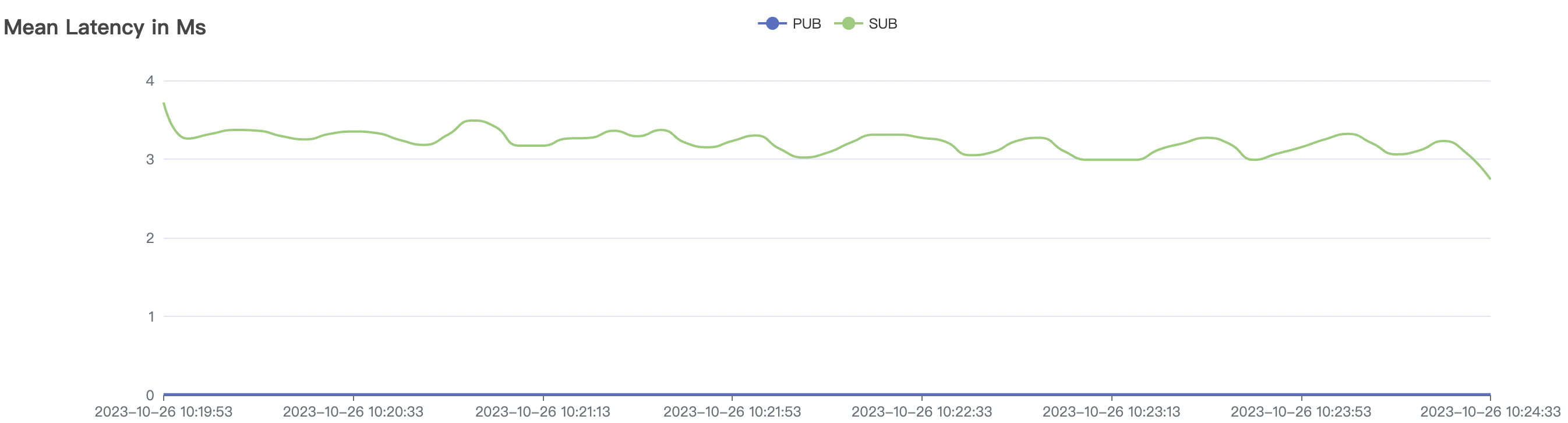 |
|---|---|
 |  |
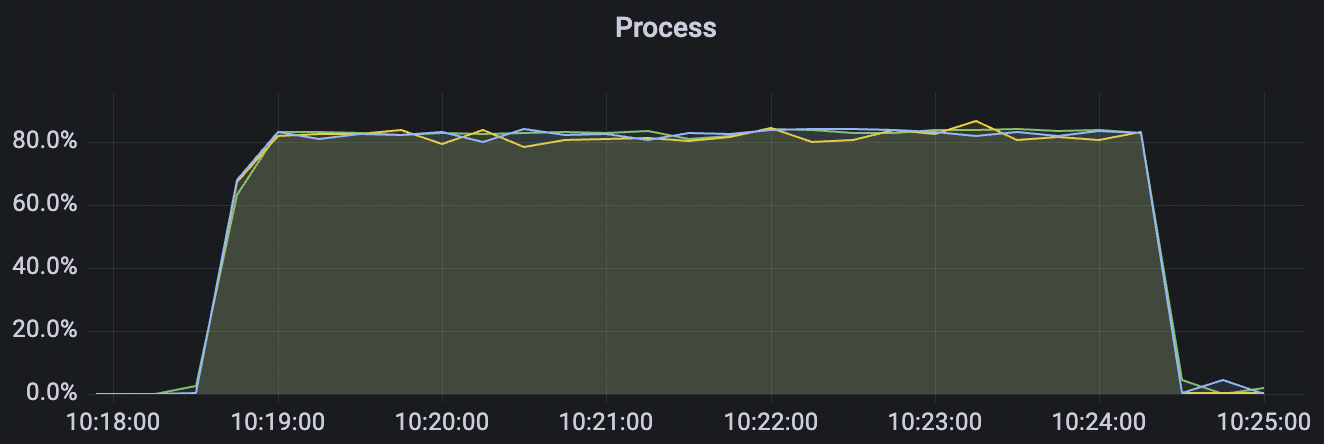 | 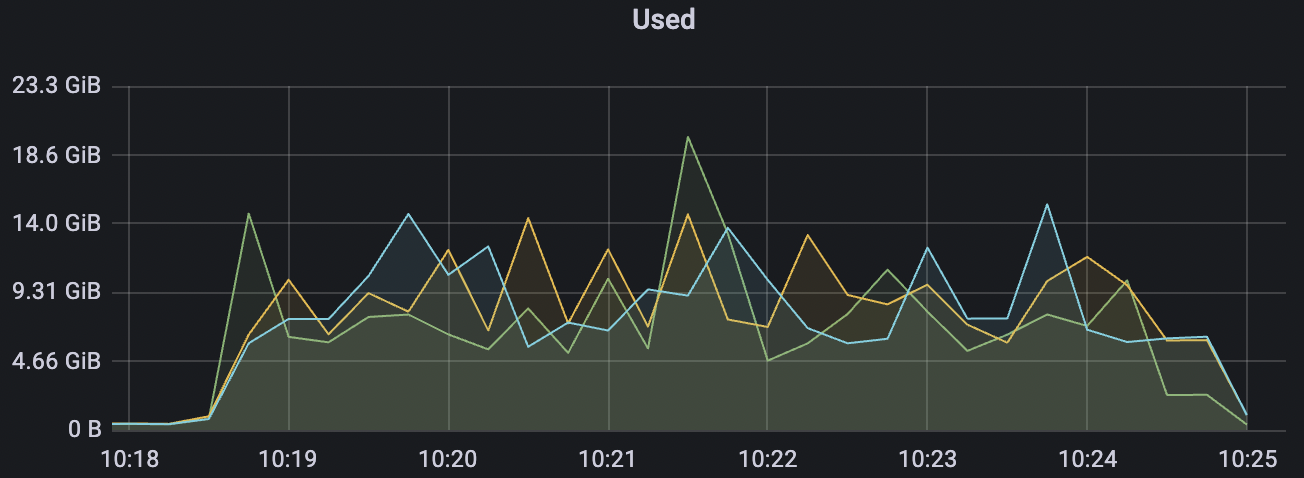 |
4k_4k_qos1_p32_100mps_3n场景附图:
 |  |
|---|---|
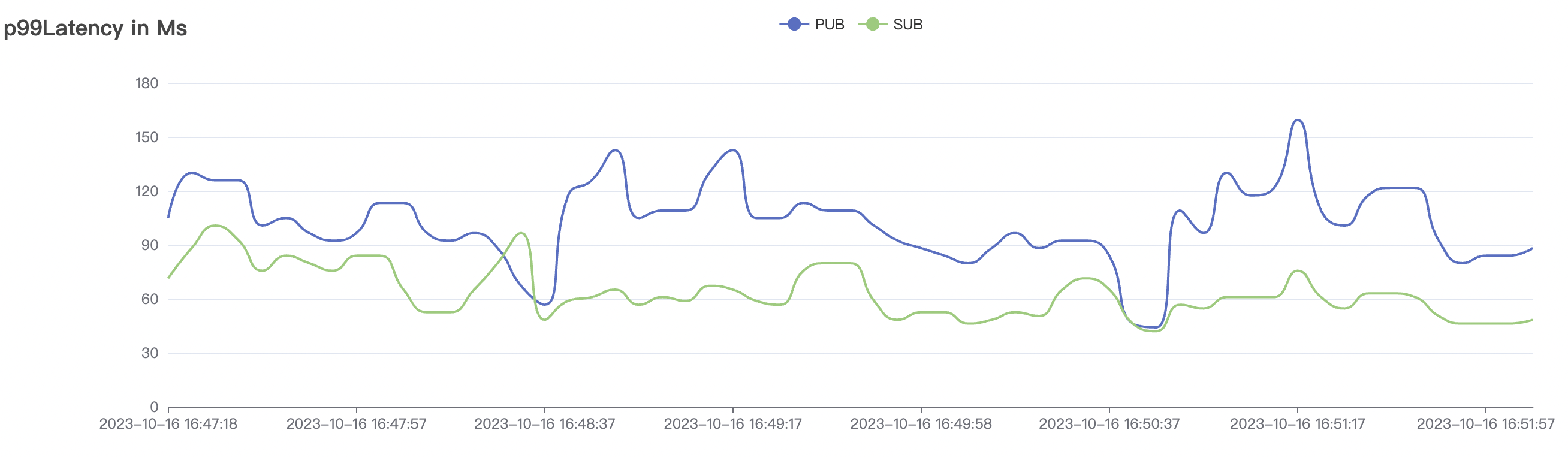 | 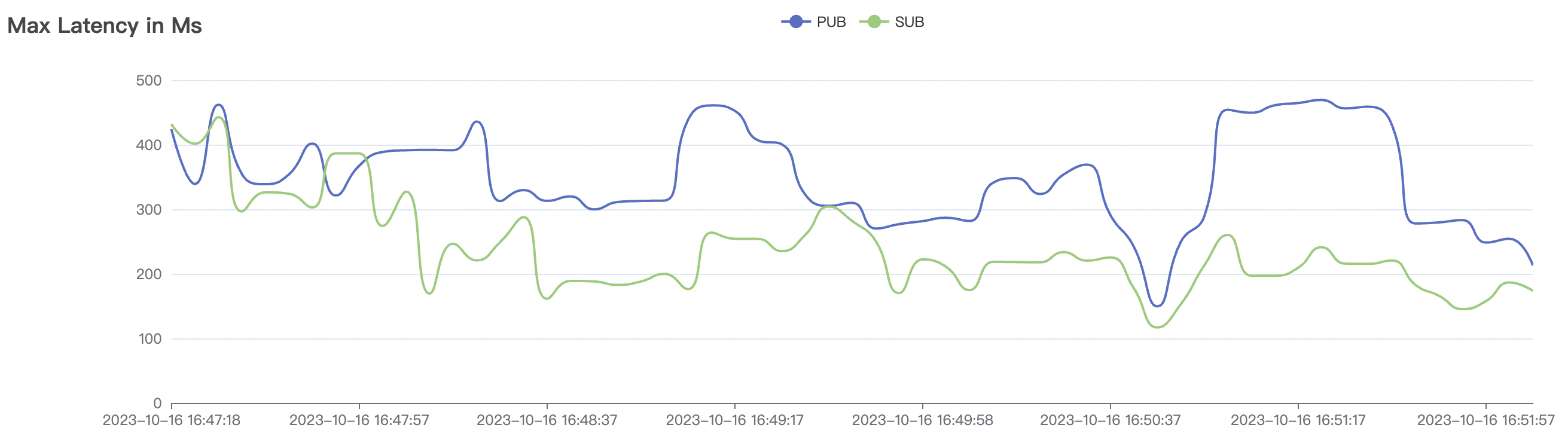 |
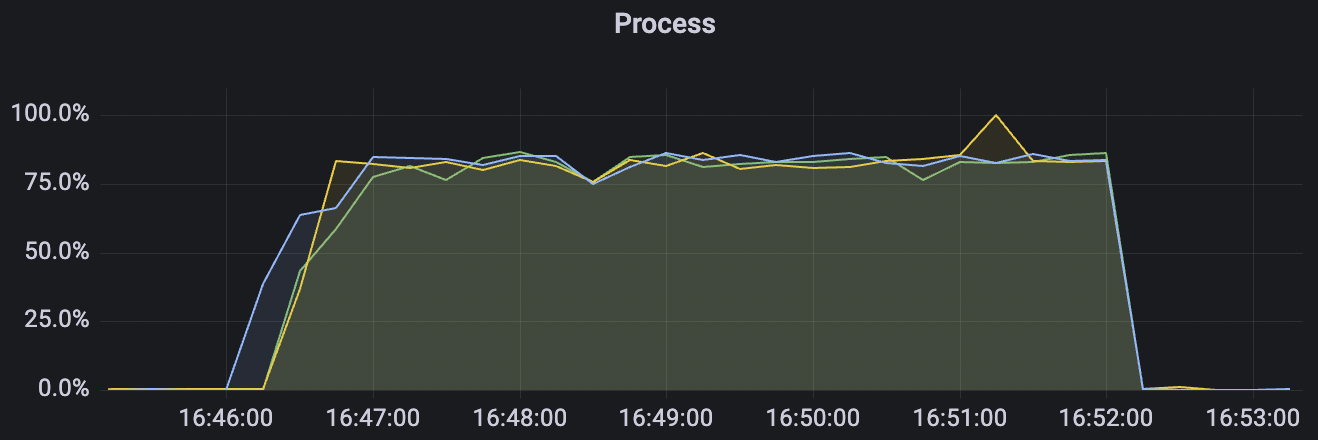 | 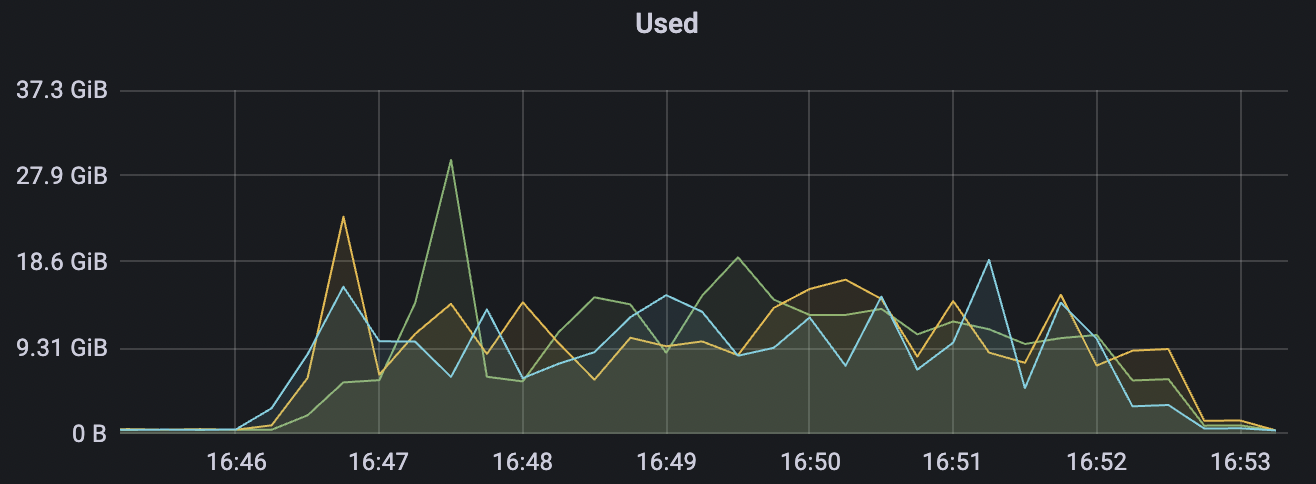 |
低频场景
| 场景组合 | QoS | 单连接m/s | 消息byte | 连接数C | 总消息m/s | 平均响应时间ms | P99响应时间ms | CPU | 内存占用GB |
|---|---|---|---|---|---|---|---|---|---|
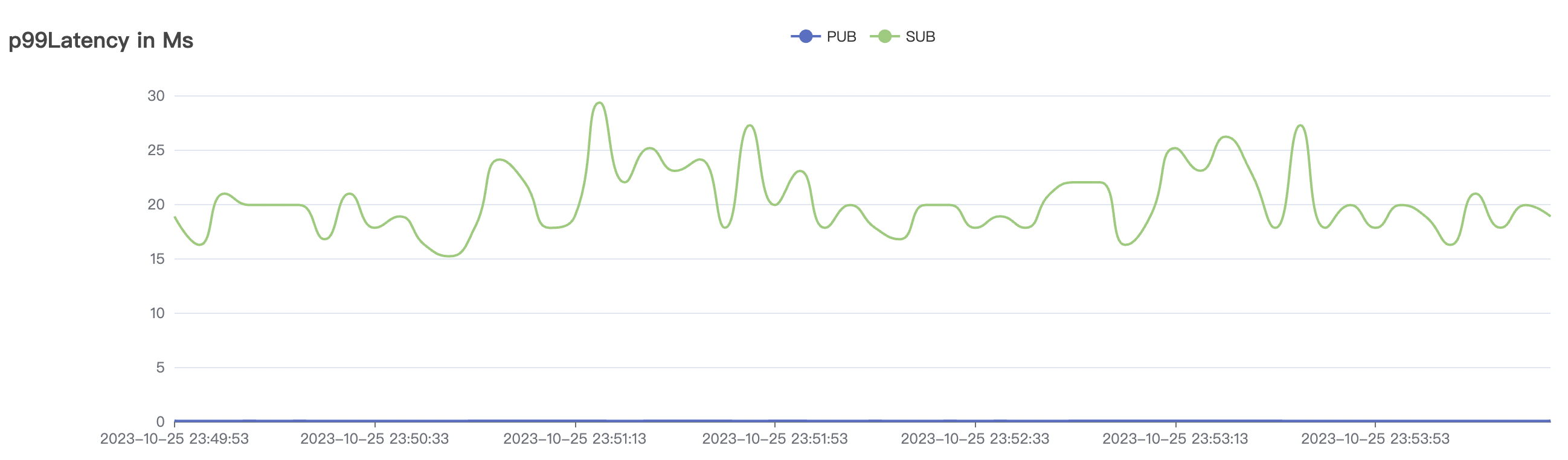
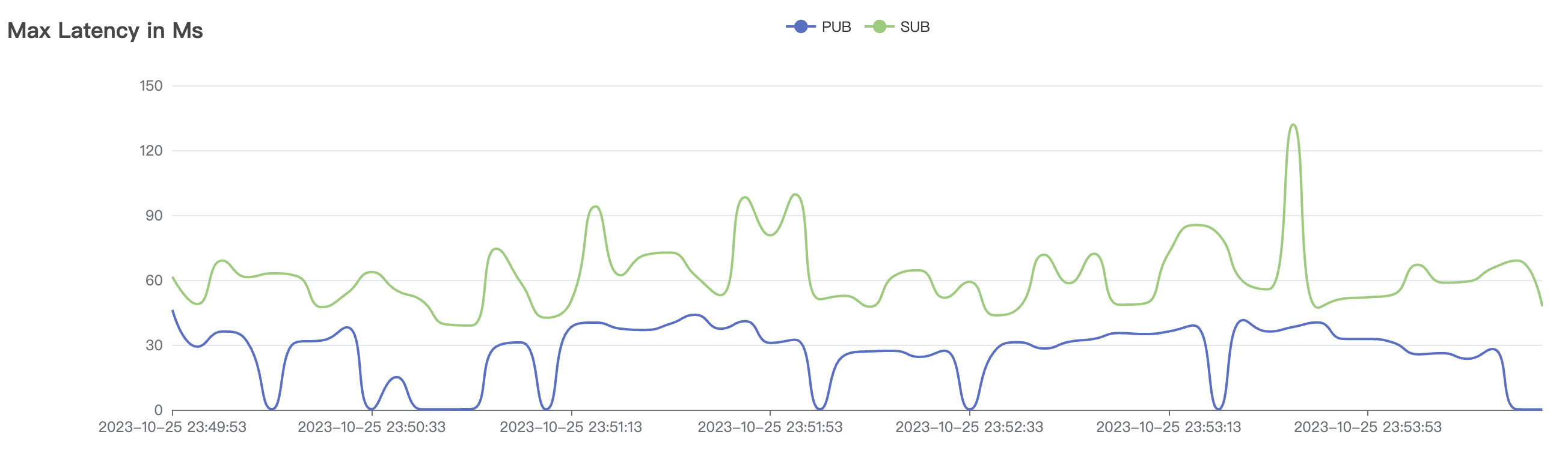
| 100k_100k_qos0_p256_1mps_1n | 0 | 1 | 256 | 200k | 100k | 2.14 | 17.82 | 80% | 6 ~ 12 |
| 100k_100k_qos1_p256_1mps_1n | 1 | 1 | 256 | 200k | 100k | 13.56 | 104.84 | 83% | 8 ~ 13 |
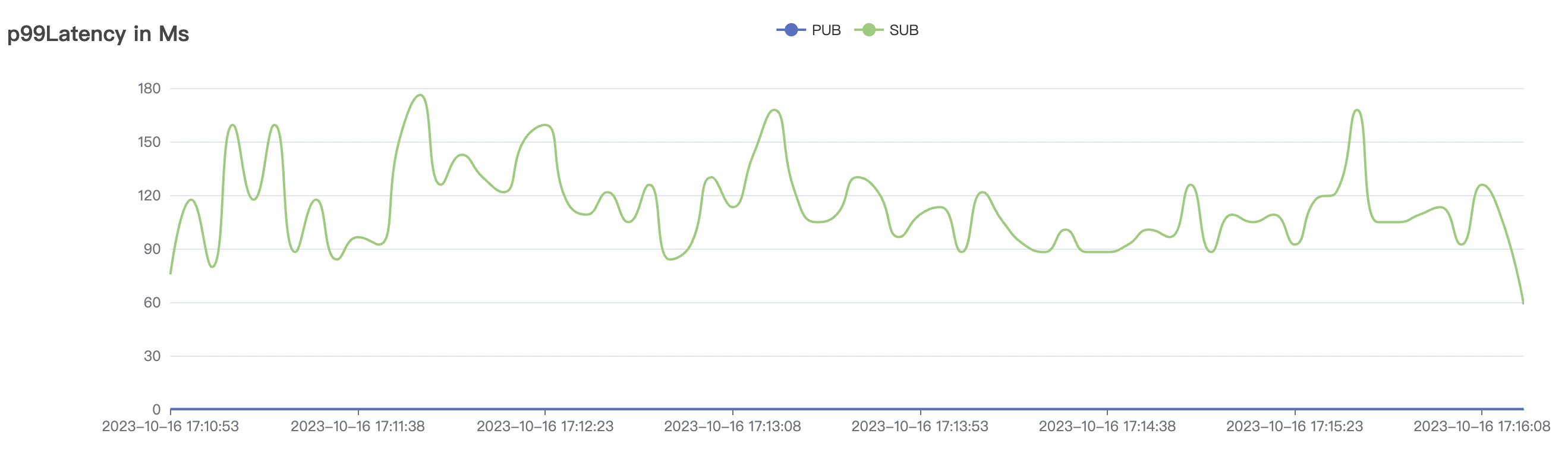
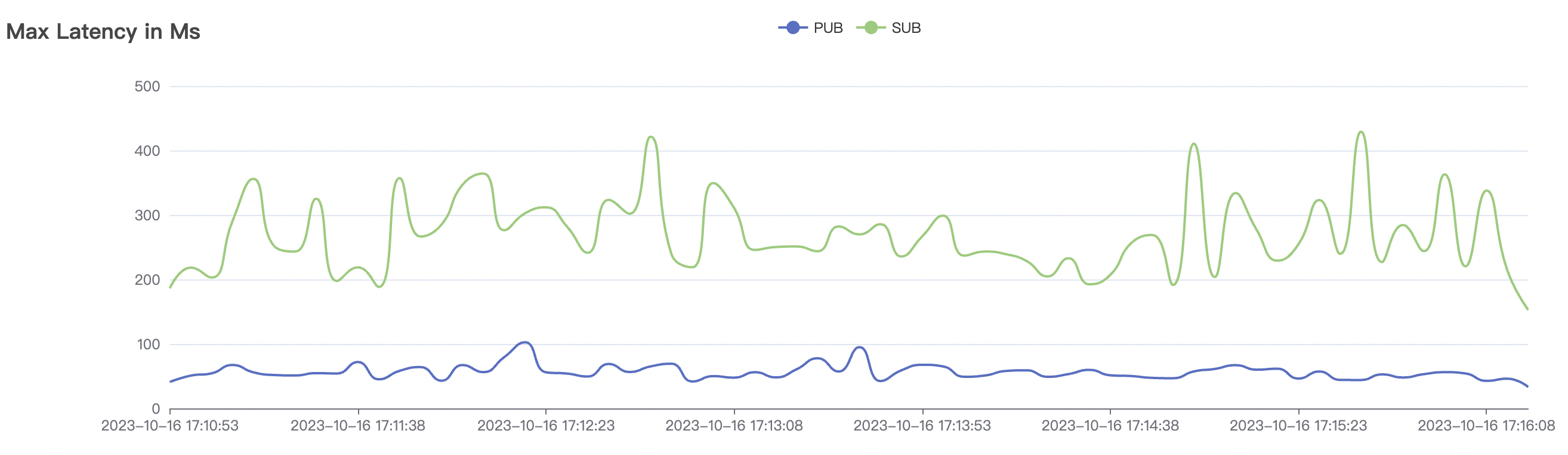
| 300k_300k_qos0_p256_1mps_3n | 0 | 1 | 256 | 600k | 300k | 17.03 | 113.23 | 83% | 10 ~ 20 |
| 200k_200k_qos1_p256_1mps_3n | 1 | 1 | 256 | 400k | 200k | 3.86 | 29.34 | 81% | 7 ~ 12 |
100k_100k_qos0_p256_1mps_1n场景附图:
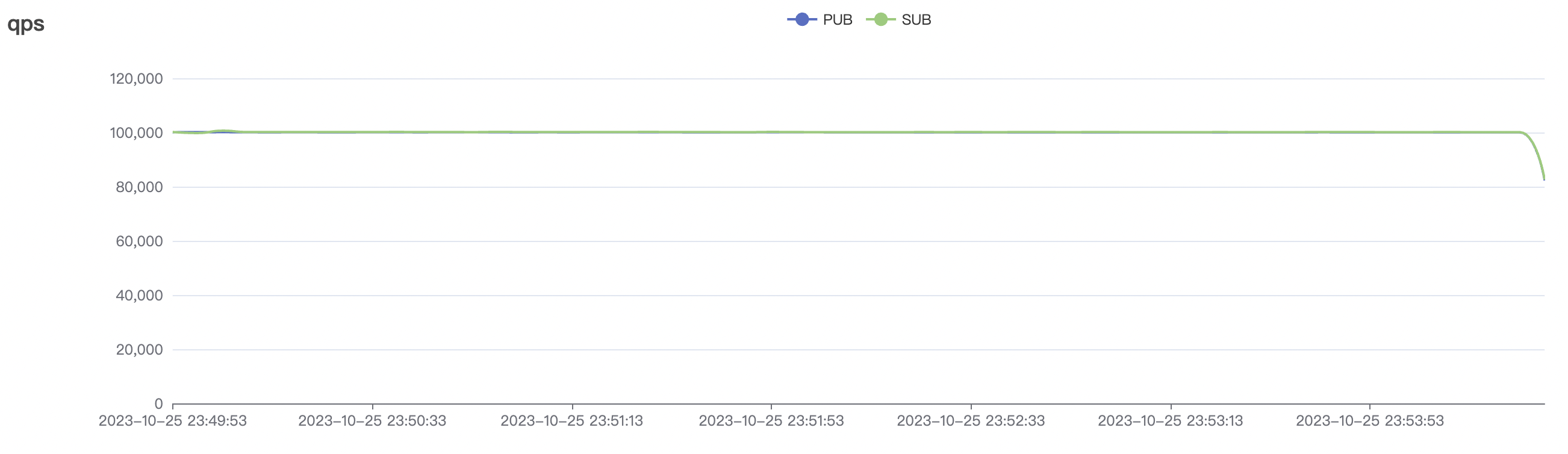 | 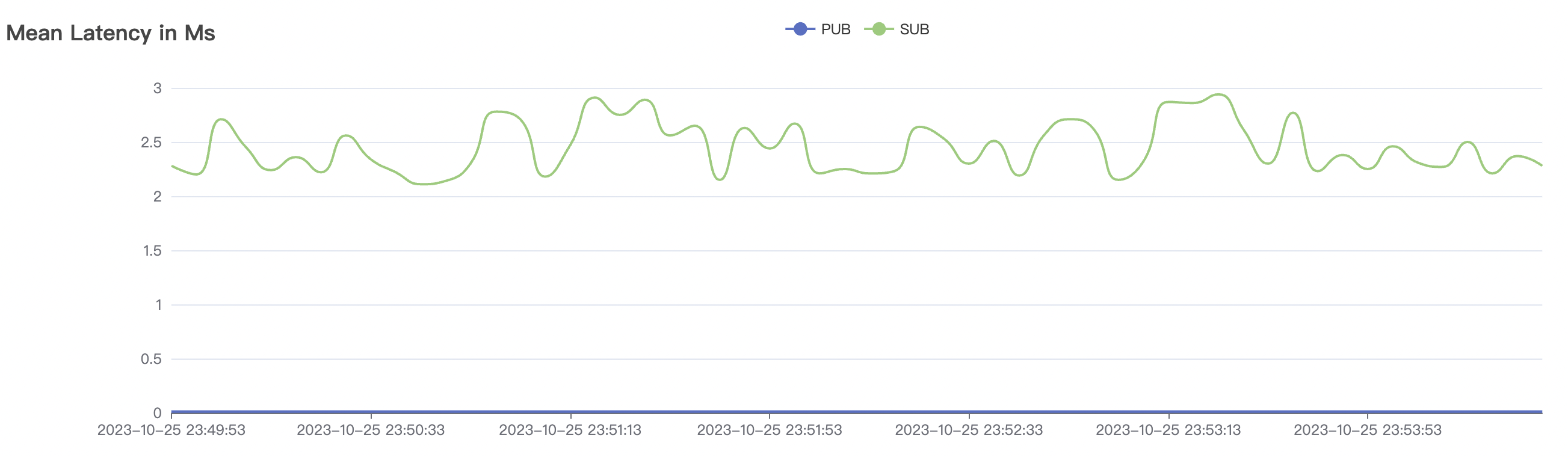 |
|---|---|
 |  |
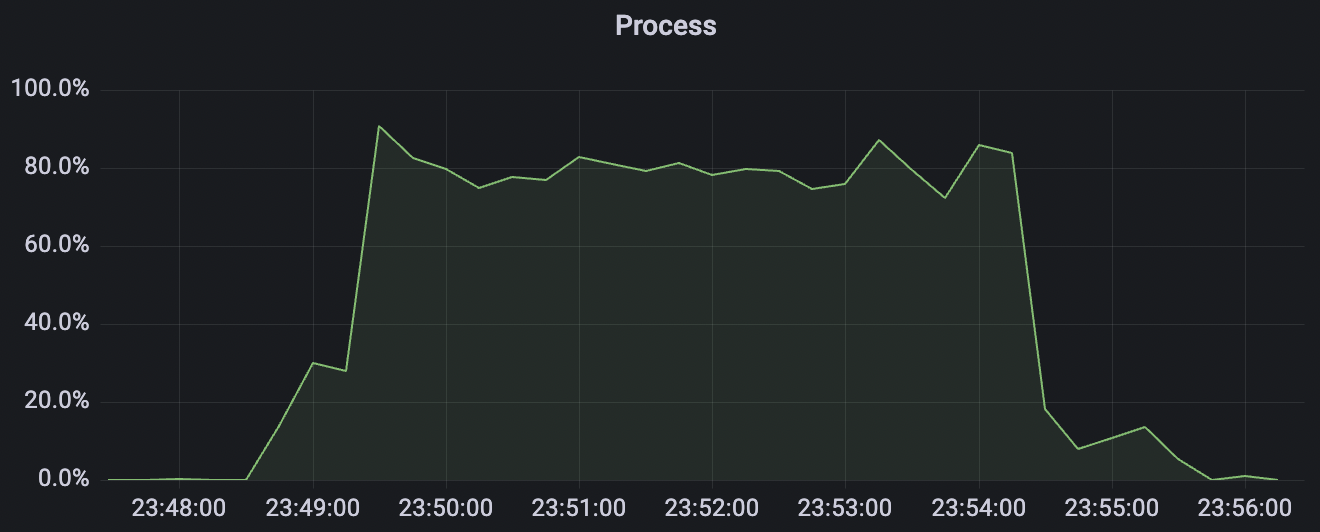 | 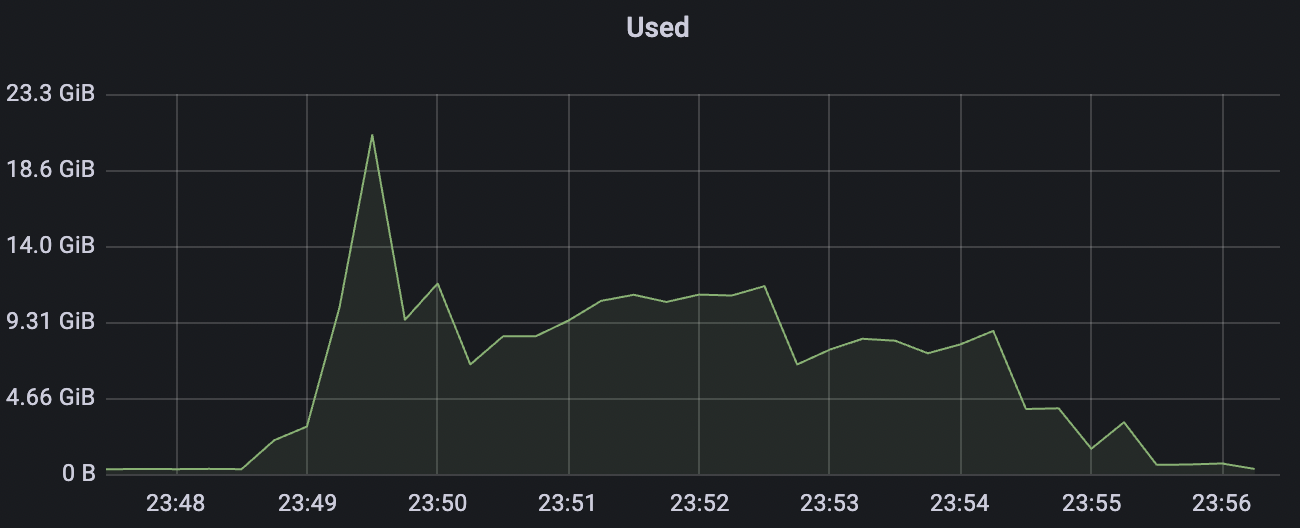 |
100k_100k_qos1_p256_1mps_1n场景附图:
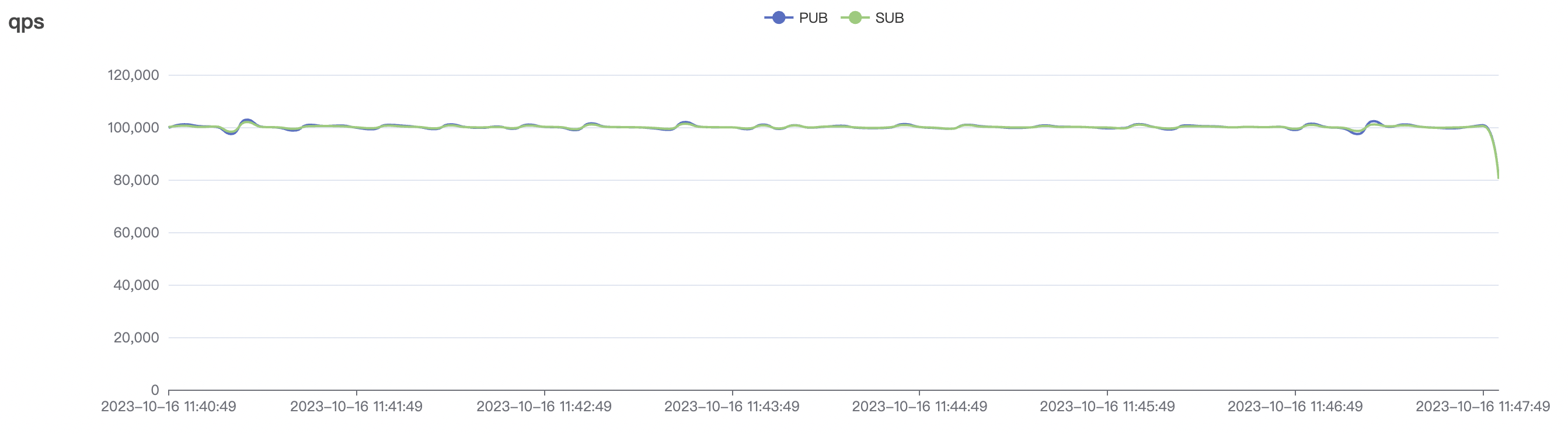 | 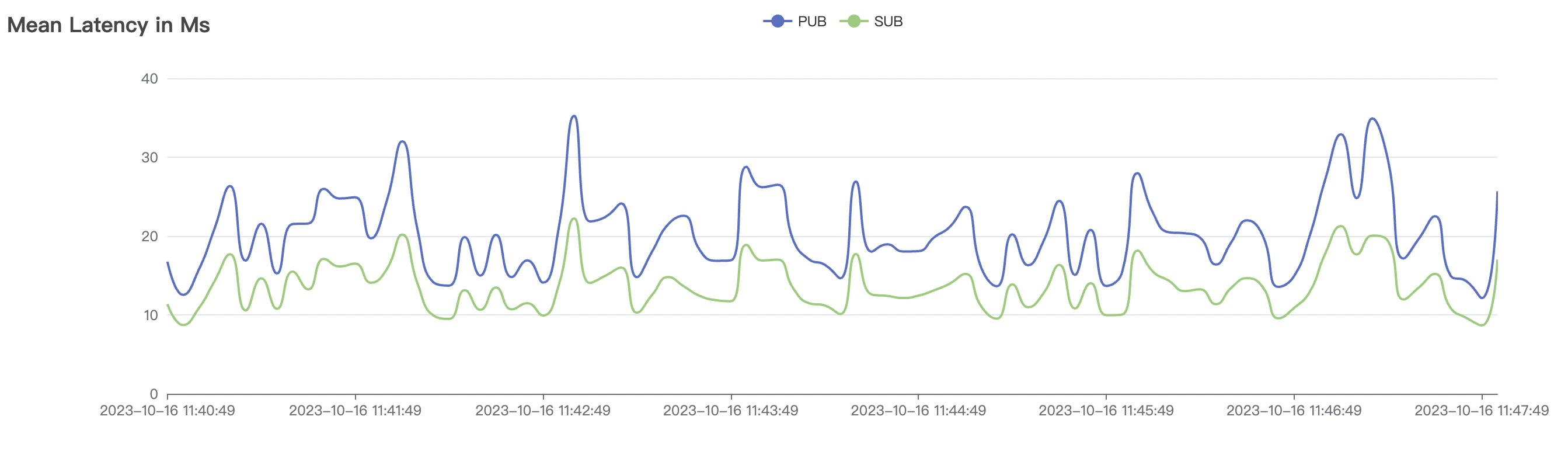 |
|---|---|
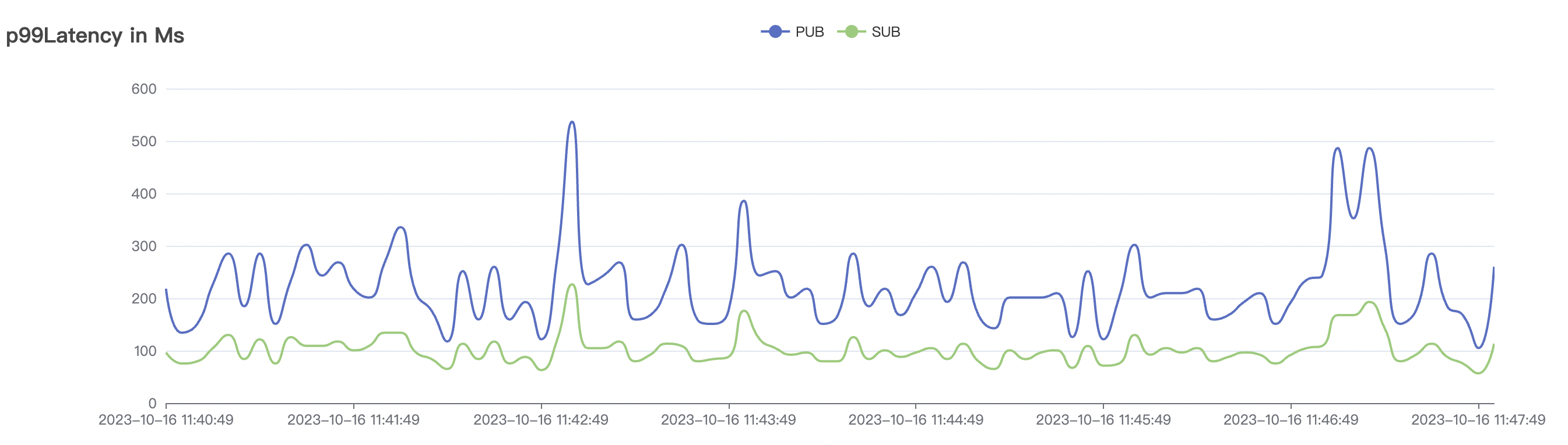 | 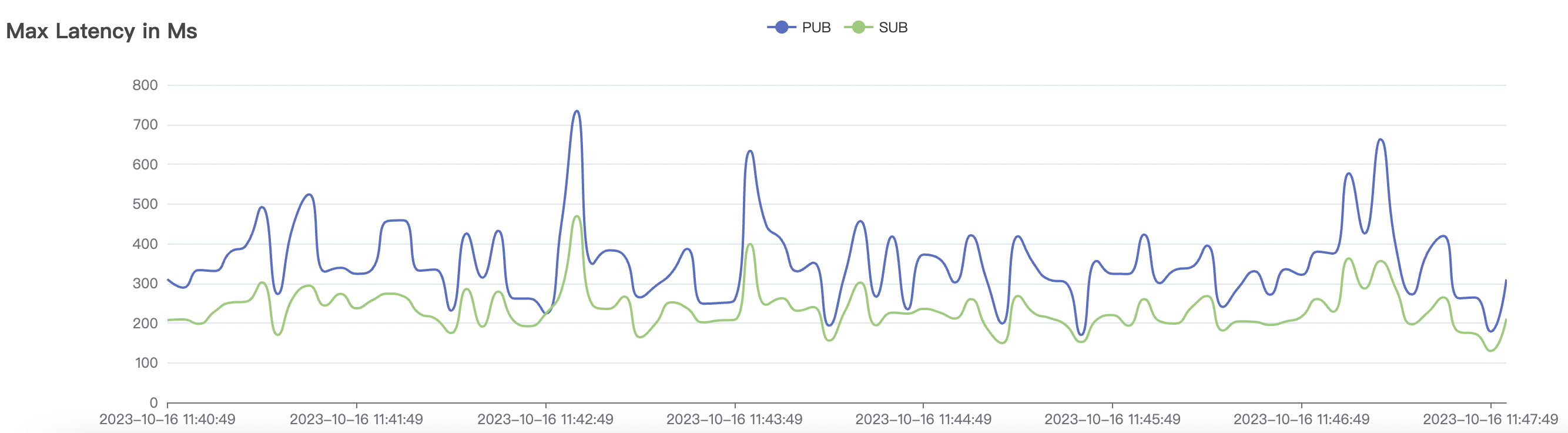 |
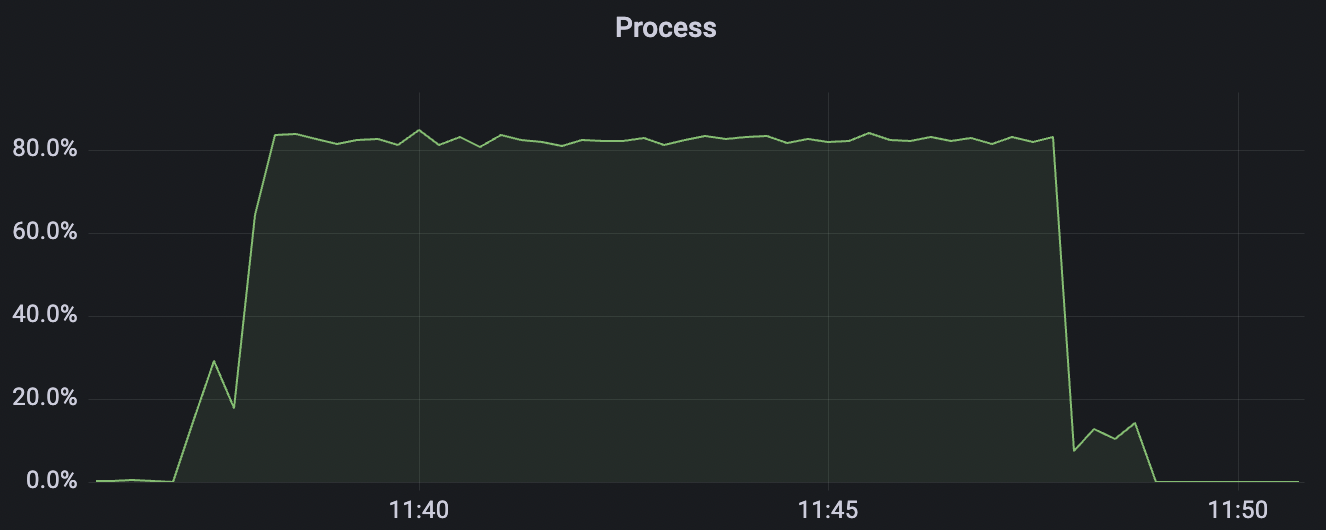 | 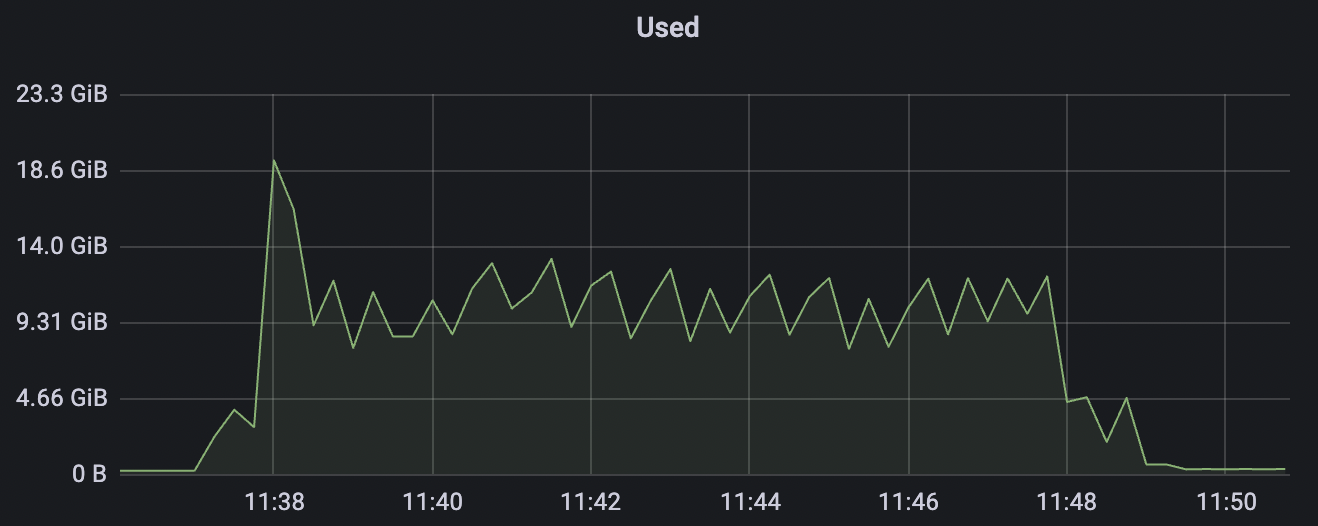 |
300k_300k_qos0_p256_1mps_3n场景附图:
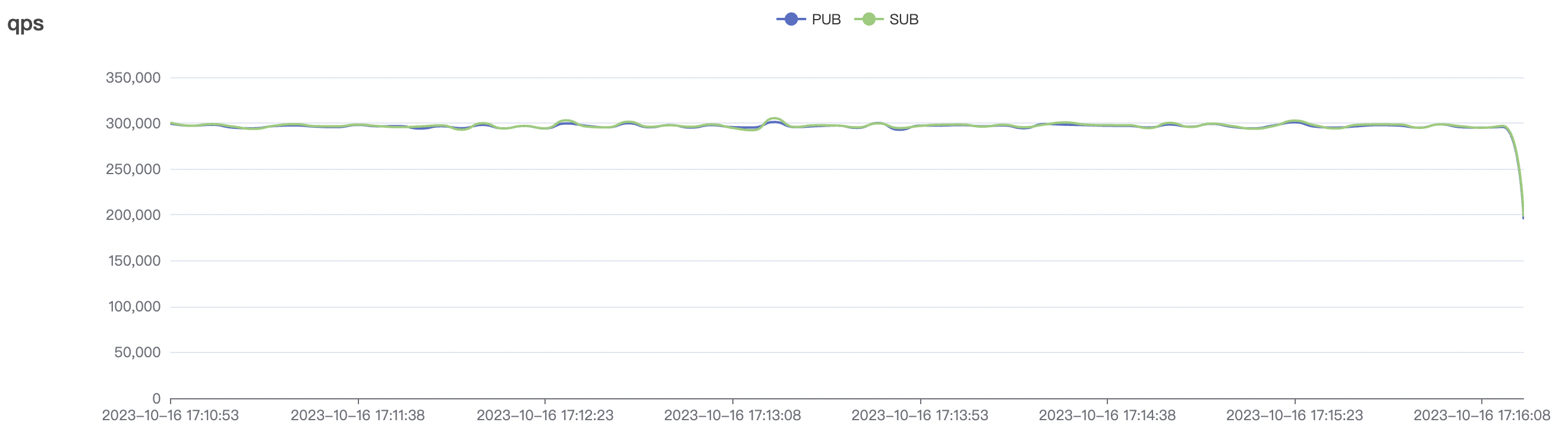 | 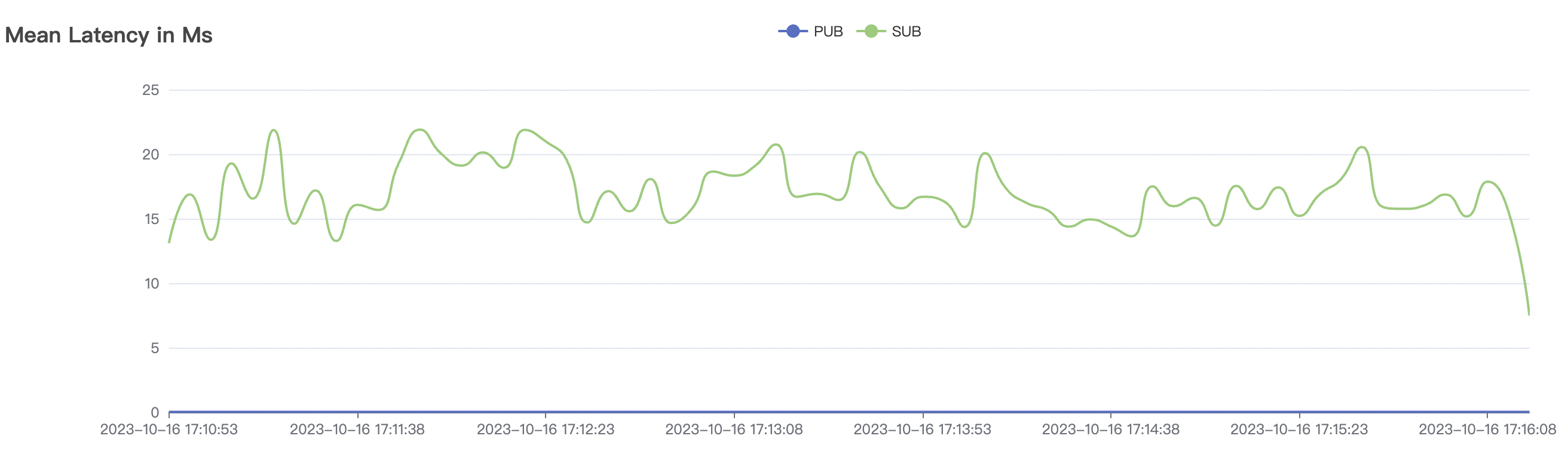 |
|---|---|
 |  |
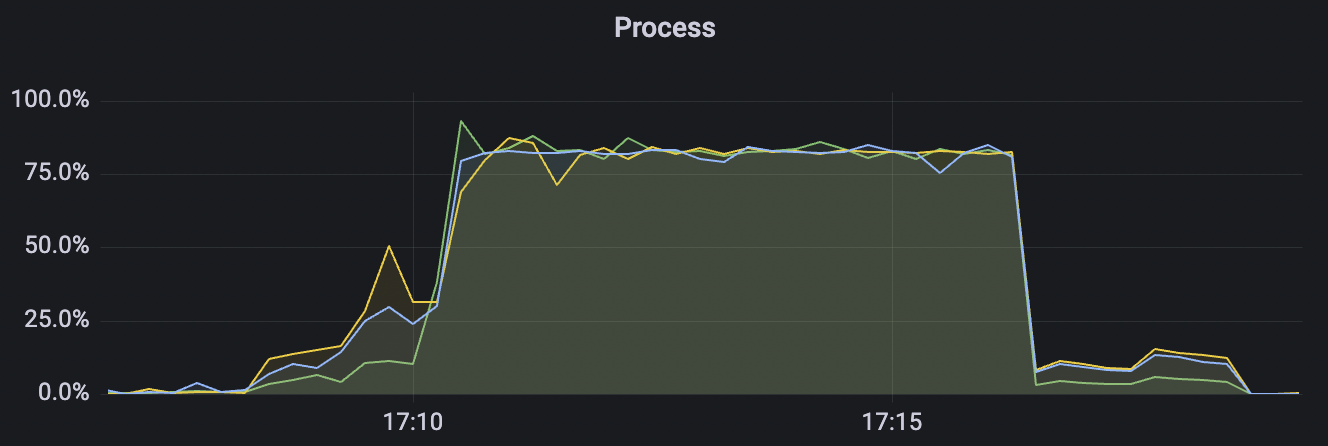 | 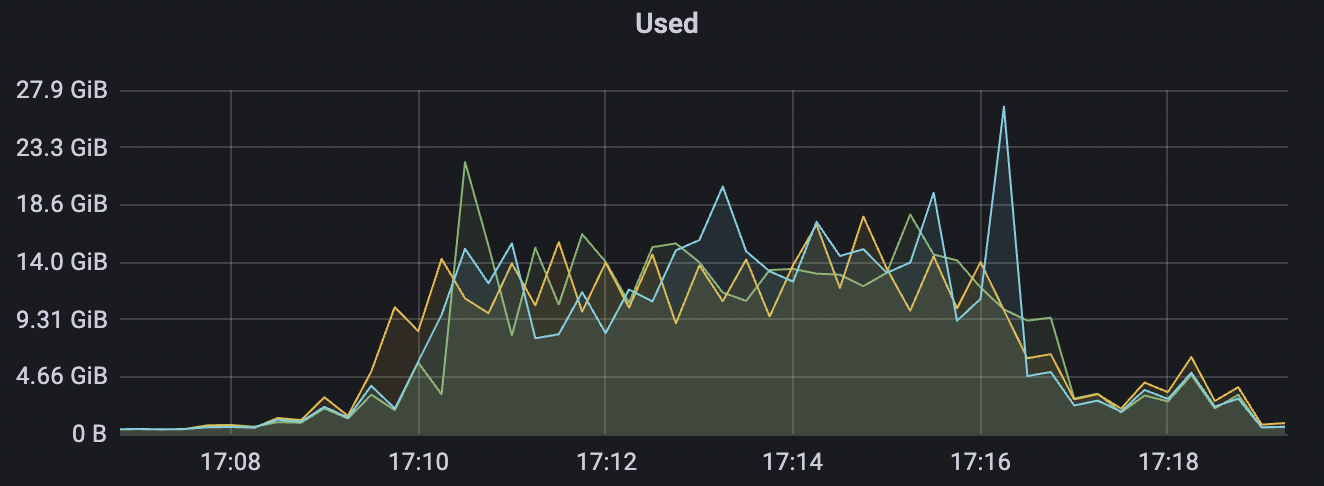 |
共享订阅场景
| 场景组合 | QoS | 单连接m/s | 消息byte | 连接数C | 总消息m/s | 平均响应时间ms | P99响应时间ms | CPU | 内存占用GB |
|---|---|---|---|---|---|---|---|---|---|
| 100k_1000_qos0_p256_1mps_1n | 0 | 1 | 256 | 101k | 100k | 1.17 | 11.0 | 82% | 6 ~ 20 |
| 100k_1000_qos1_p256_1mps_1n | 1 | 1 | 256 | 101k | 100k | 1.82 | 14.67 | 78% | 5 ~ 18 |
| 300k_3000_qos0_p256_1mps_3n | 0 | 1 | 256 | 303k | 300k | 3.17 | 19.91 | 80% | 10 ~ 20 |
| 200k_2000_qos1_p256_1mps_3n | 1 | 1 | 256 | 202k | 200k | 5.9 | 43.84 | 77% | 5 ~ 20 |
100k_1000_qos0_p256_1mps_1n场景附图:
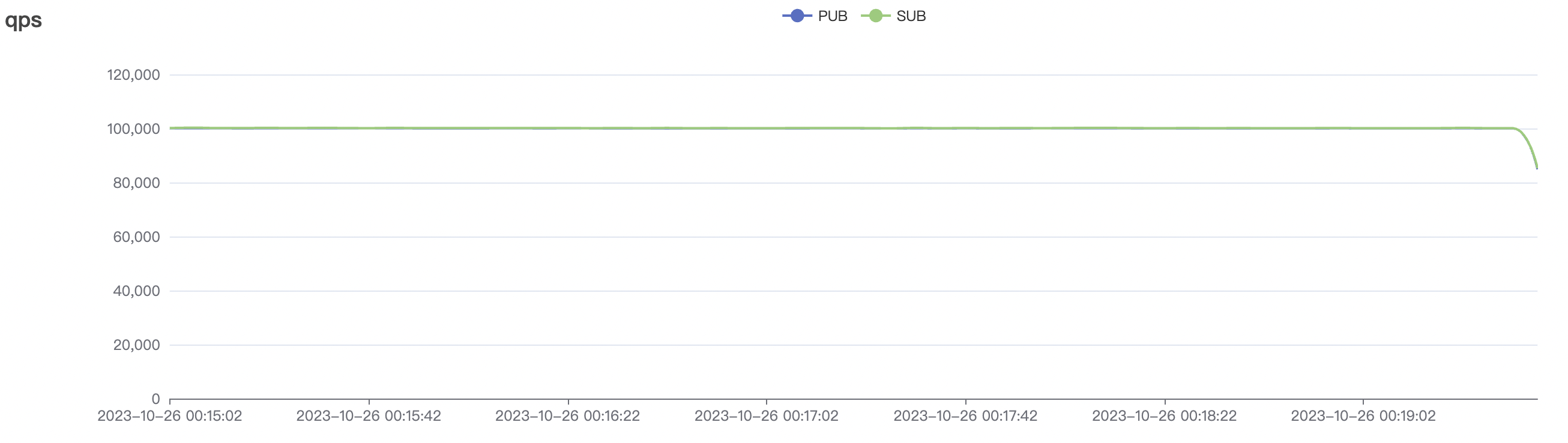 | 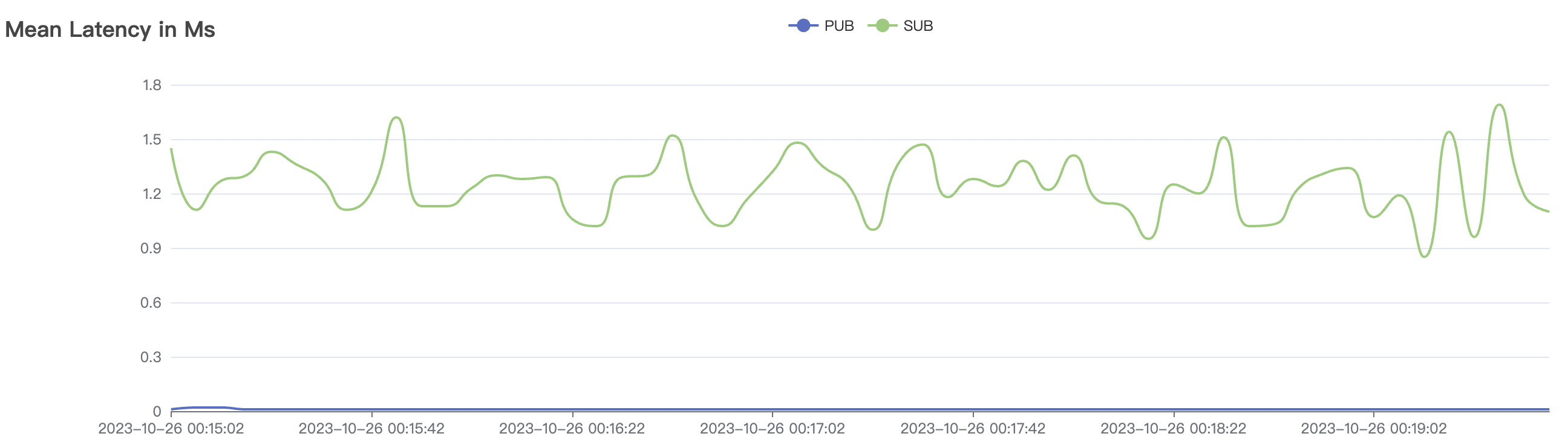 |
|---|---|
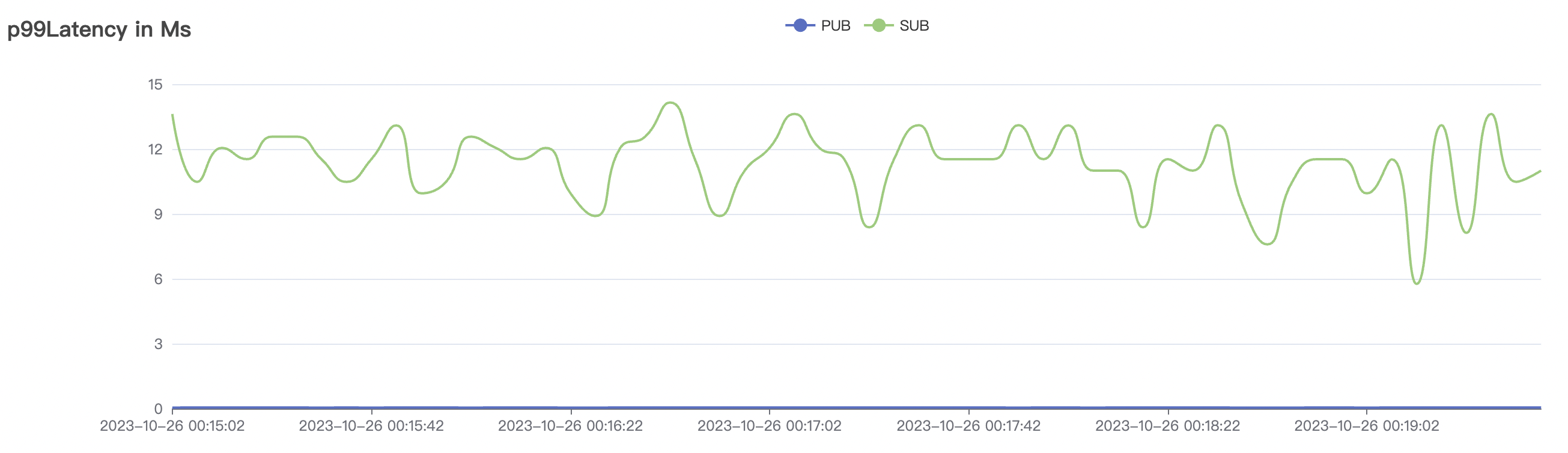 | 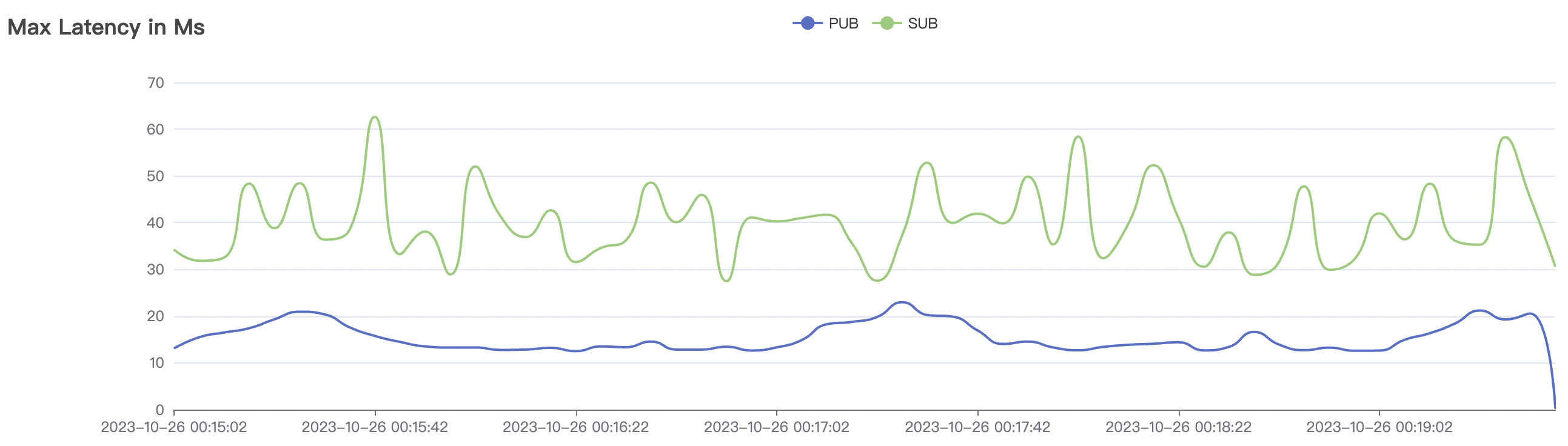 |
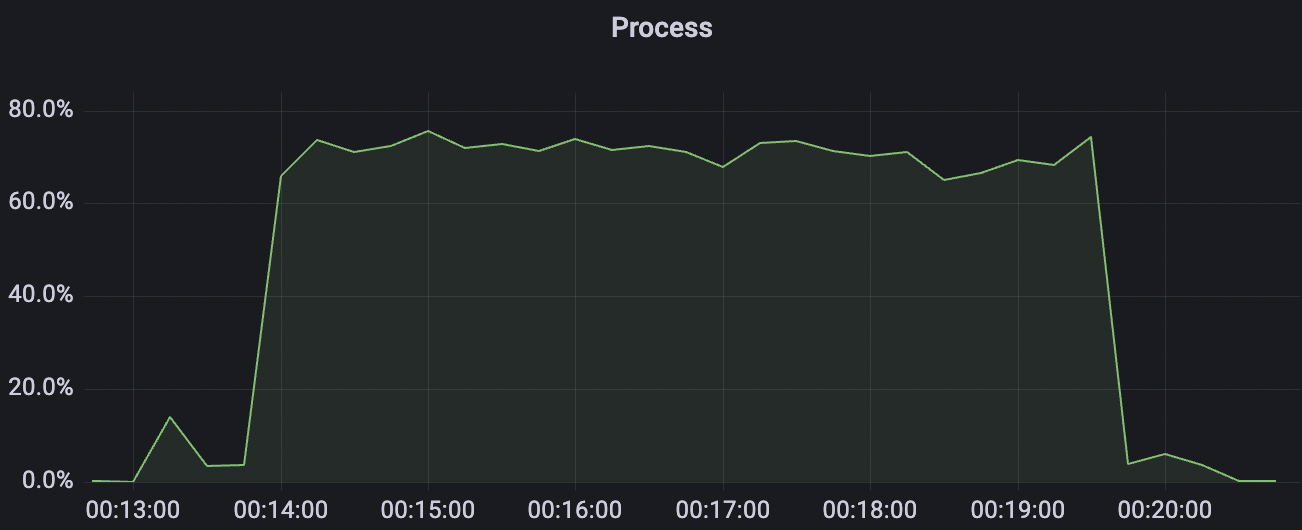 | 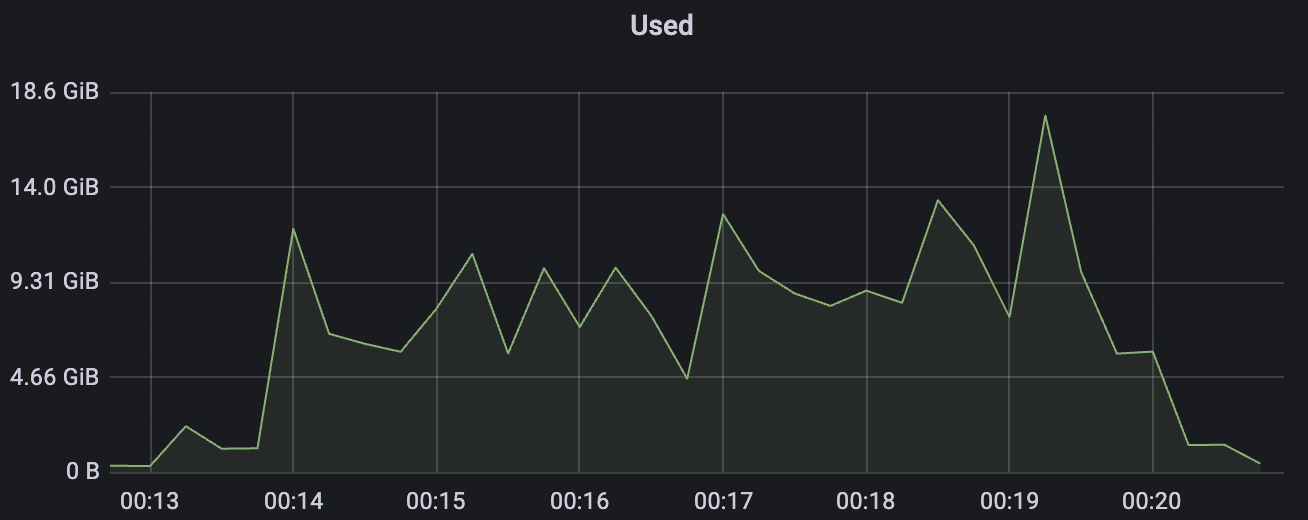 |
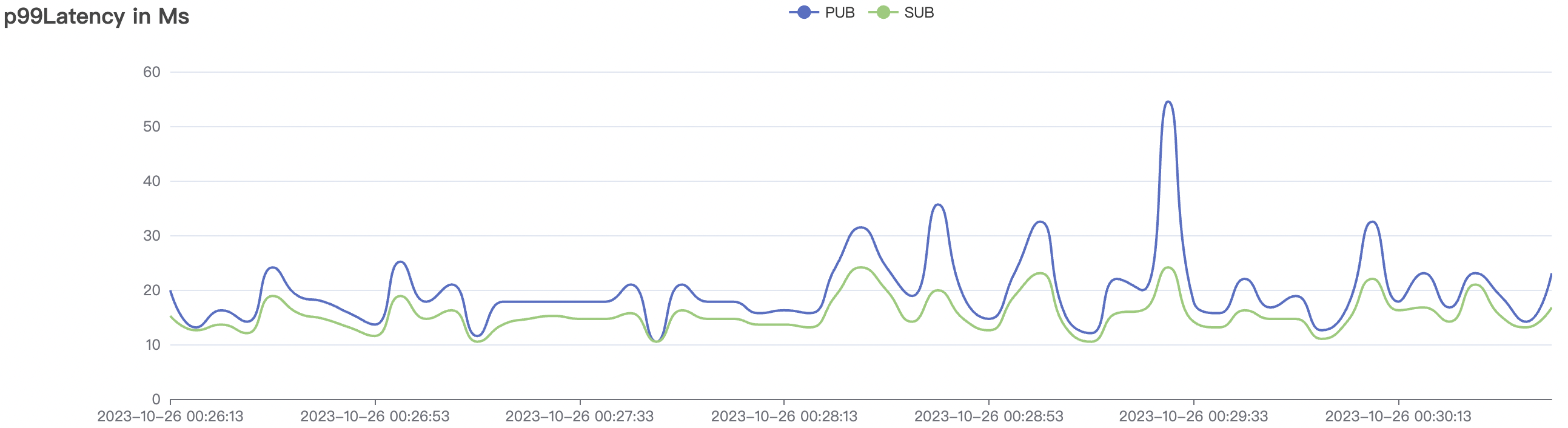
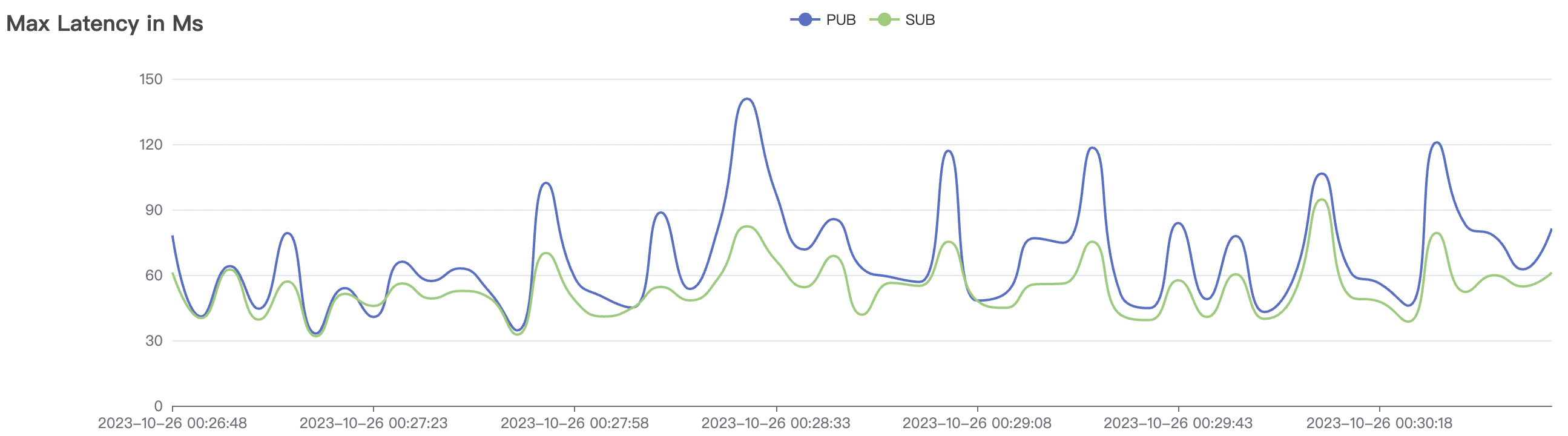
100k_1000_qos1_p256_1mps_1n场景附图:
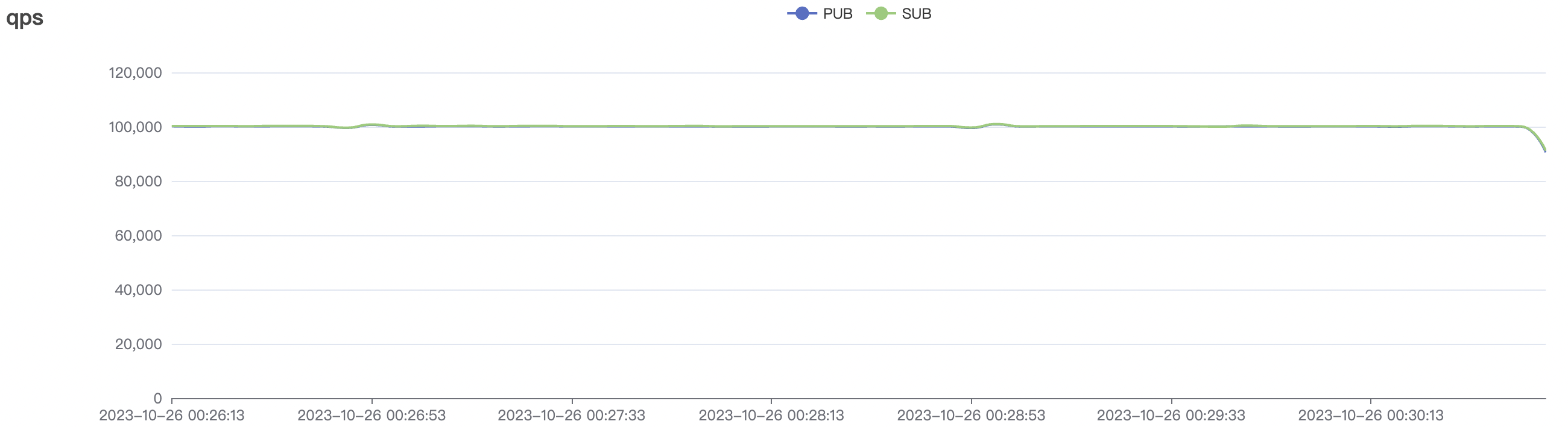 | 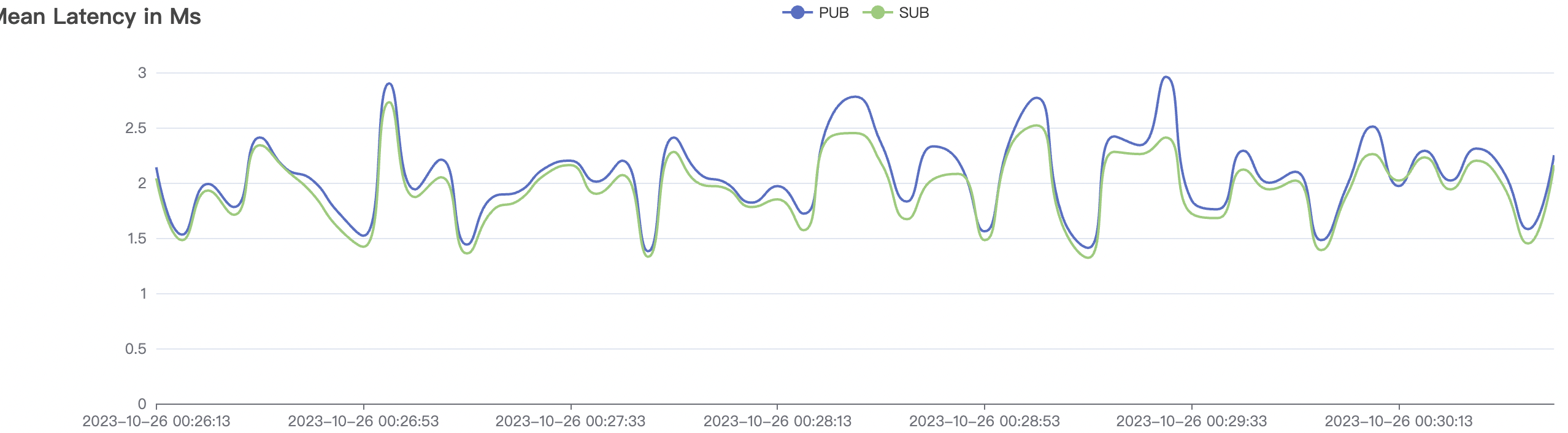 |
|---|---|
 |  |
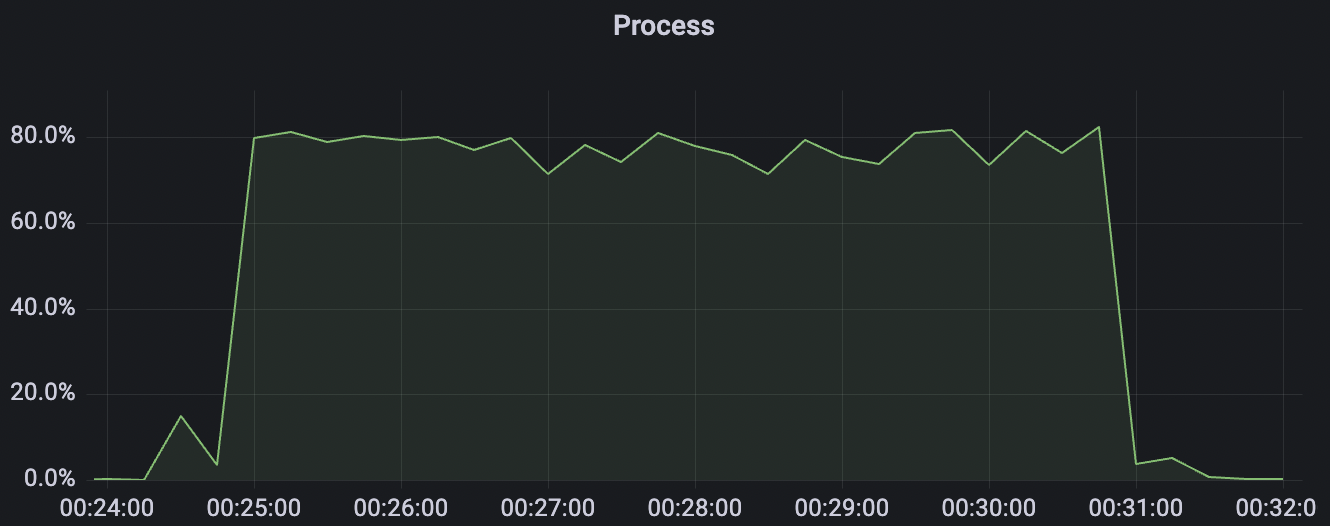 | 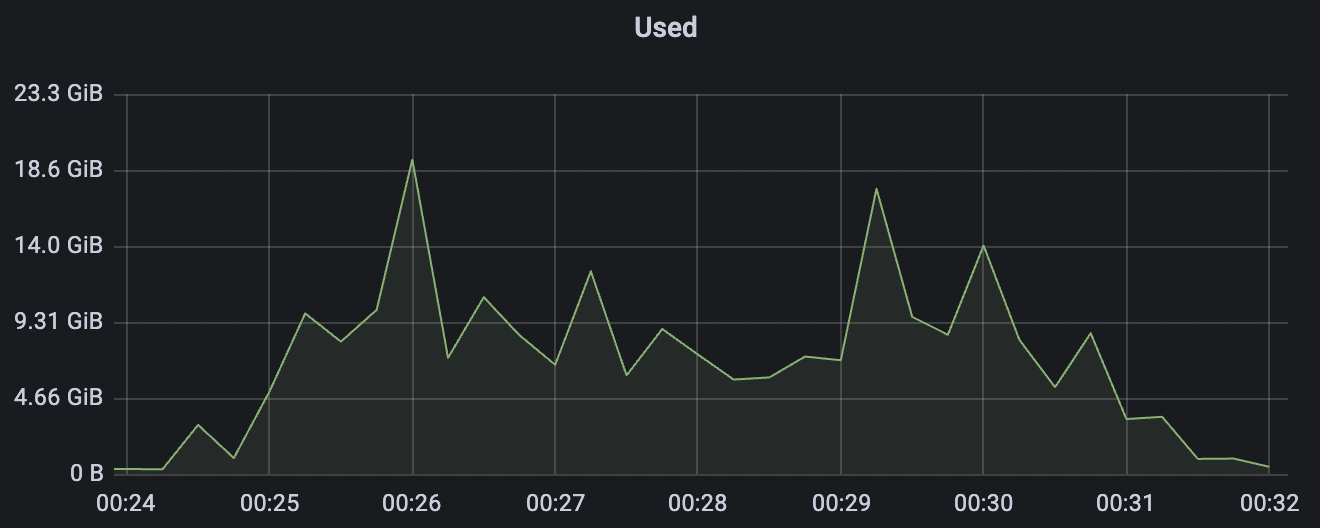 |
300k_3000_qos0_p256_1mps_3n场景附图:
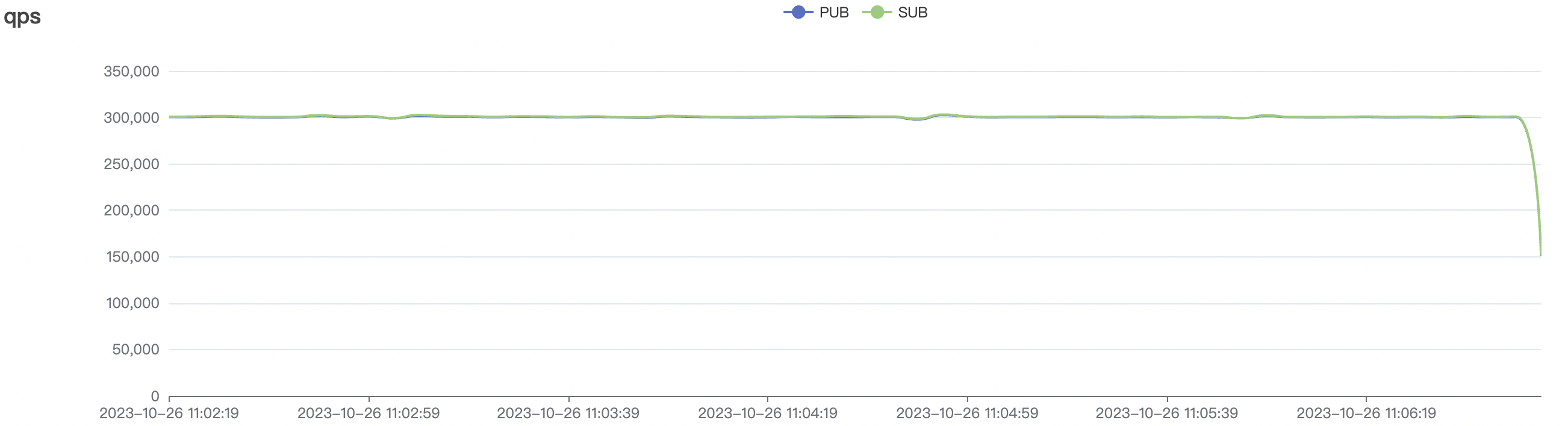 | 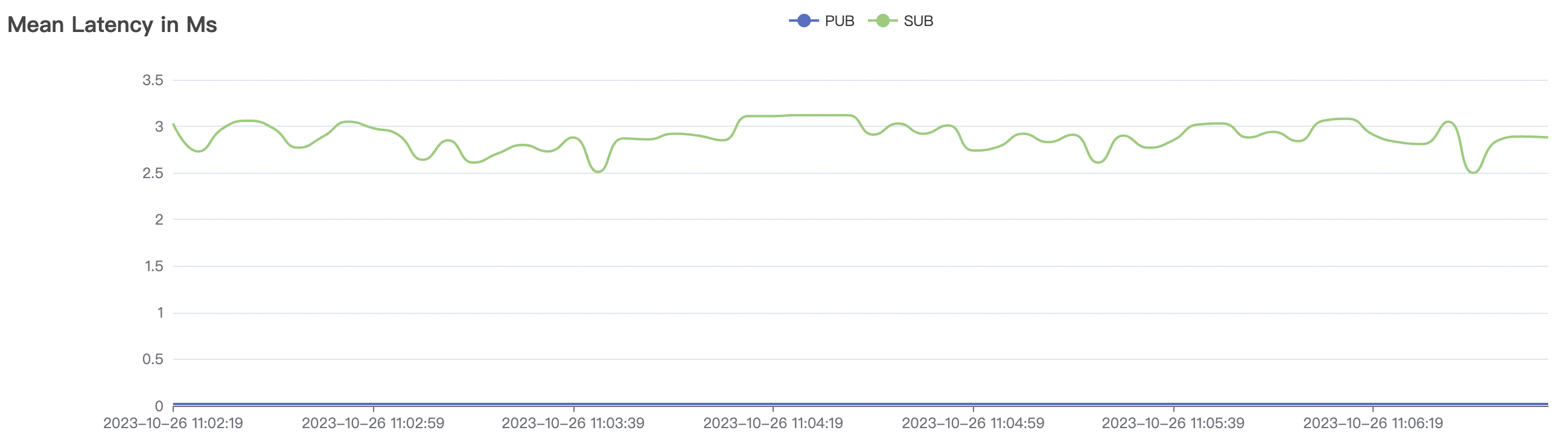 |
|---|---|
 |  |
 |  |
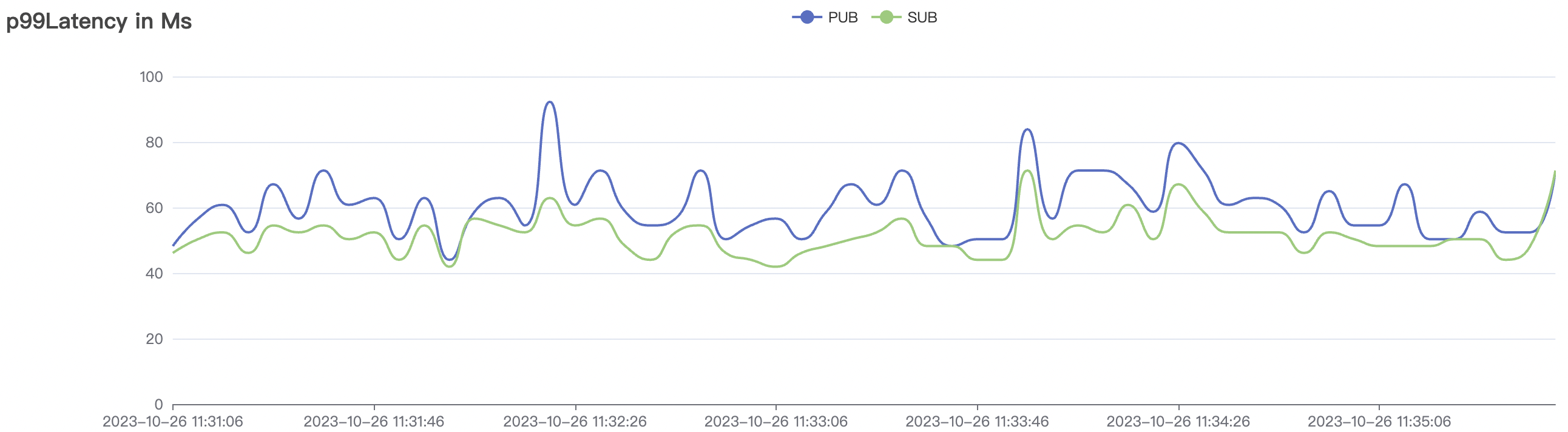
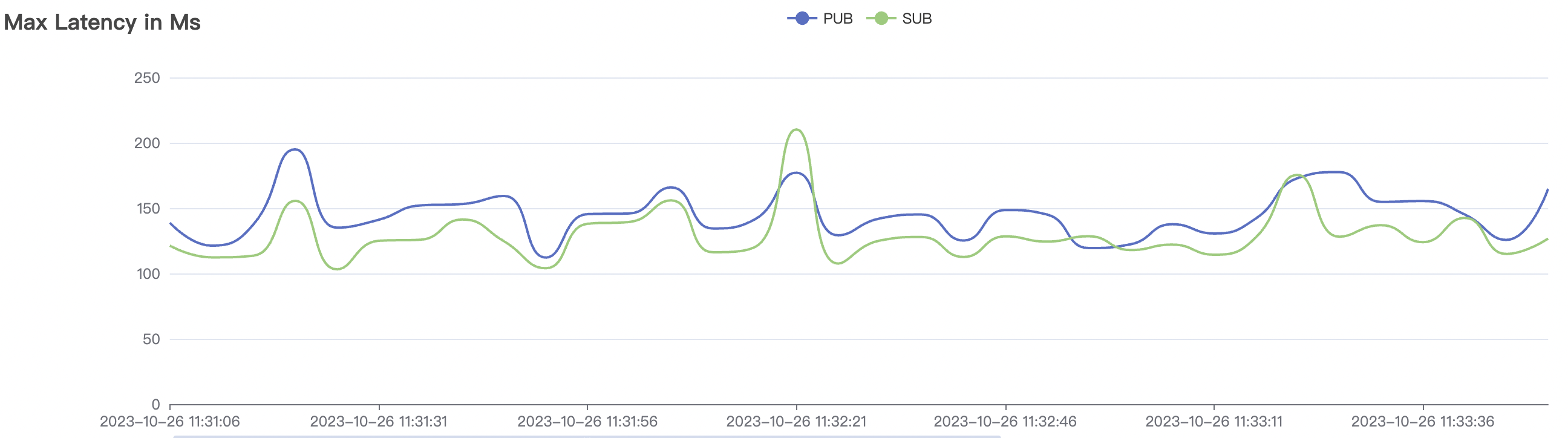
200k_2000_qos1_p256_1mps_3n场景附图:
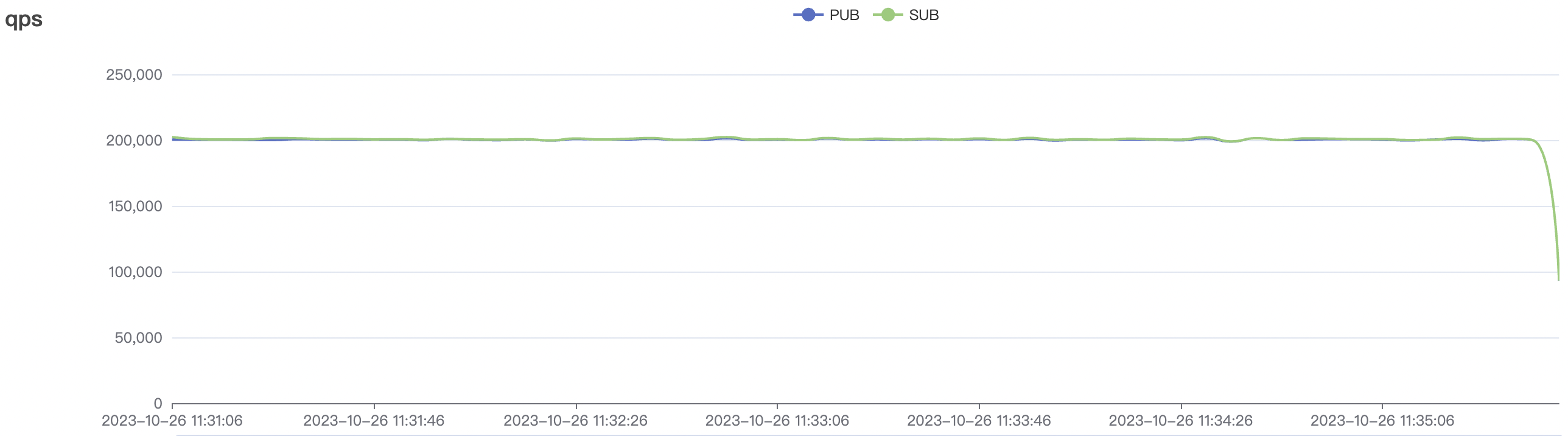 | 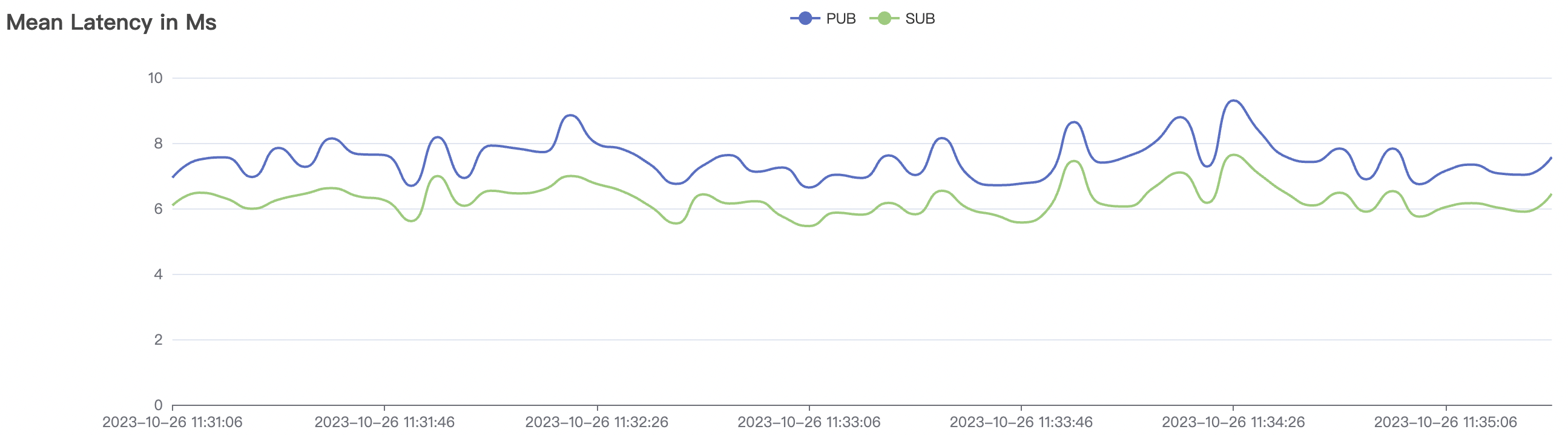 |
|---|---|
 |  |
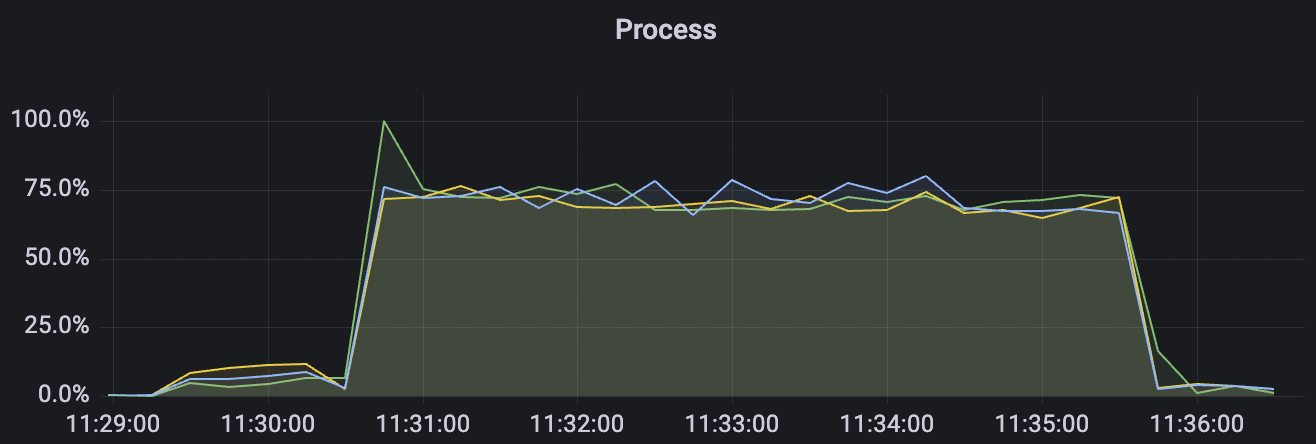 | 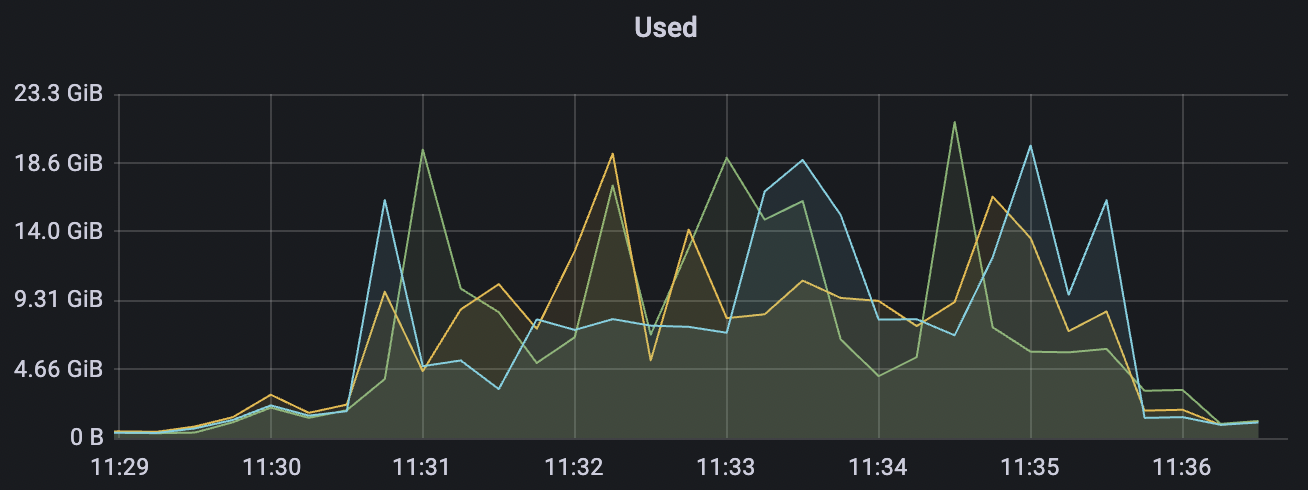 |
fanOut场景
少量客户端作为Publisher,大量客户端订阅相同的topic作为Subscriber,形成每条消息被大规模fanOut广播的场景。
| 场景组合 | QoS | 单连接m/s | 消息byte | 连接数C | 总消息m/s | 平均响应时间ms | P99响应时间ms | CPU | 内存占用GB |
|---|---|---|---|---|---|---|---|---|---|
| 1_100000_qos0_p256_1mps_1n | 0 | 1 | 256 | 100k | 100k | 282.61 | 465.57 | 15% | 2 ~ 5 |
| 1_100000_qos1_p256_1mps_1n | 1 | 1 | 256 | 100k | 100k | 312.11 | 515.9 | 20% | 2 ~ 7 |
| 1_300000_qos0_p256_1mps_3n | 0 | 1 | 256 | 300k | 300k | 593.23 | 889.19 | 20% | 2 ~ 10 |
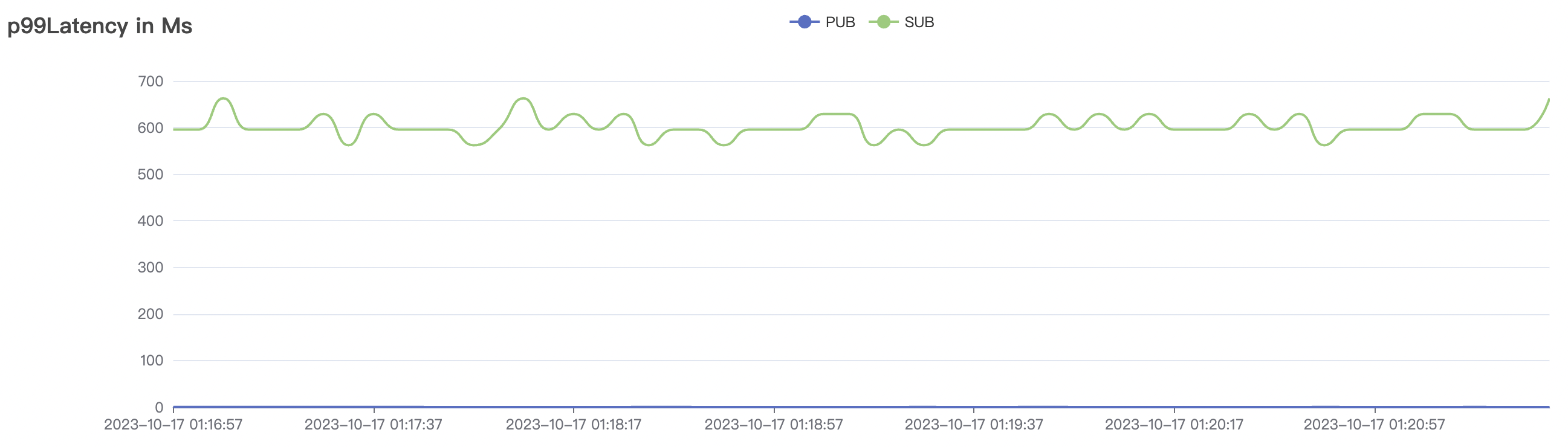
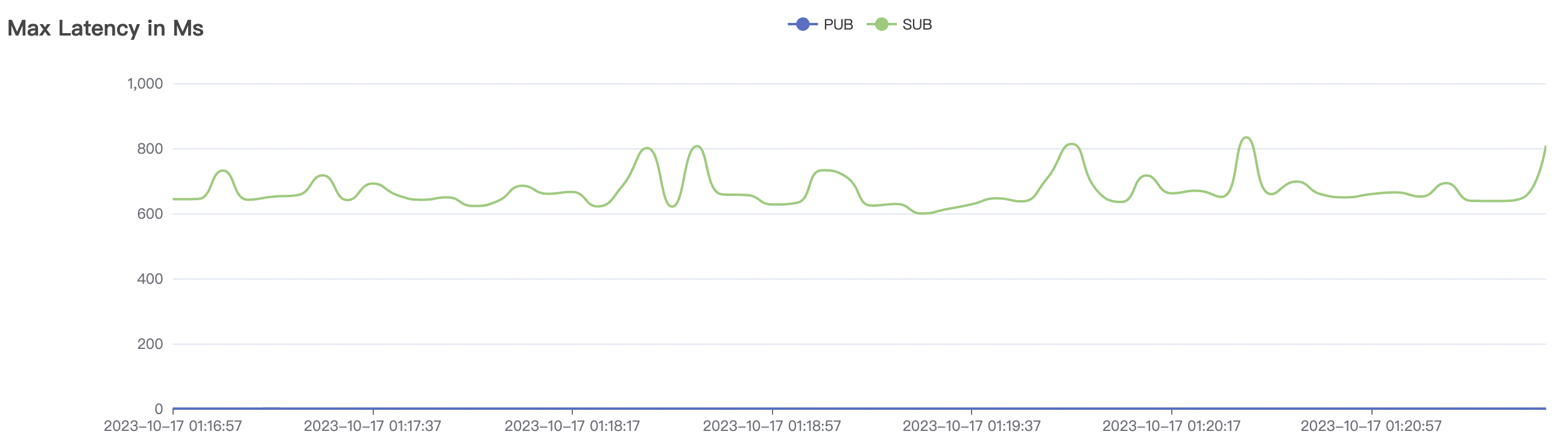
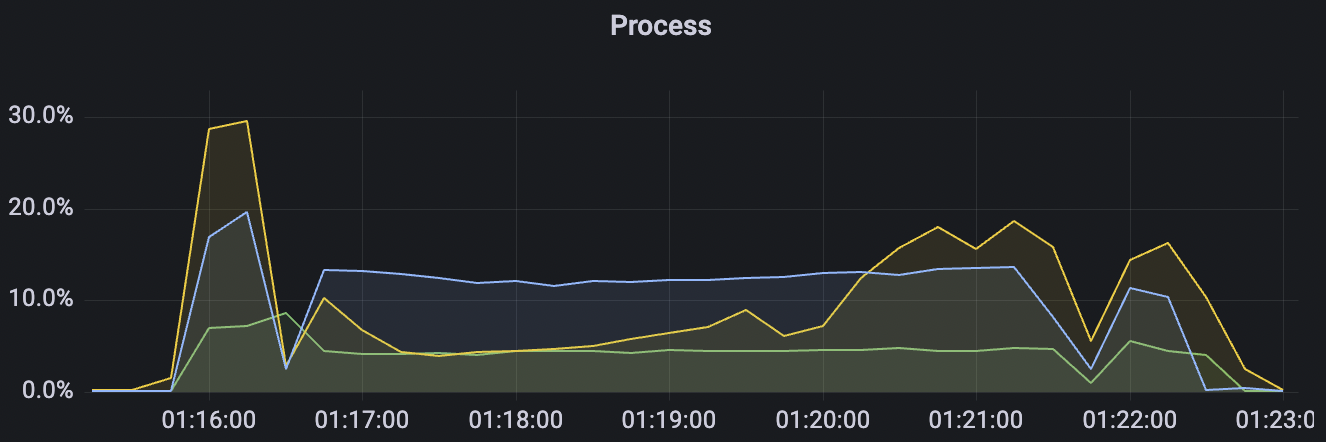
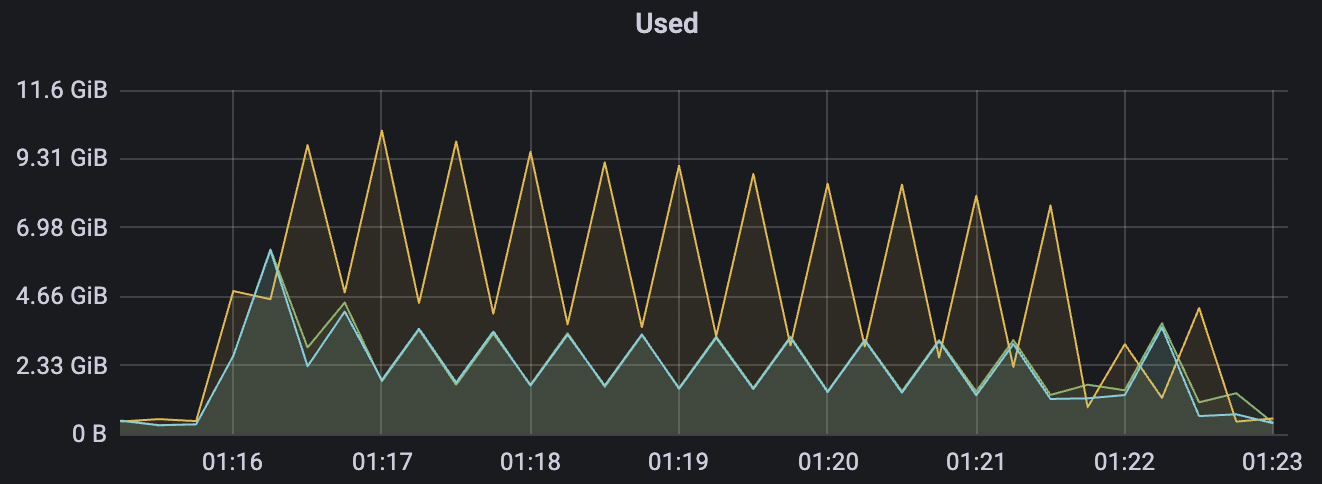
| 1_200000_qos1_p256_1mps_3n | 1 | 1 | 256 | 200k | 200k | 395.96 | 595.59 | 12% | 2~ 8 |
1_100000_qos0_p256_1mps_1n场景附图:
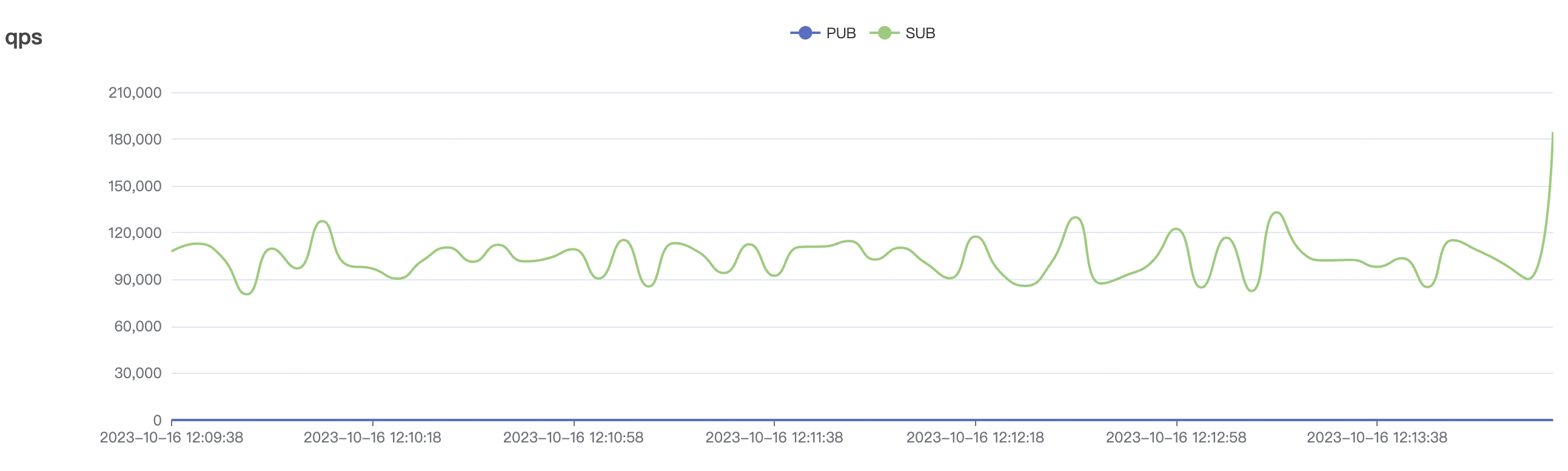 | 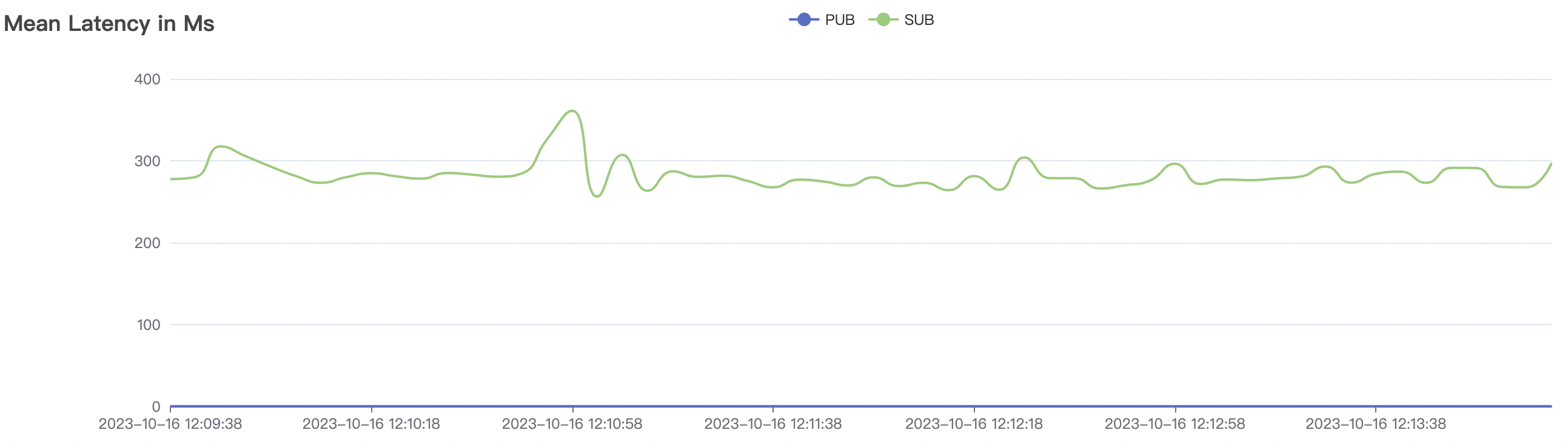 |
|---|---|
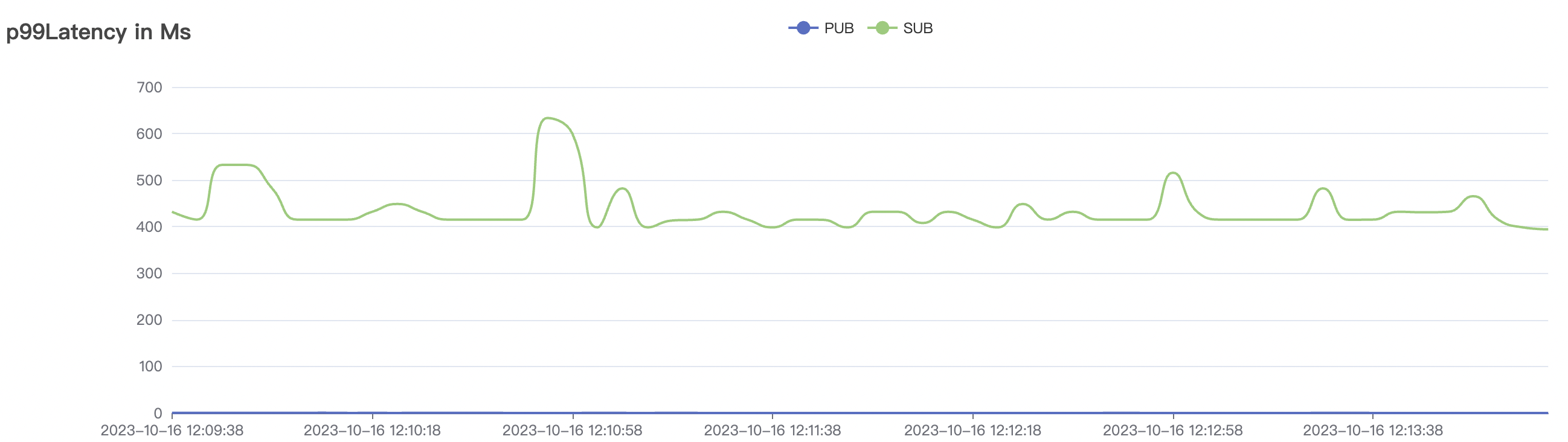 | 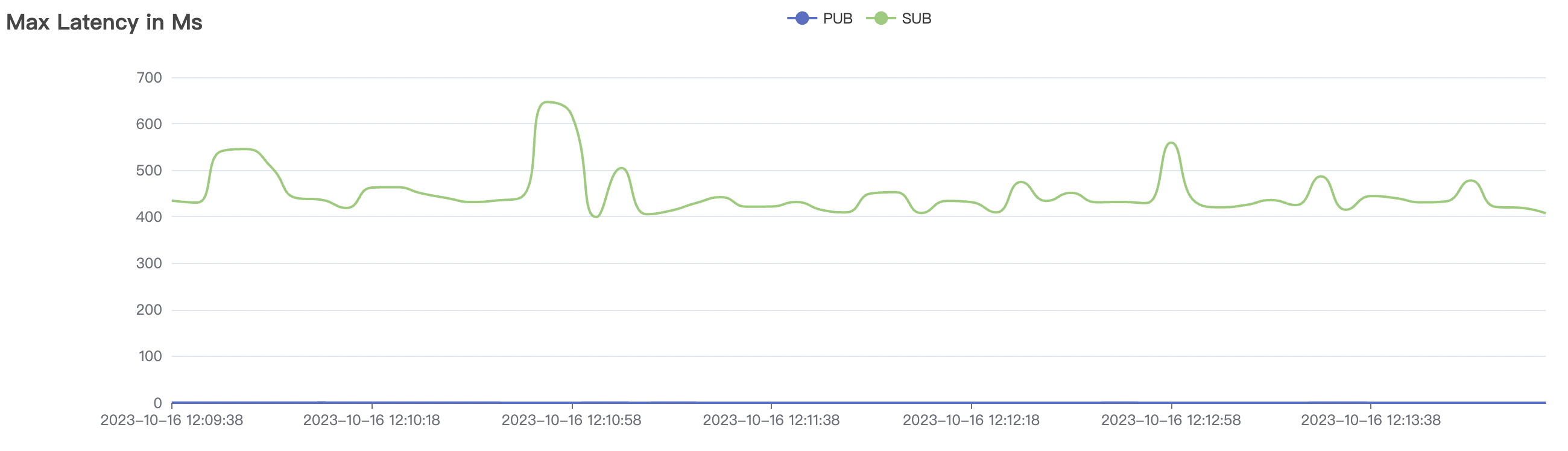 |
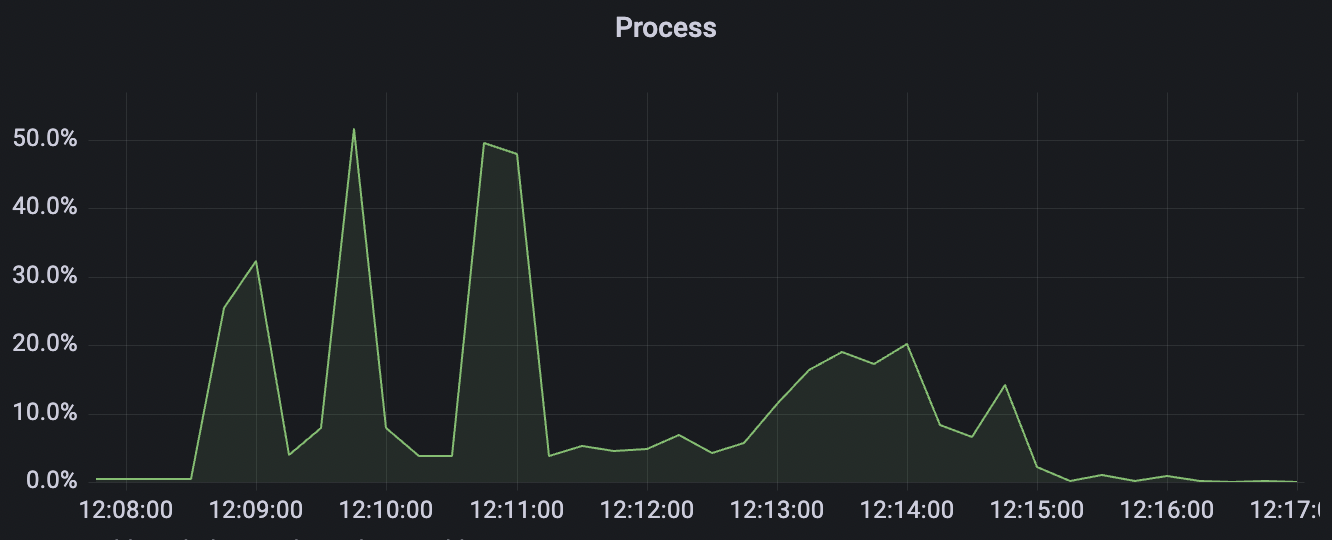 | 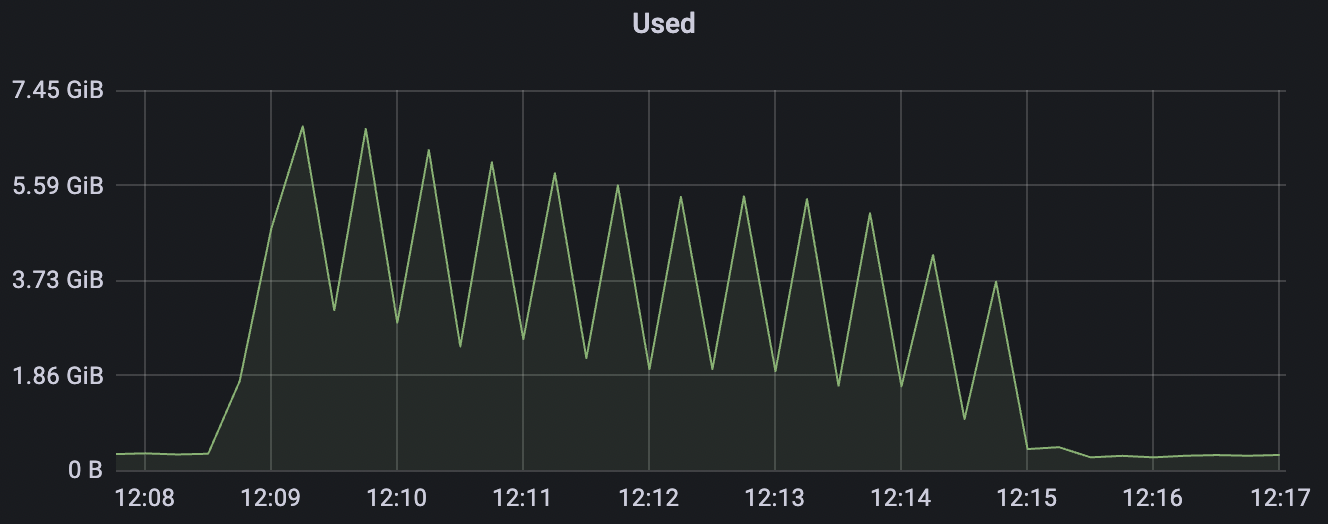 |
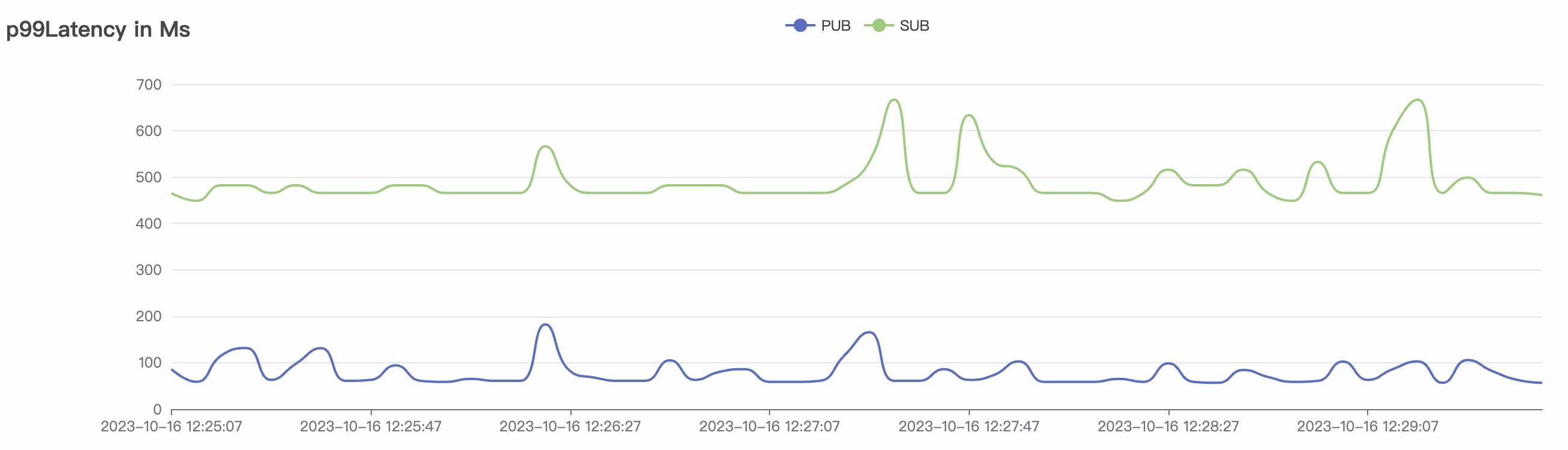
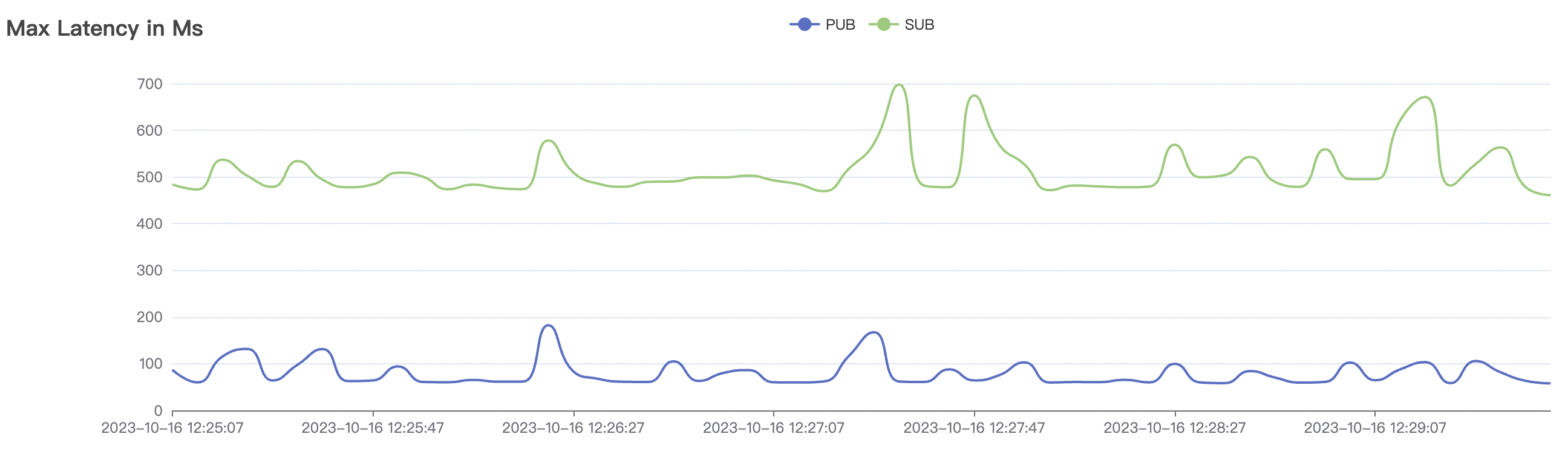
1_100000_qos1_p256_1mps_1n场景附图:
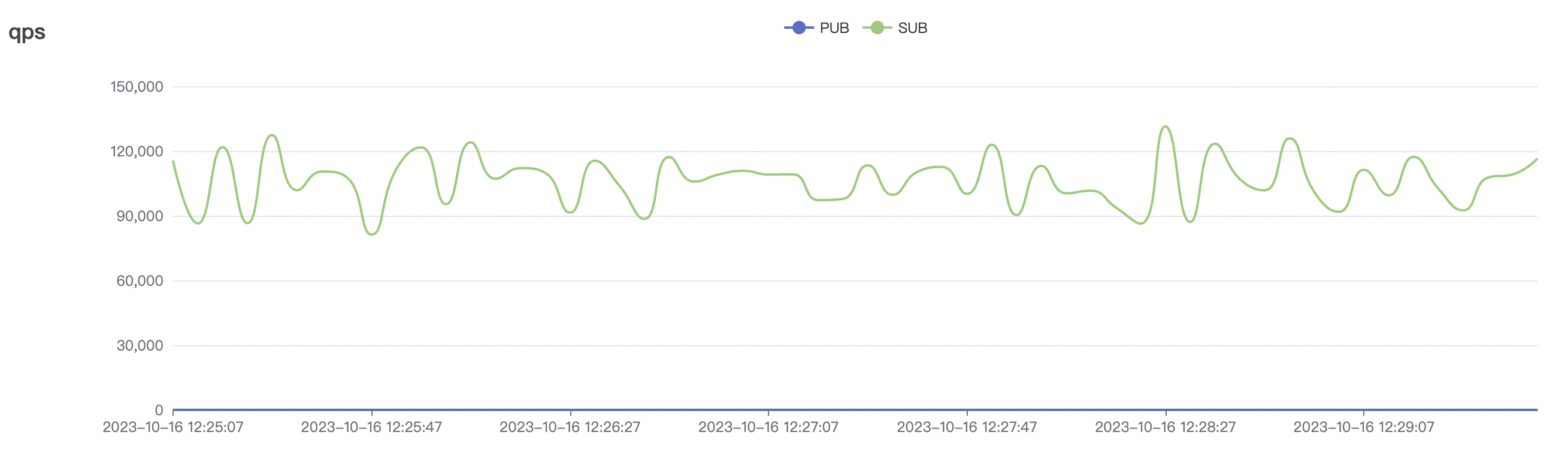 | 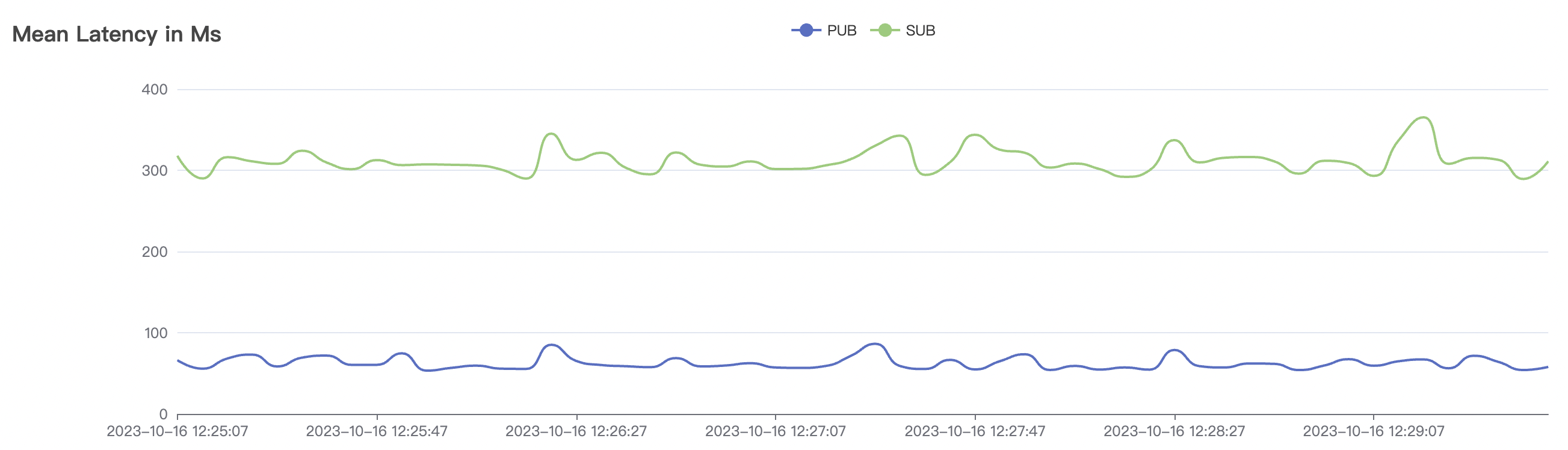 |
|---|---|
 |  |
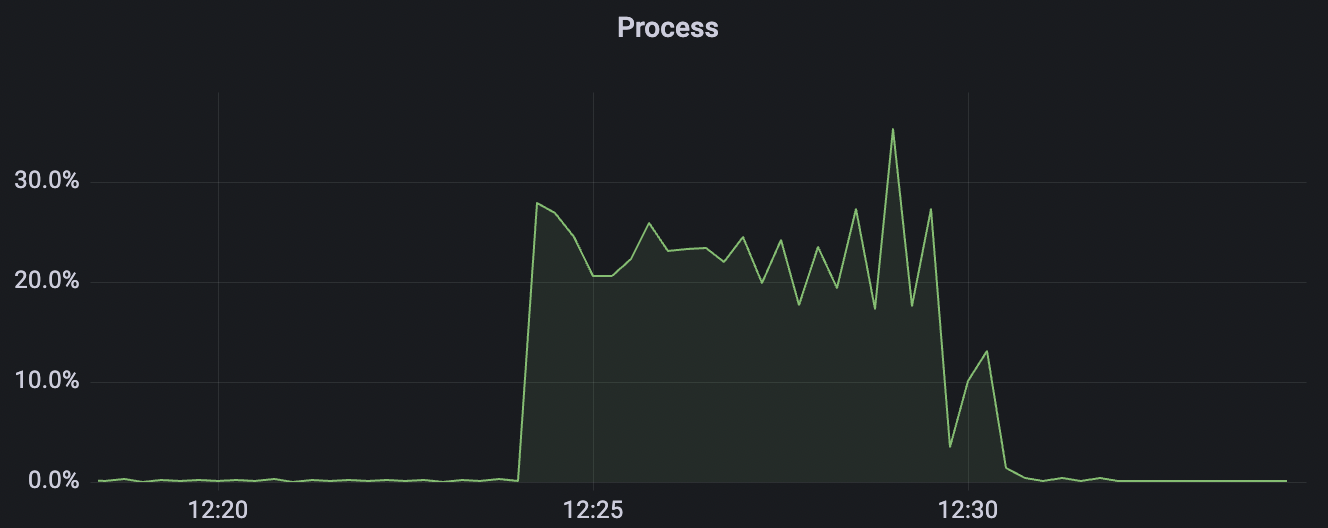 | 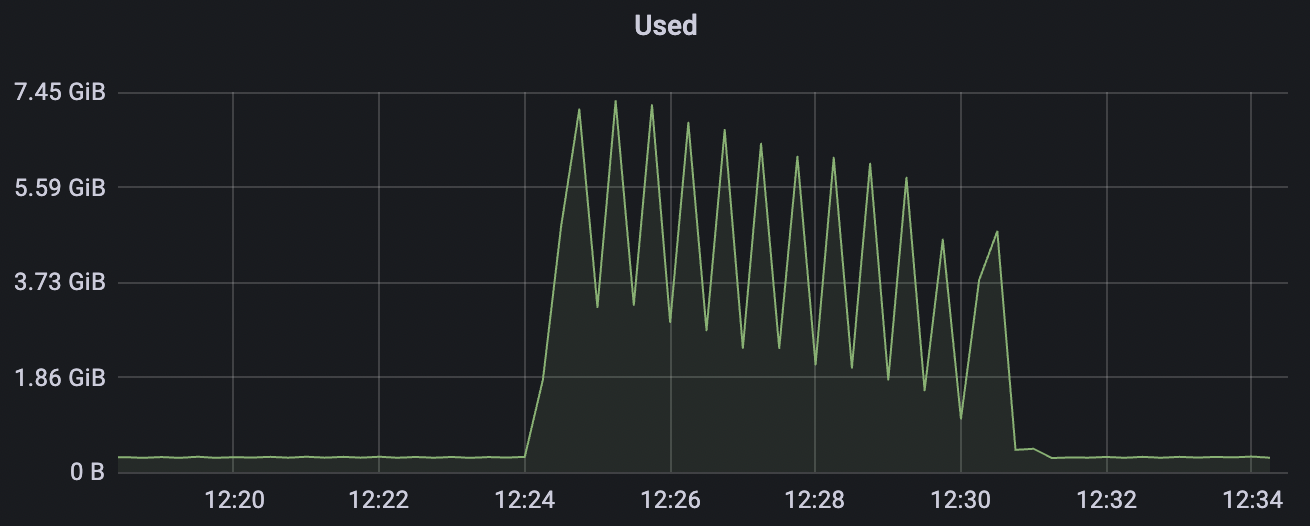 |
1_300000_qos0_p256_1mps_3n场景附图:
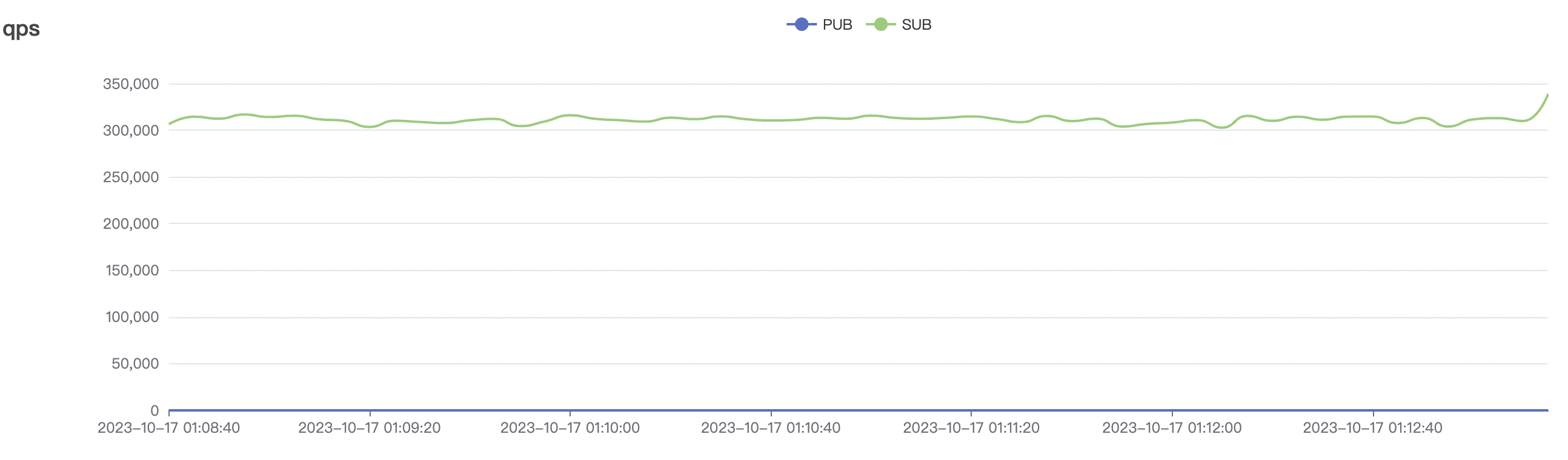 | 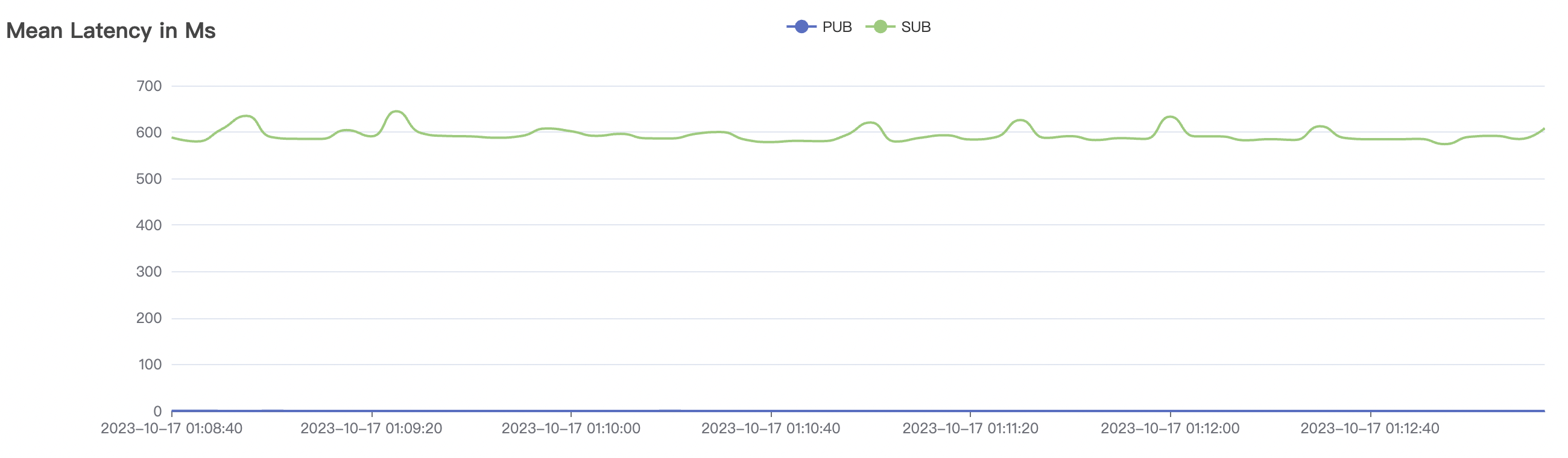 |
|---|---|
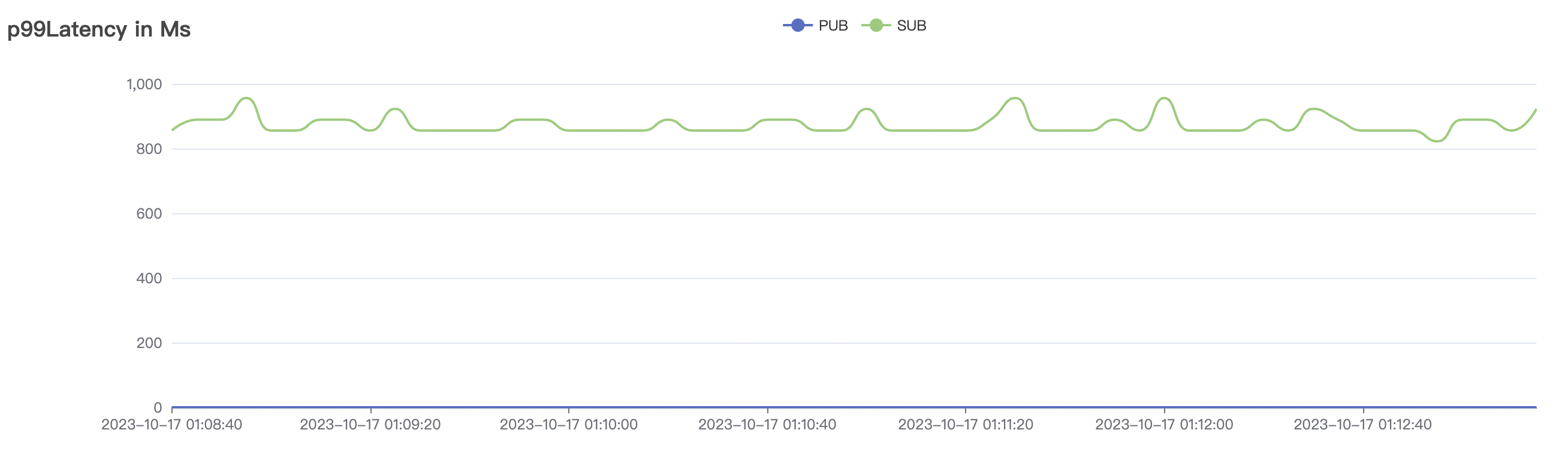 | 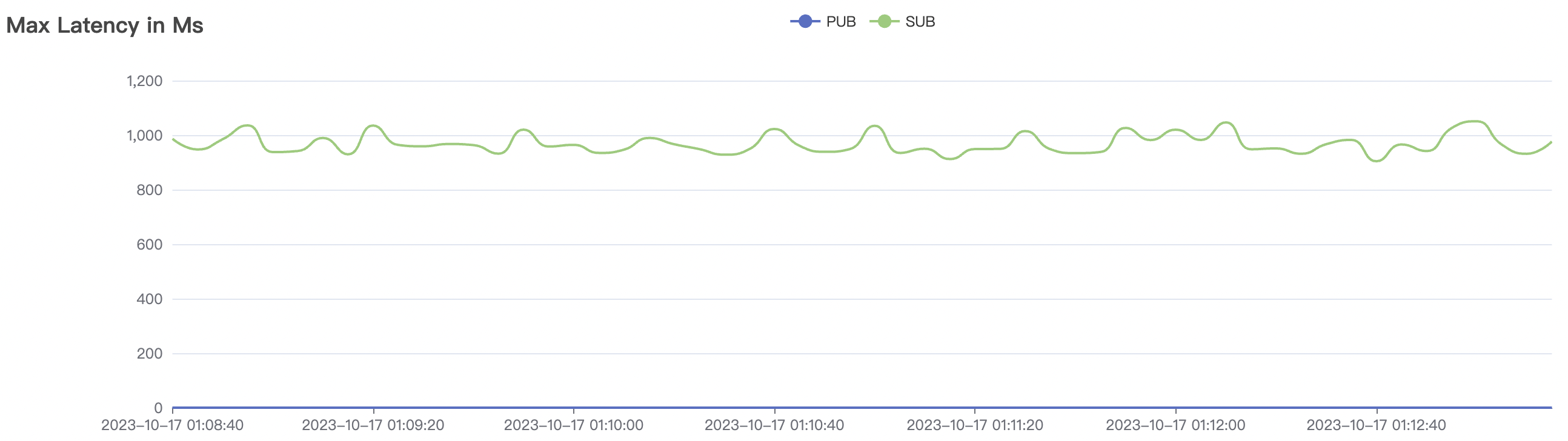 |
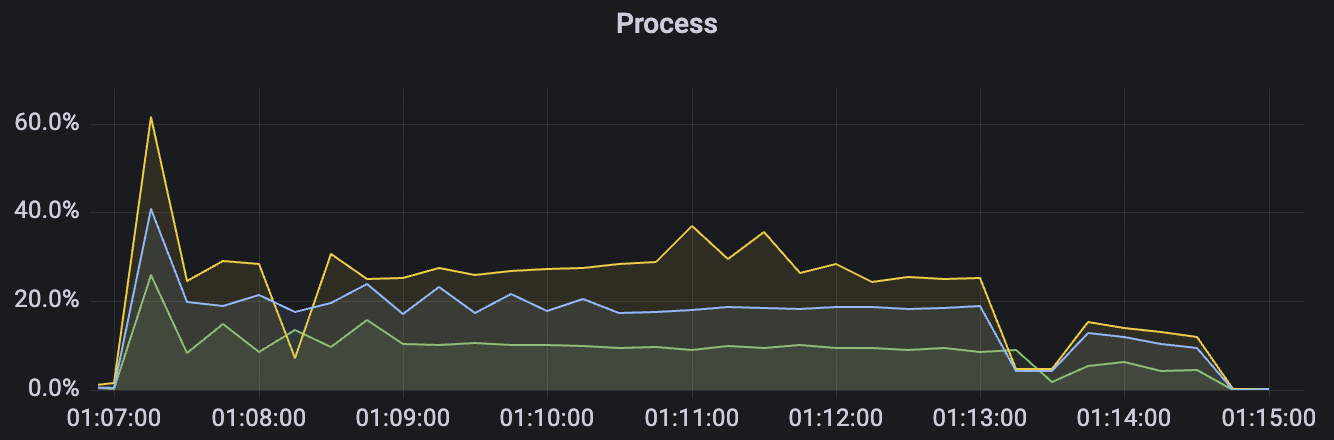 | 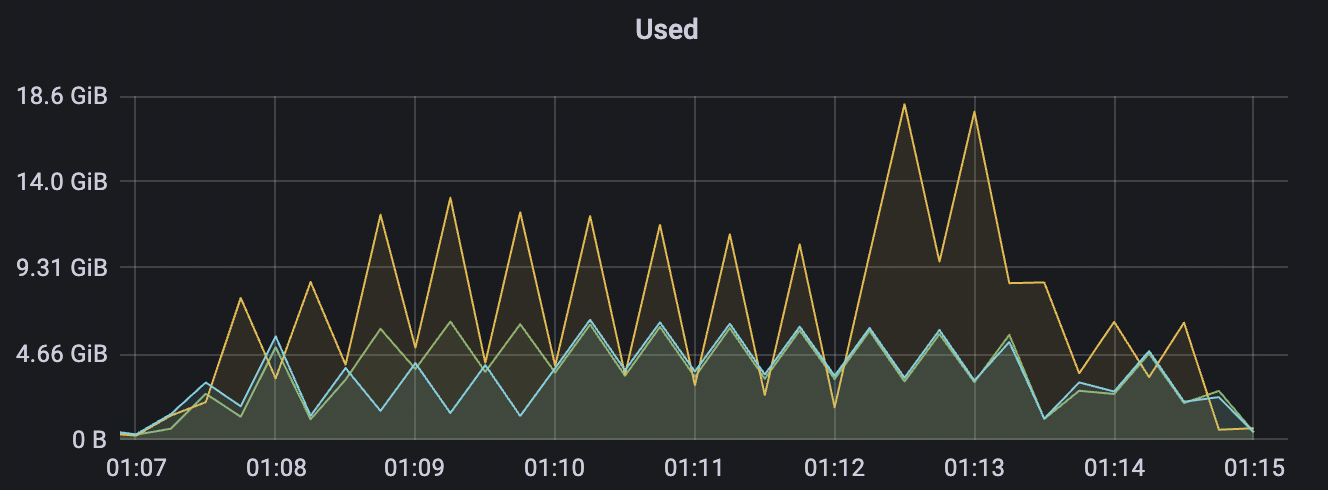 |
1_200000_qos1_p256_1mps_3n场景附图:
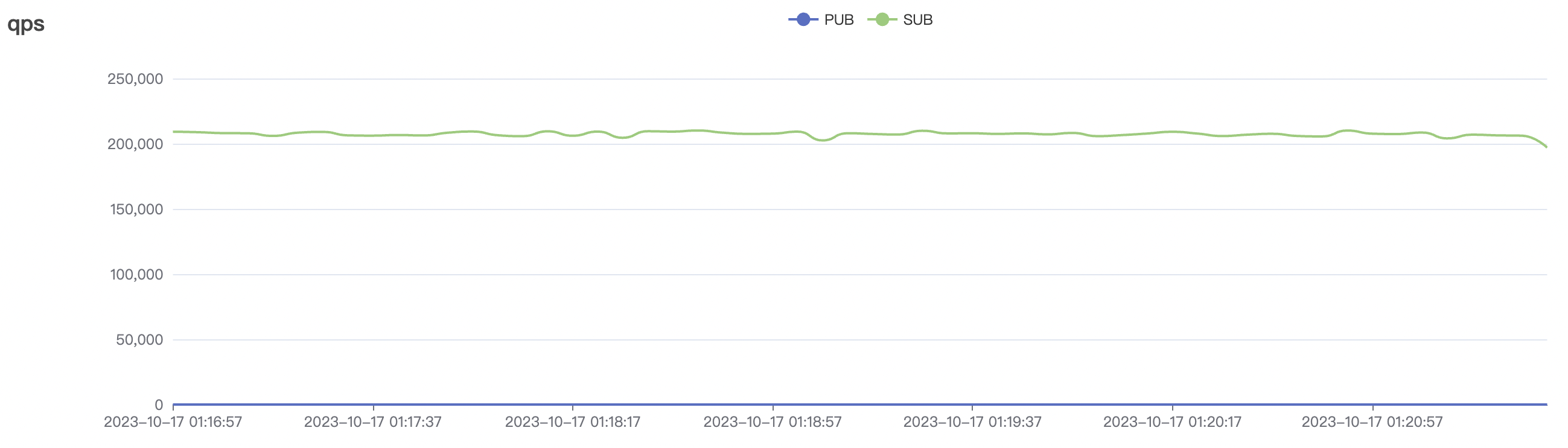 | 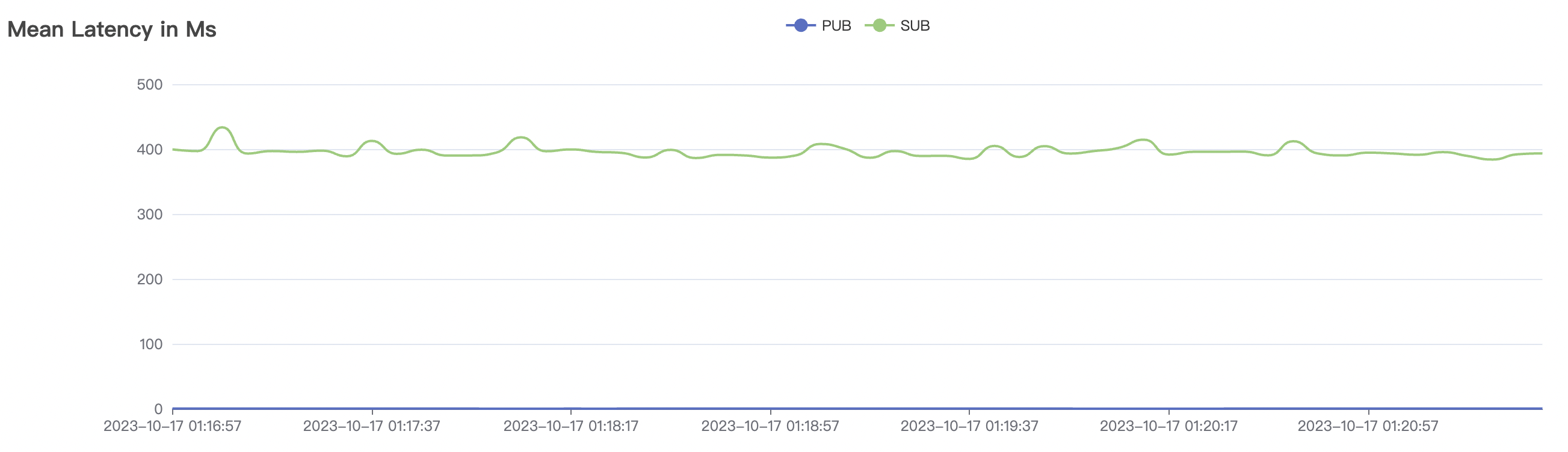 |
|---|---|
 |  |
 |  |
cleanSession=false
1对1 低频场景
| 场景组合 | QoS | 单连接m/s | Payload (byte) | 连接数C | 总消息m/s | 平均响应时间ms | P99响应时间ms | CPU | 内存占用GB |
|---|---|---|---|---|---|---|---|---|---|
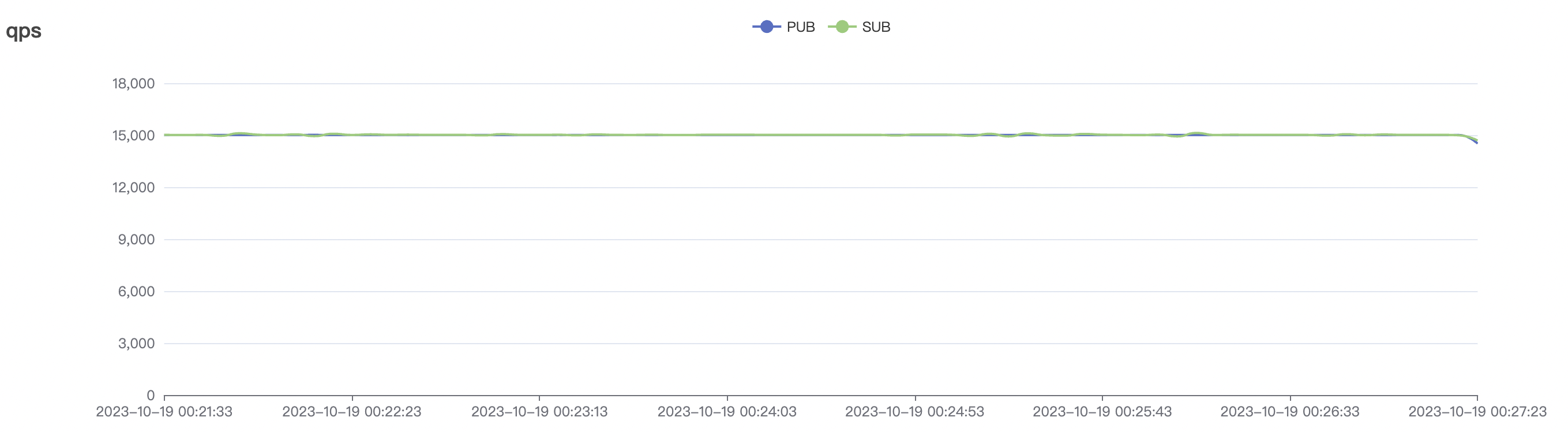
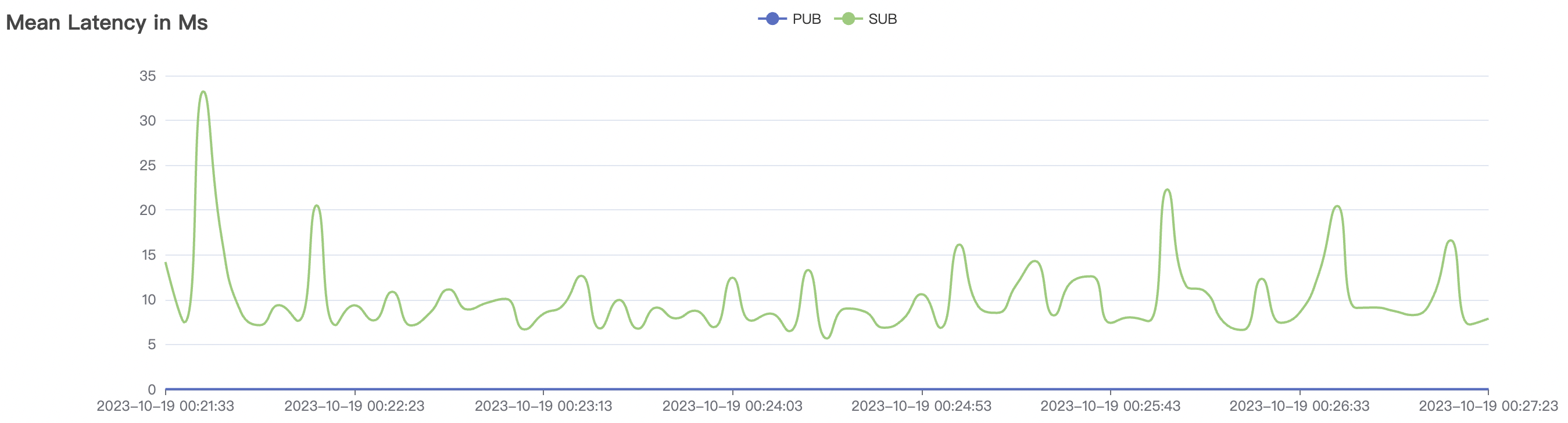
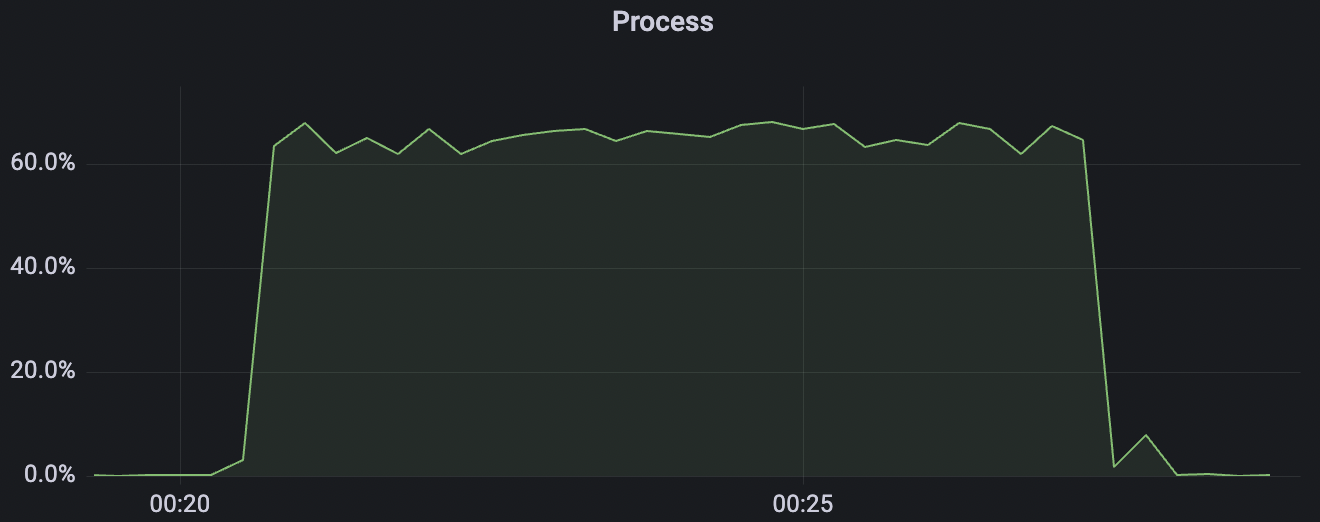
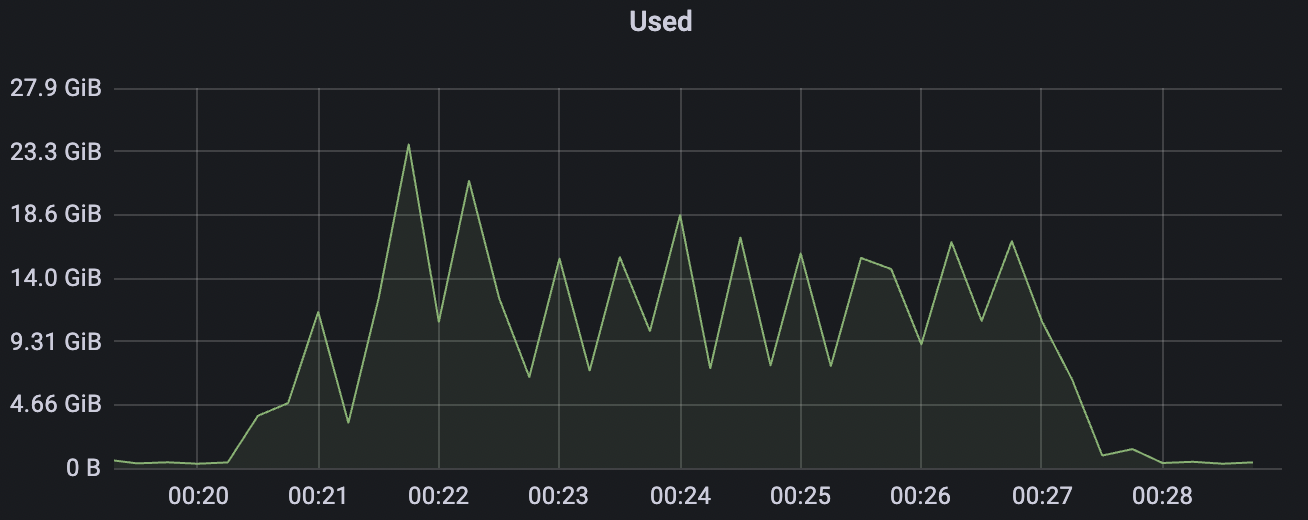
| 15k_15k_qos0_p256_1mps_1n_1v | 0 | 1 | 256 | 20k | 15k | 10.24 | 52.4 | 65% | 5~15 |
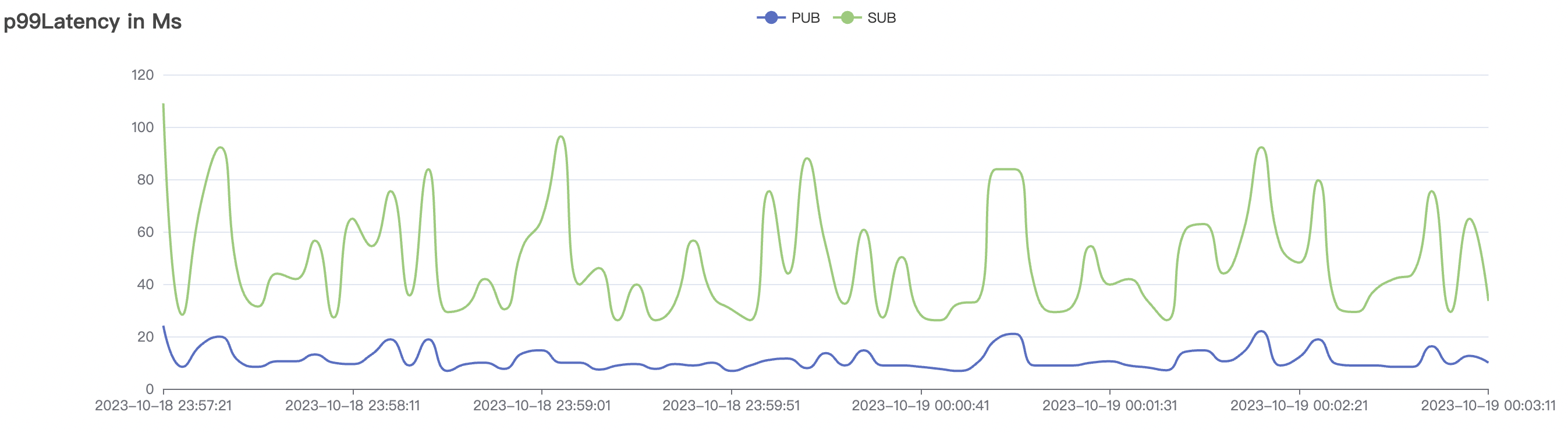
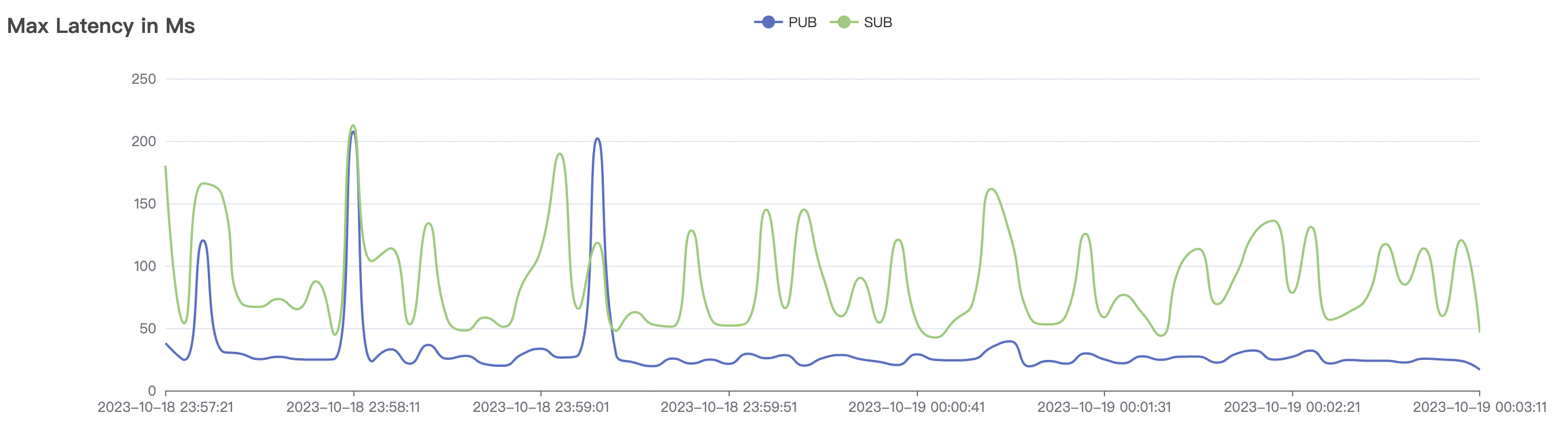
| 15k_15k_qos1_p256_1mps_1n_1v | 1 | 1 | 256 | 20k | 15k | 13.64 | 67.08 | 70% | 5~18 |
| 30k_30k_qos0_p256_1mps_3n_1v | 0 | 1 | 256 | 60k | 30k | 70.34 | 285.18 | 60% | 5~20 |
| 30k_30k_qos1_p256_1mps_3n_1v | 1 | 1 | 256 | 60k | 30k | 90.2 | 352.29 | 62% | 7~20 |
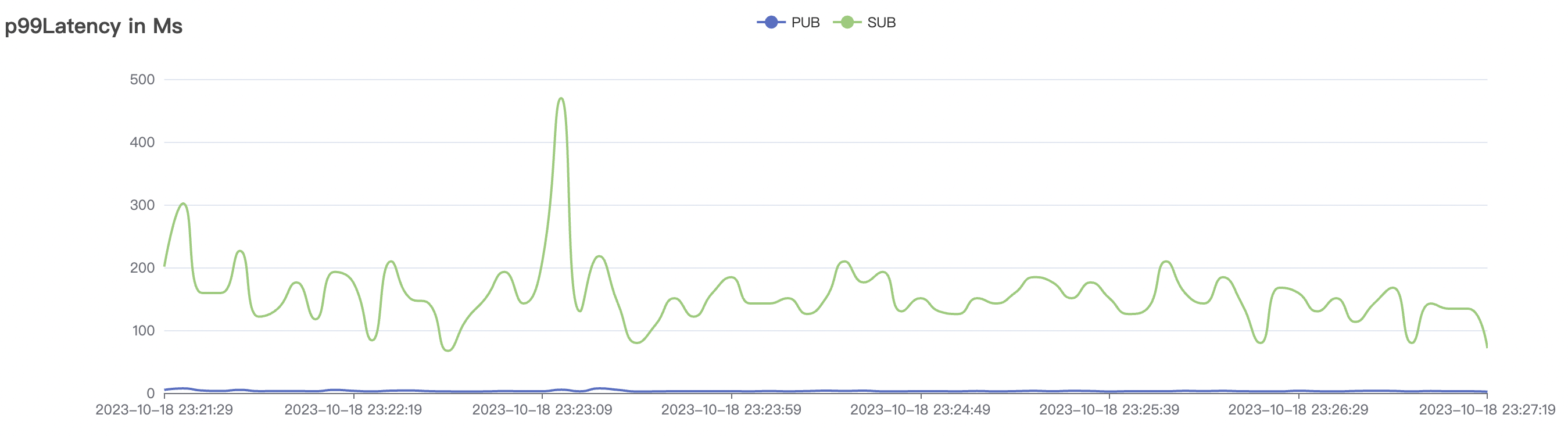
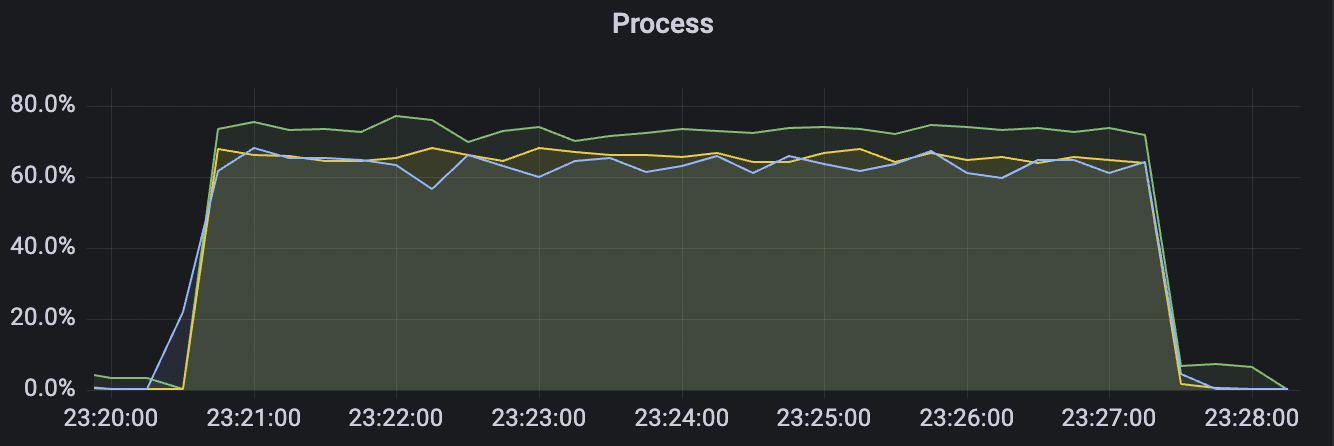
| 15k_15k_qos0_p256_1mps_3n_3v | 0 | 1 | 256 | 30k | 15k | 27.32 | 142.54 | 65% | 5~20 |
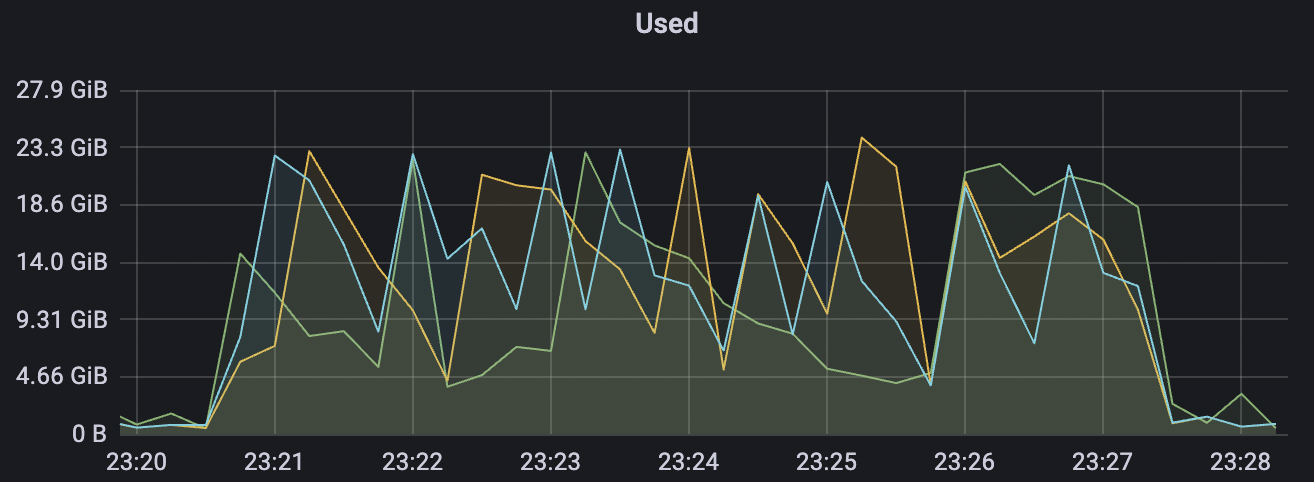
| 15k_15k_qos1_p256_1mps_3n_3v | 1 | 1 | 256 | 30k | 15k | 31.01 | 167.71 | 65% | 5~20 |
15k_15k_qos0_p256_1mps_1n_1v场景附图:
 |  |
|---|---|
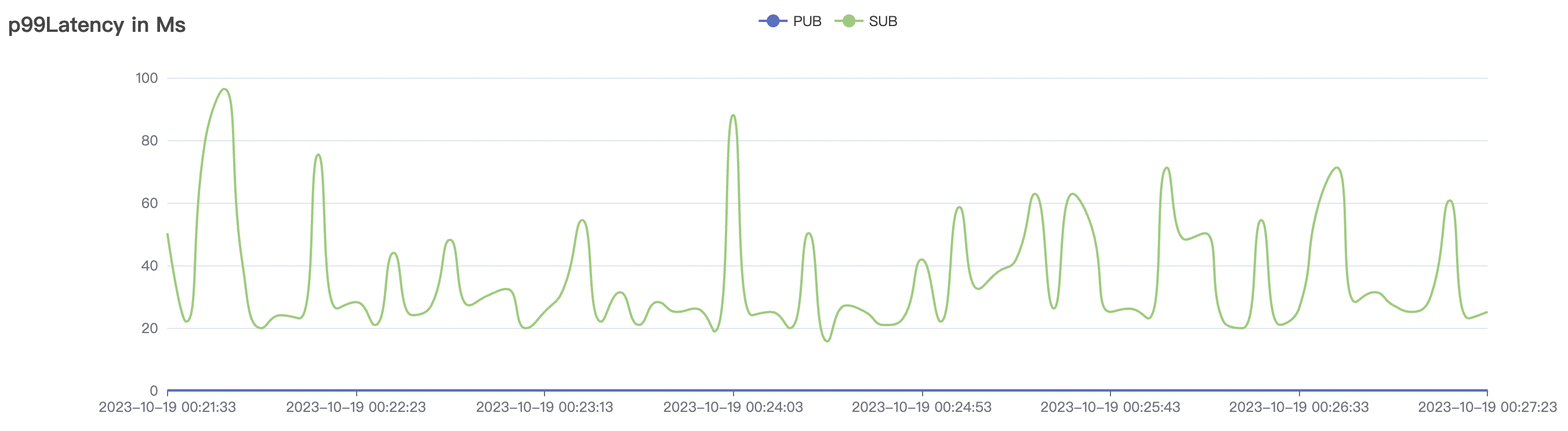 | 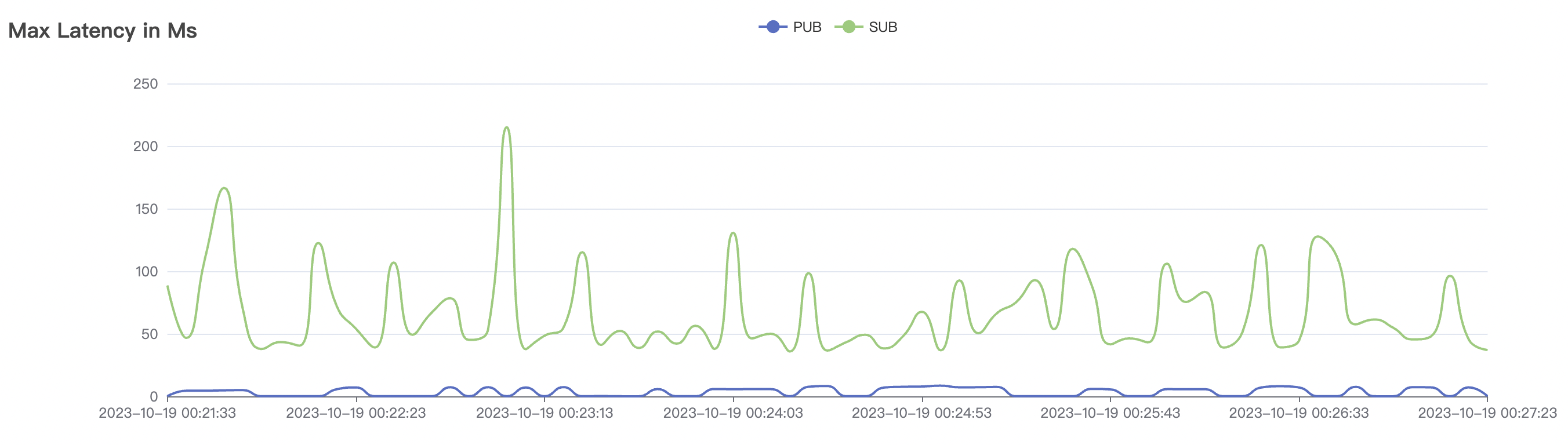 |
 |  |
15k_15k_qos1_p256_1mps_1n_1v场景附图:
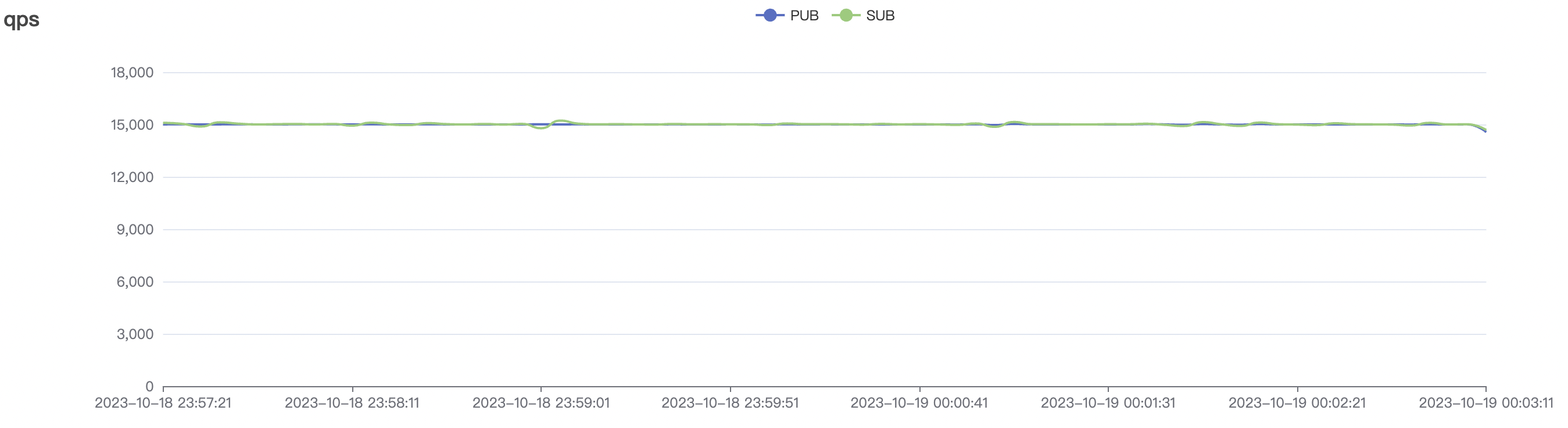 | 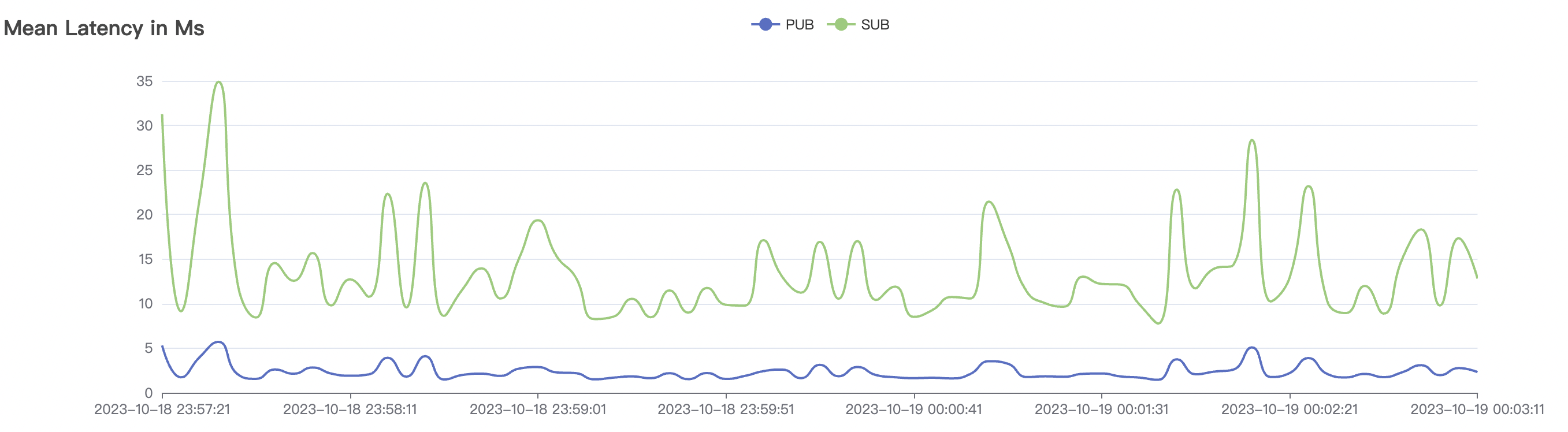 |
|---|---|
 |  |
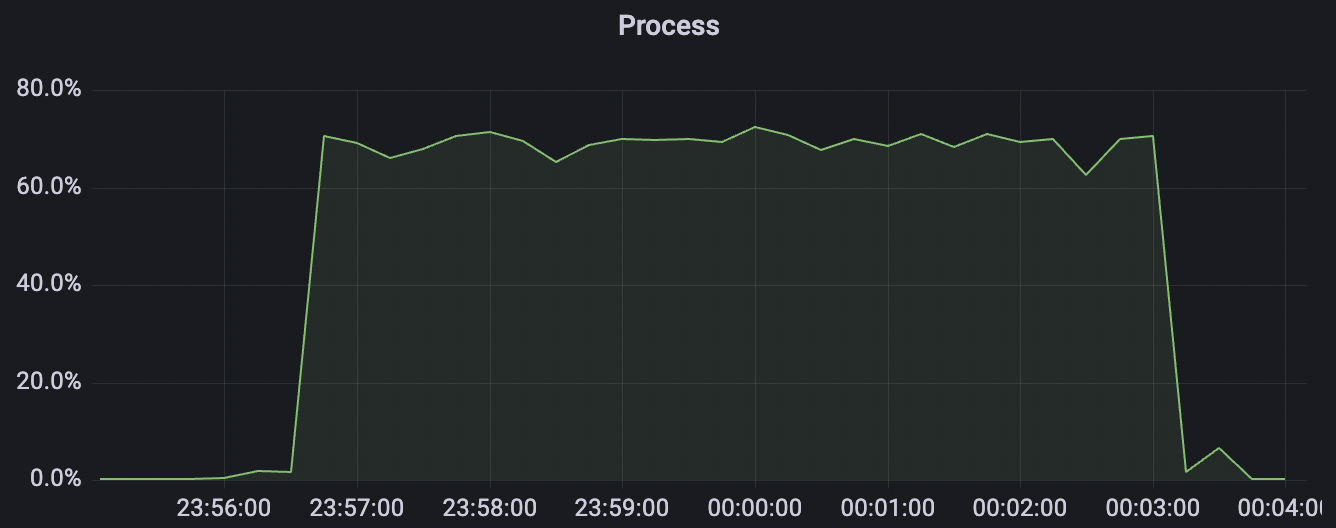 | 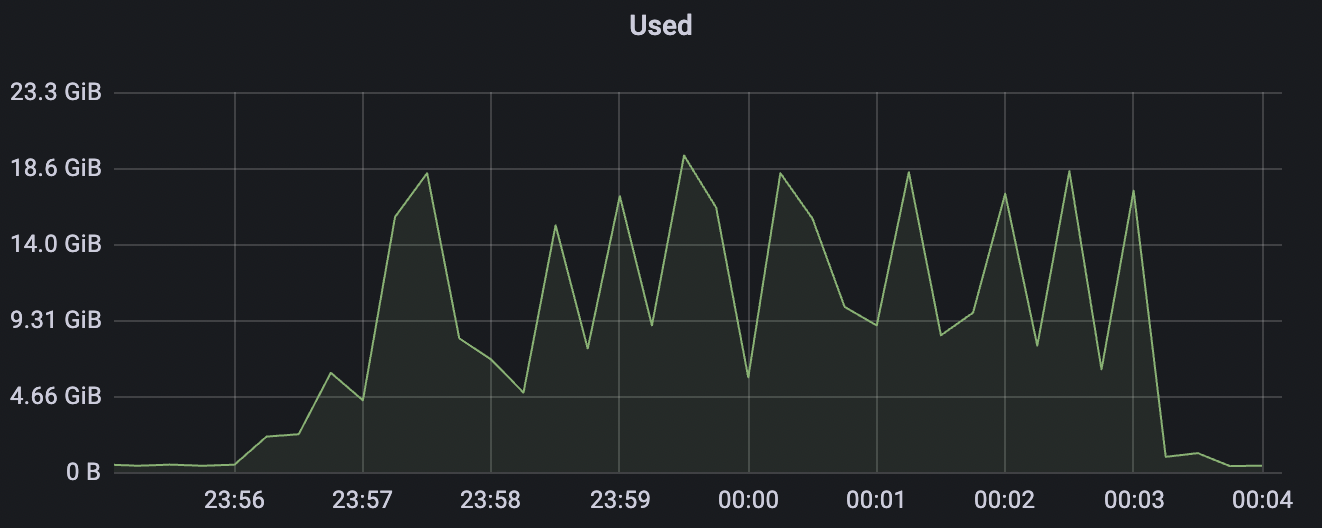 |
30k_30k_qos0_p256_1mps_3n_1v场景附图:
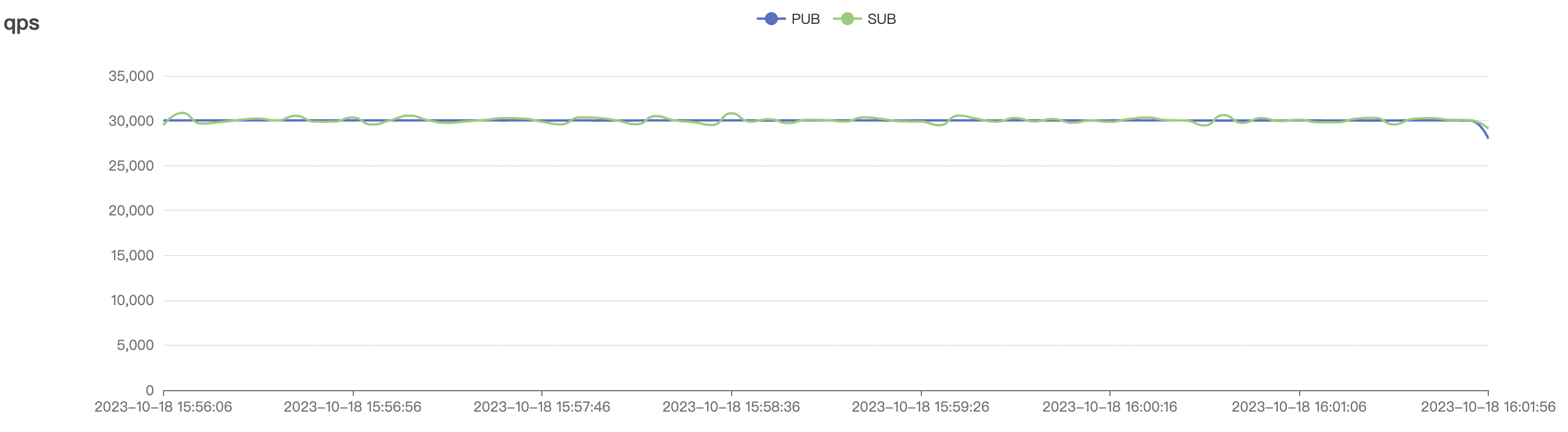 | 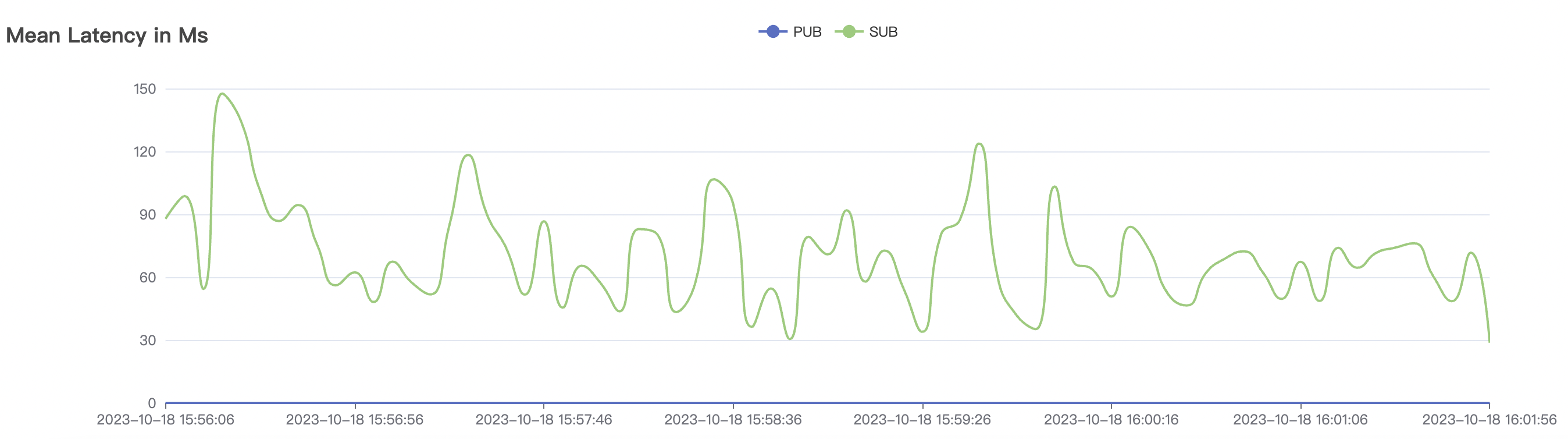 |
|---|---|
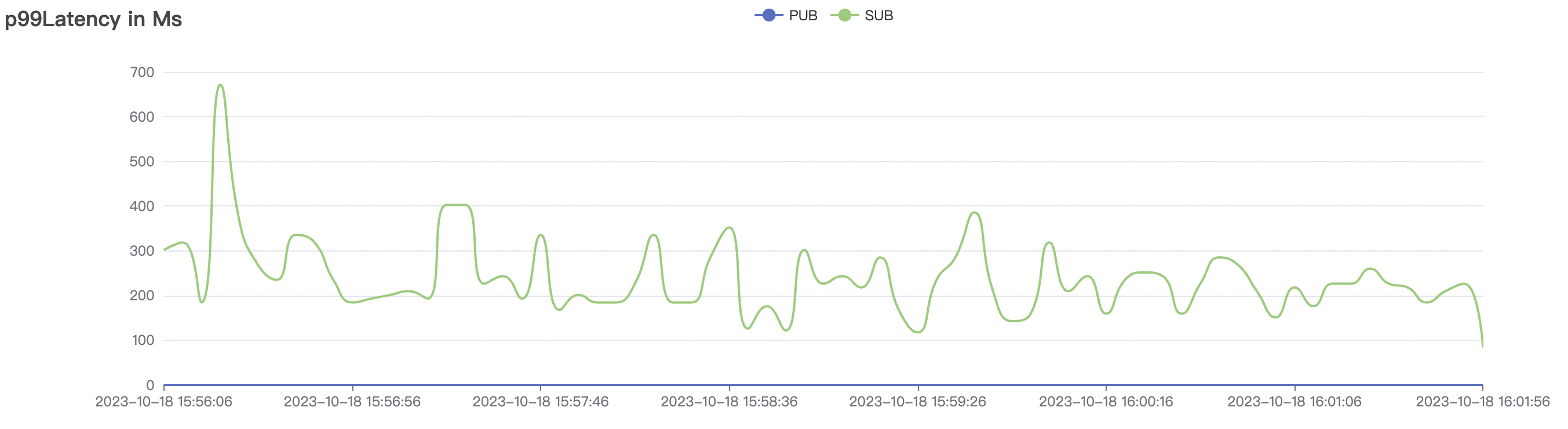 | 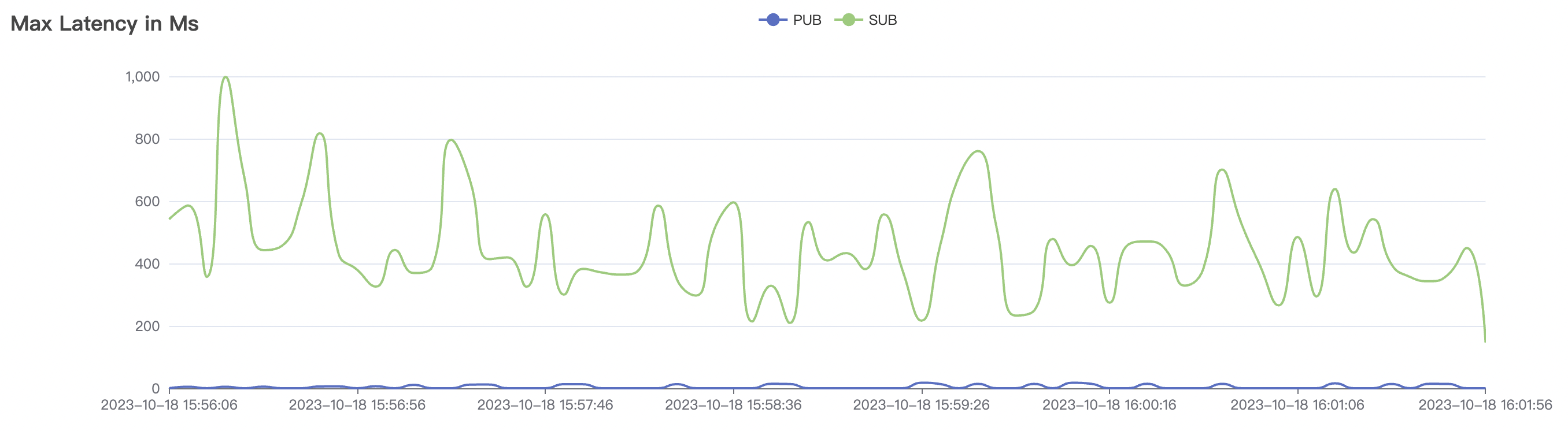 |
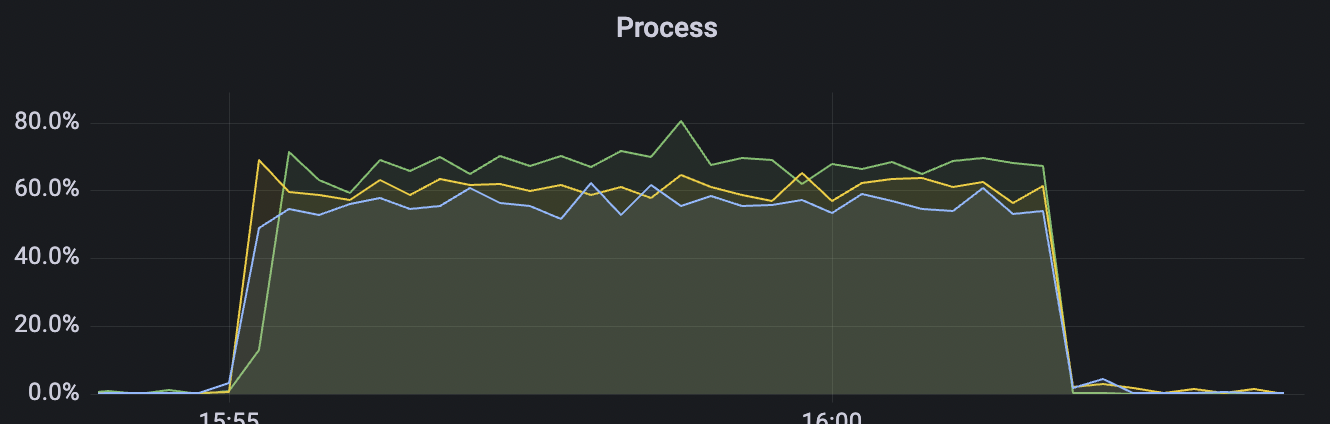 | 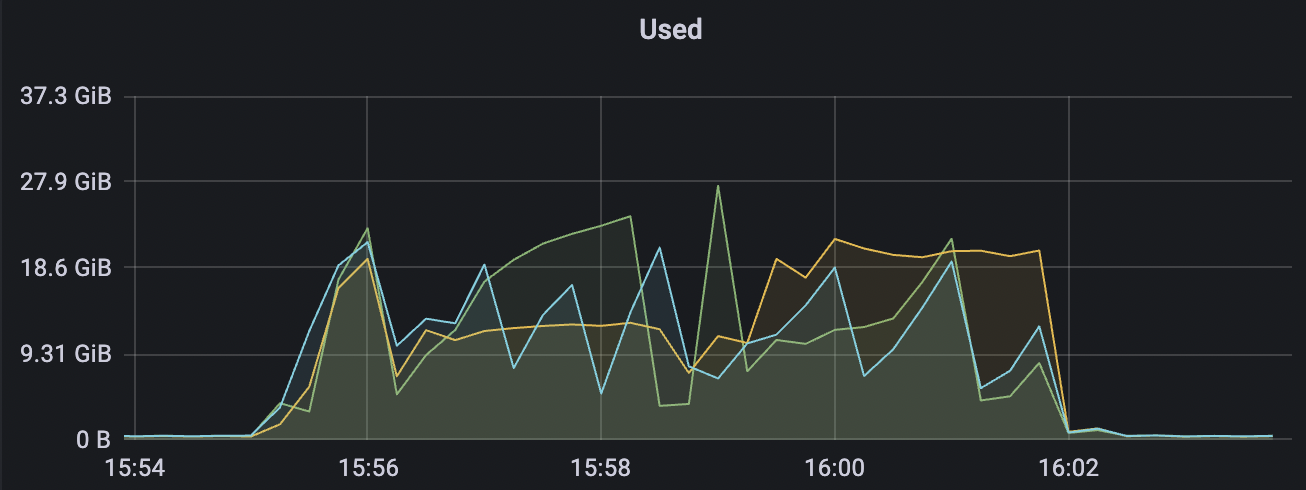 |
30k_30k_qos1_p256_1mps_3n_1v场景附图:
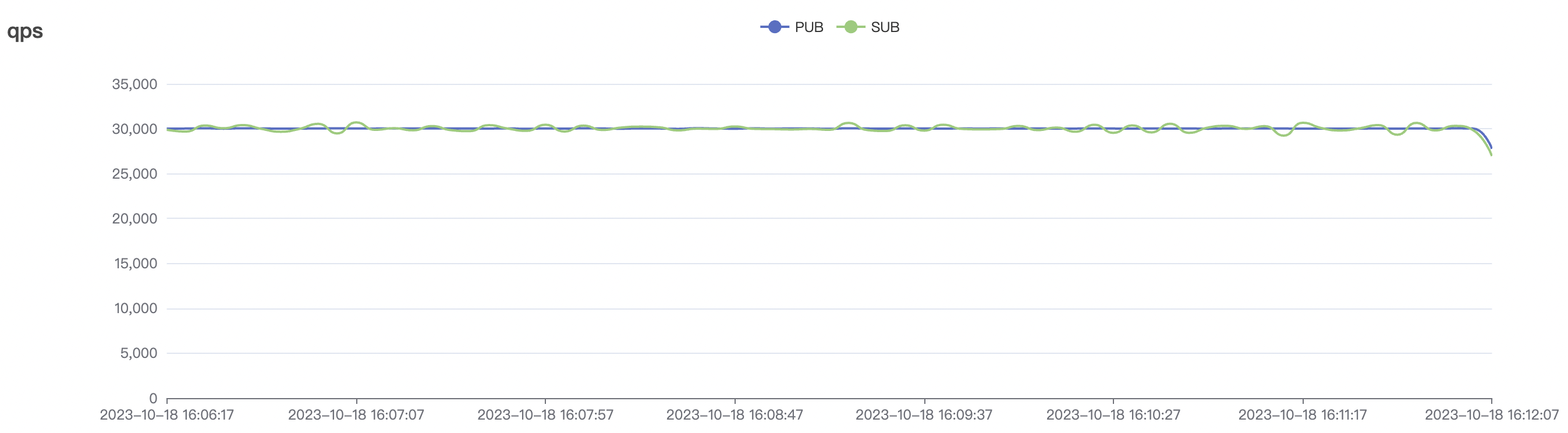 | 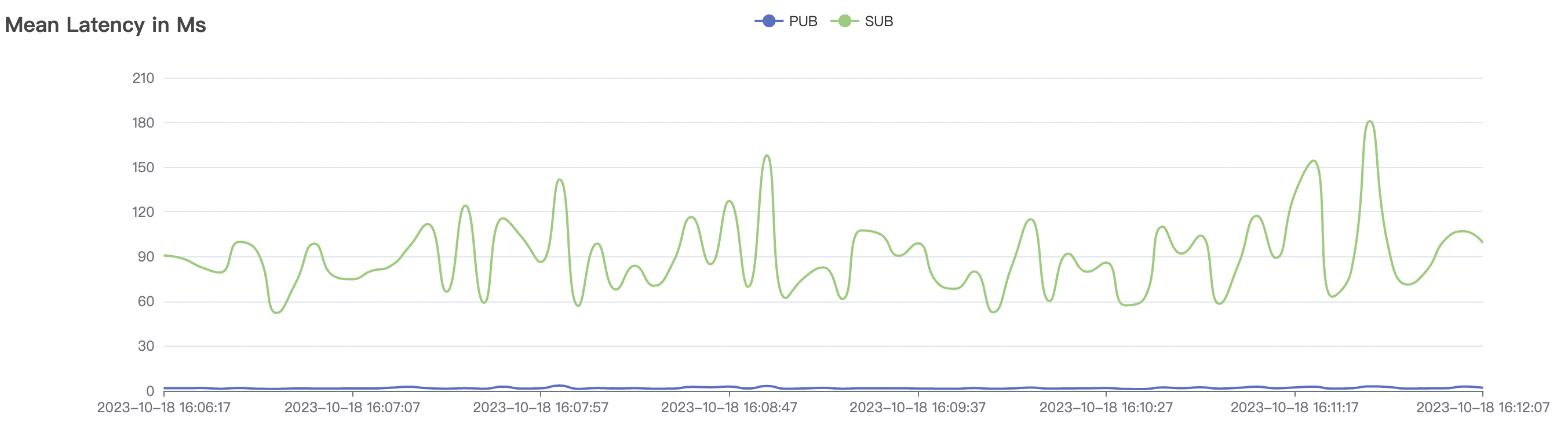 |
|---|---|
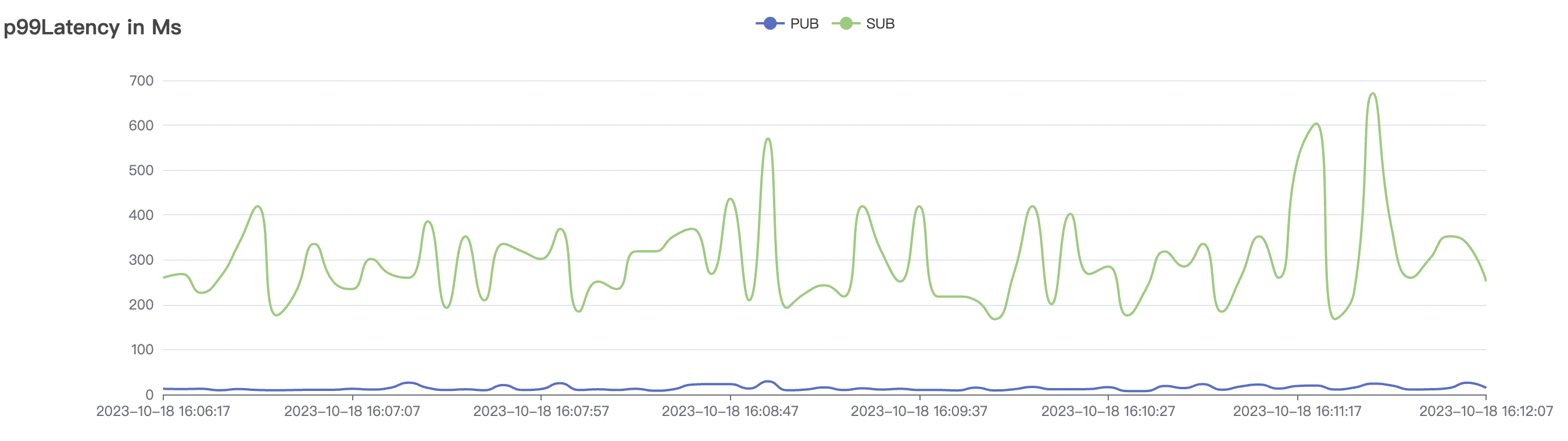 | 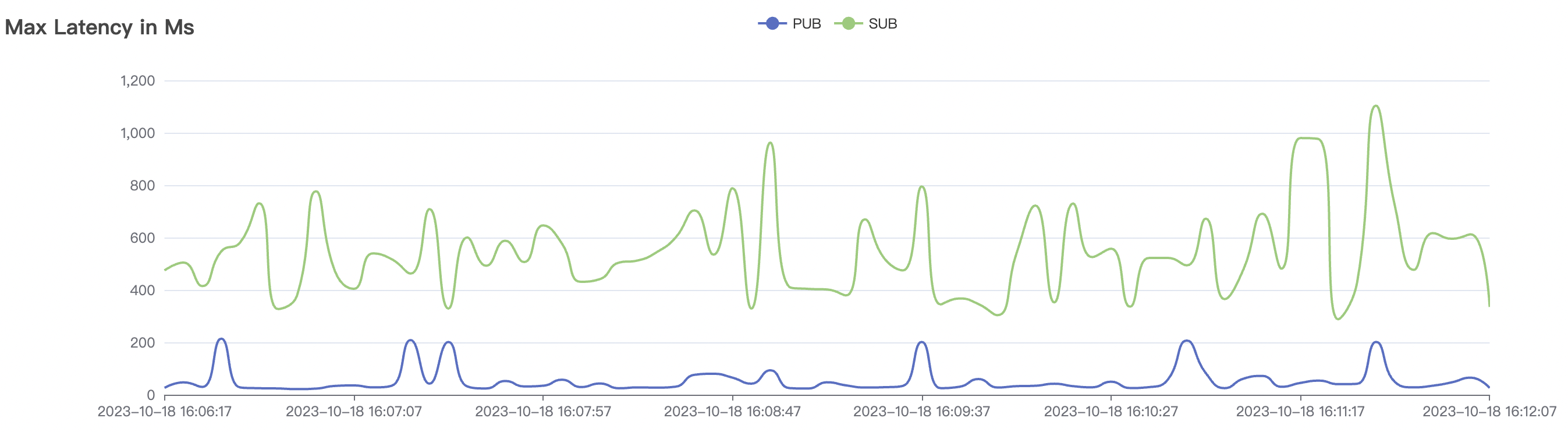 |
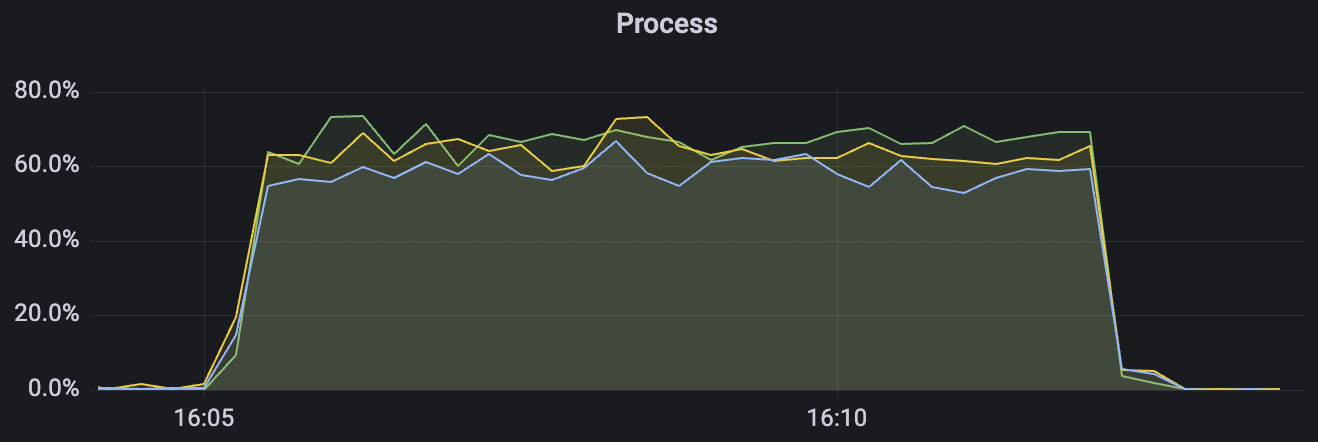 | 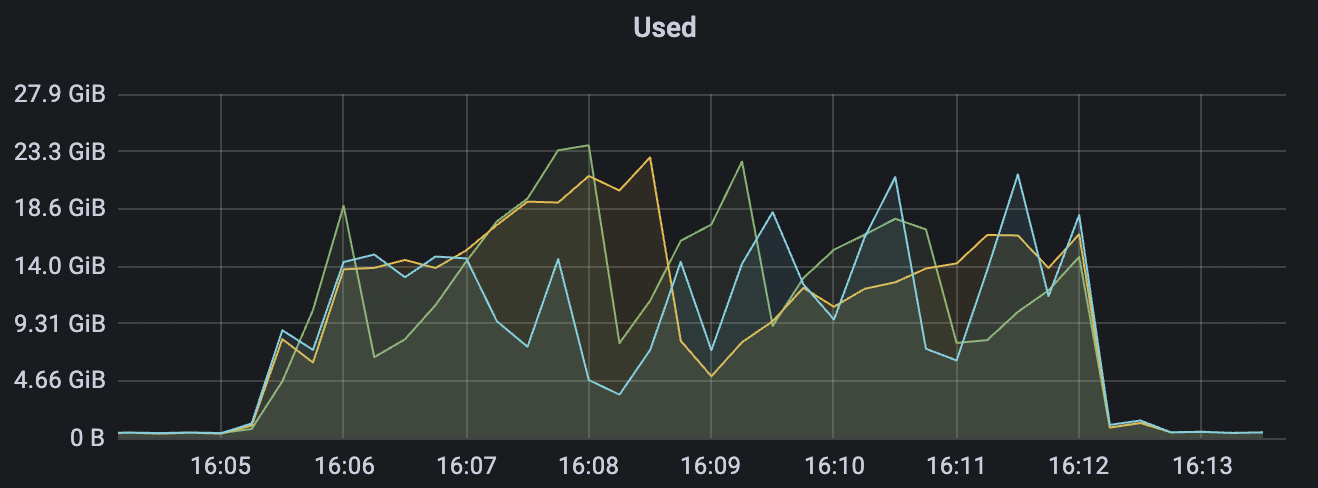 |
15k_15k_qos0_p256_1mps_3n_3v场景附图:
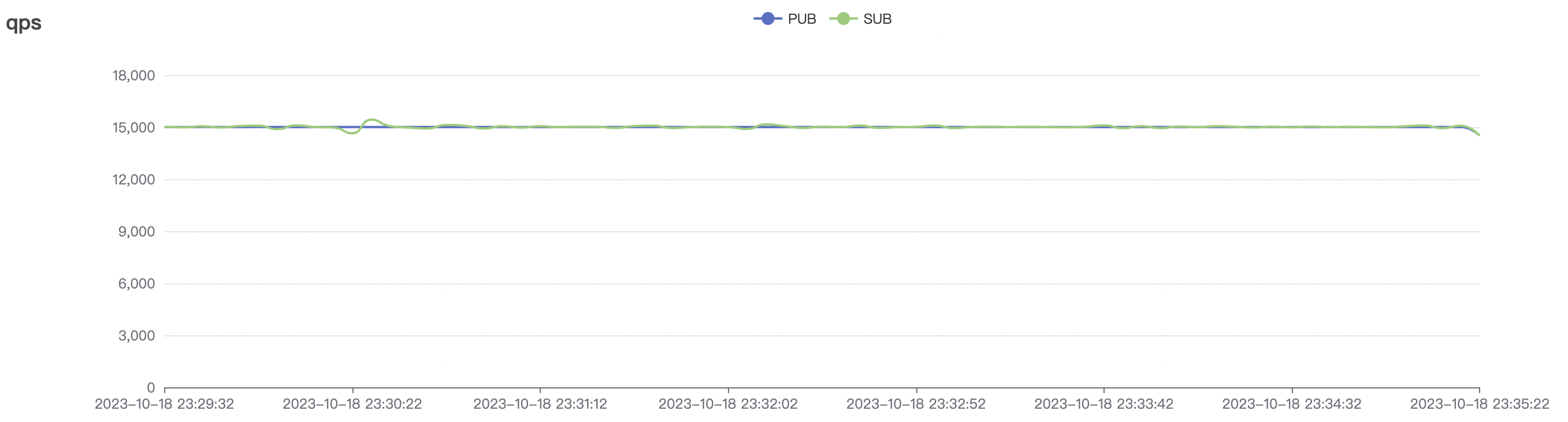 | 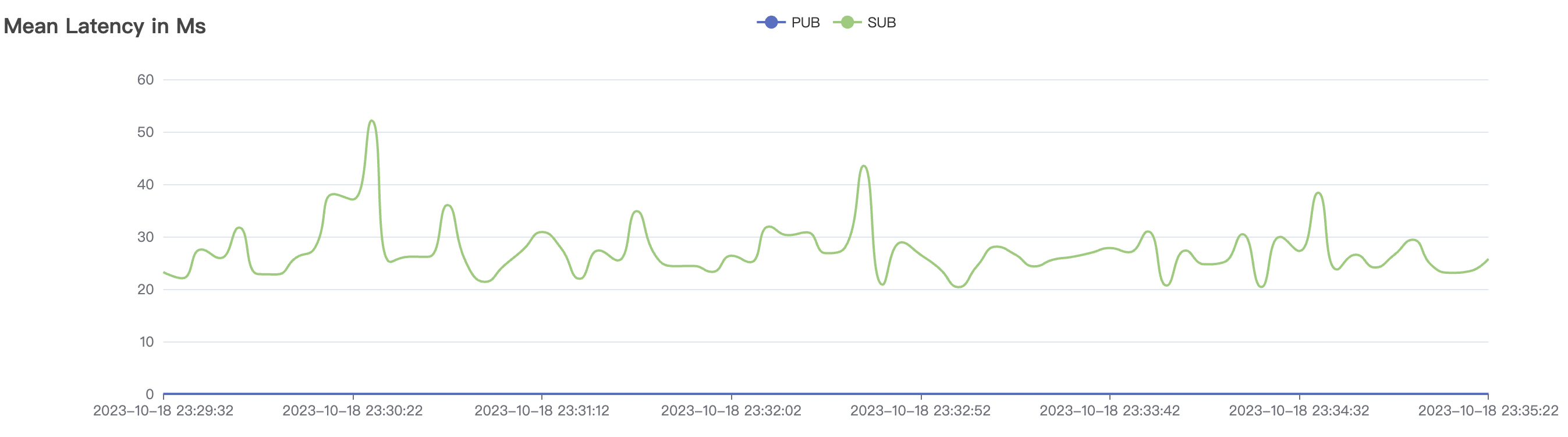 |
|---|---|
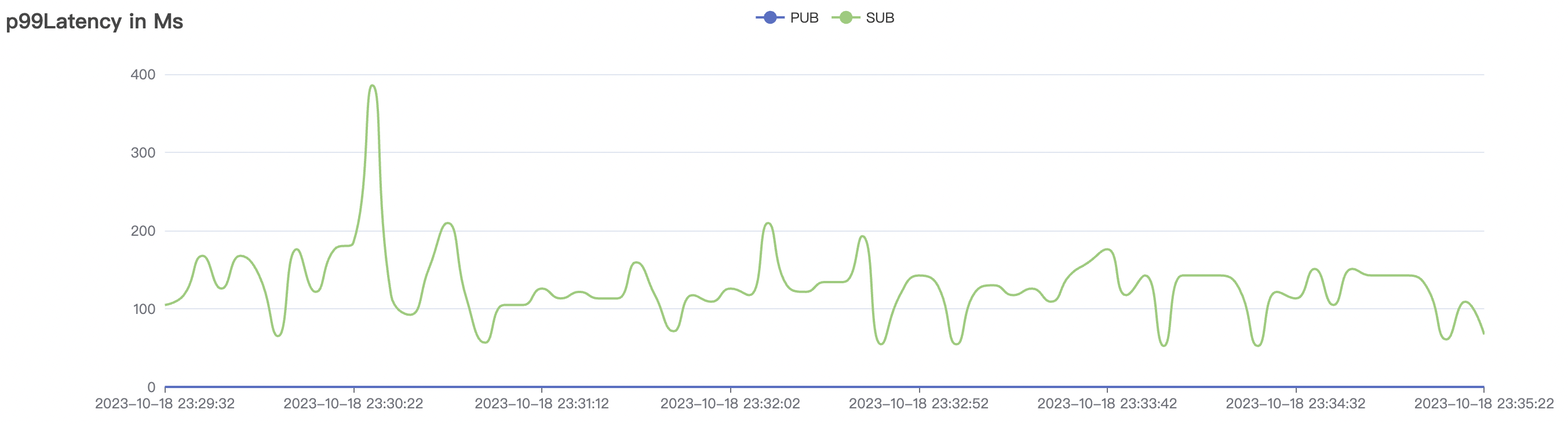 | 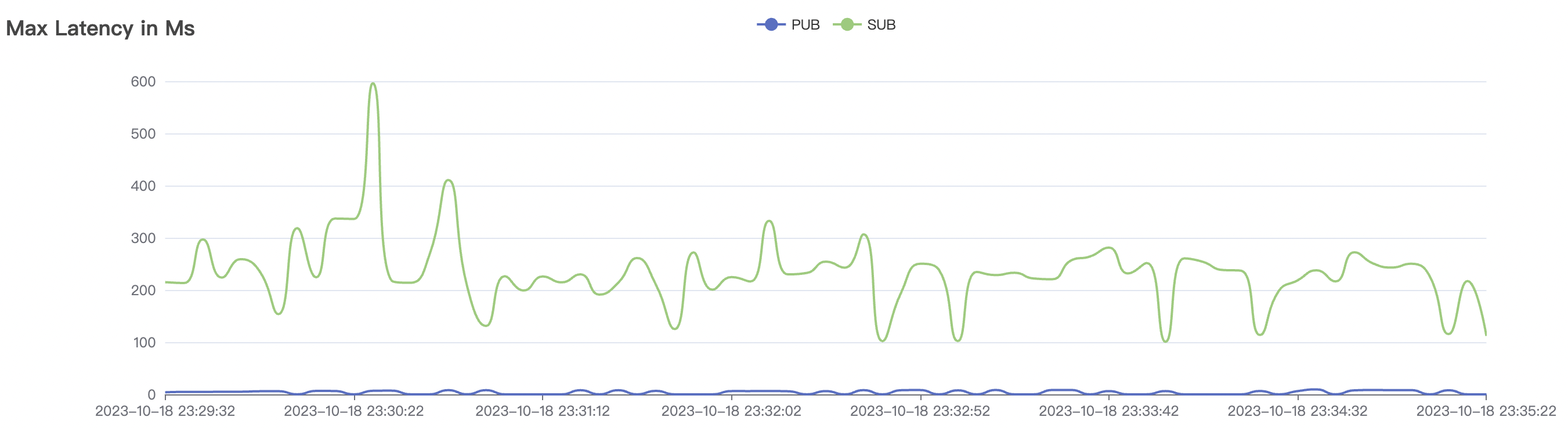 |
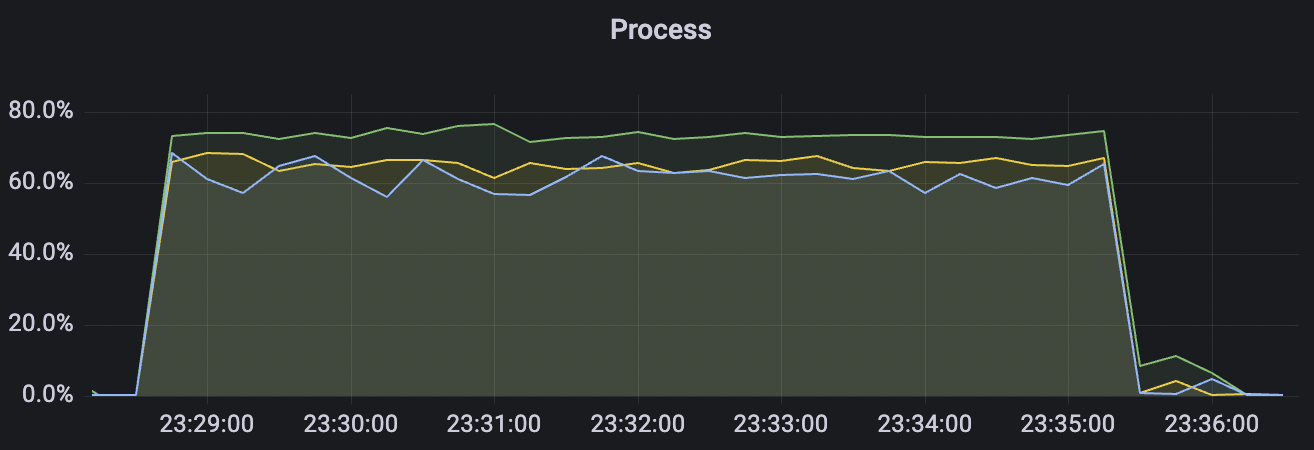 | 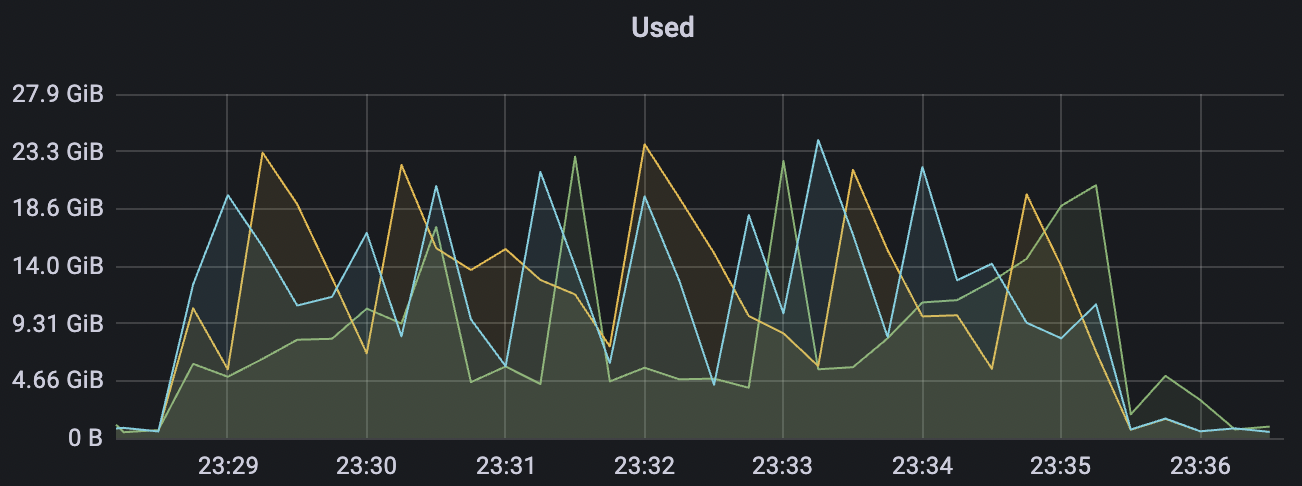 |
15k_15k_qos1_p256_1mps_3n_3v场景附图:
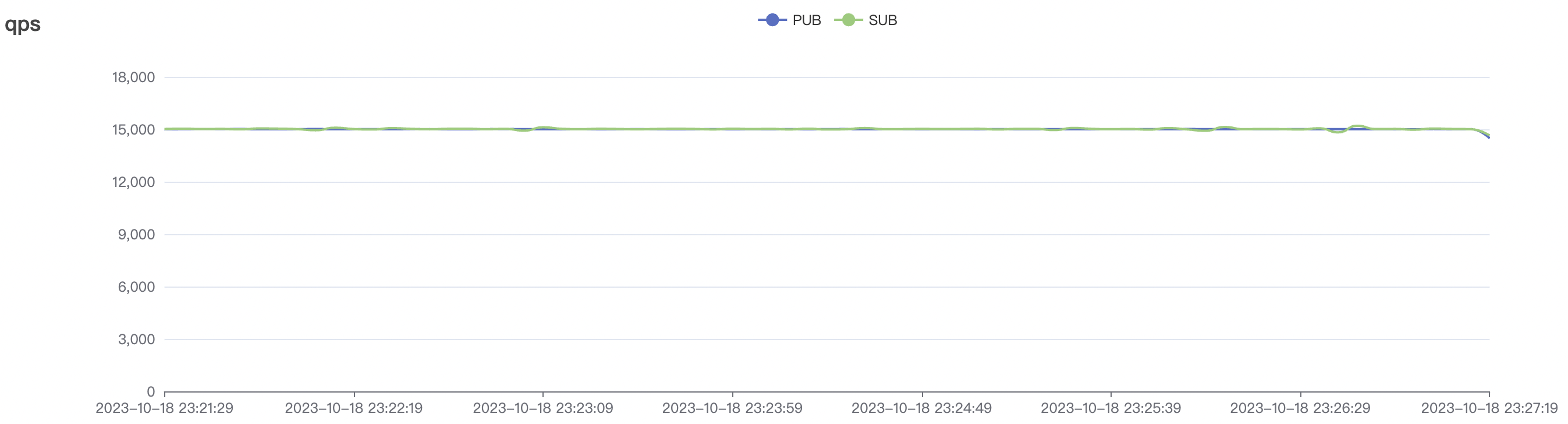 | 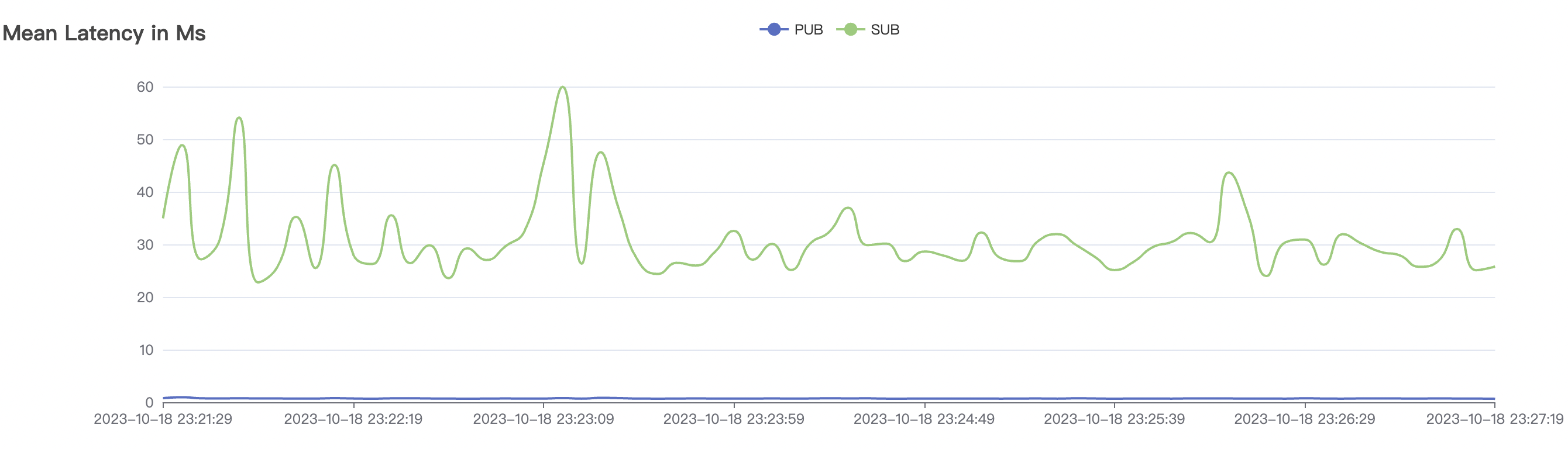 |
|---|---|
 |  |
 |  |
1对1 高频场景
| 场景组合 | QoS | 单连接m/s | Payload (byte) | 连接数C | 总消息m/s | 平均响应时间ms | P99响应时间ms | CPU | 内存占用GB |
|---|---|---|---|---|---|---|---|---|---|
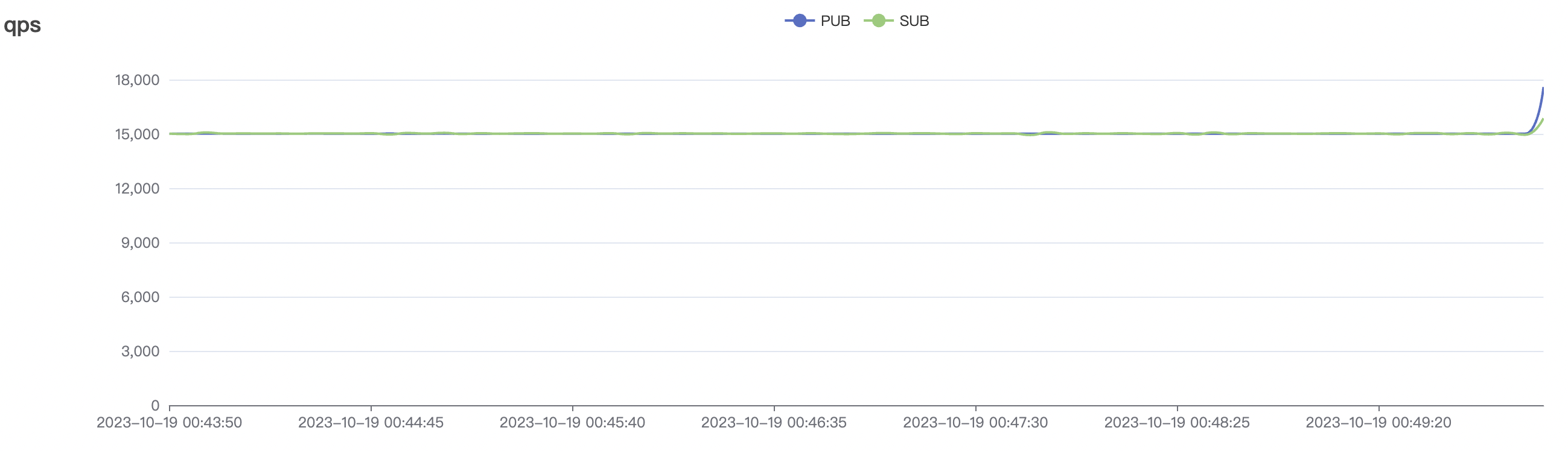
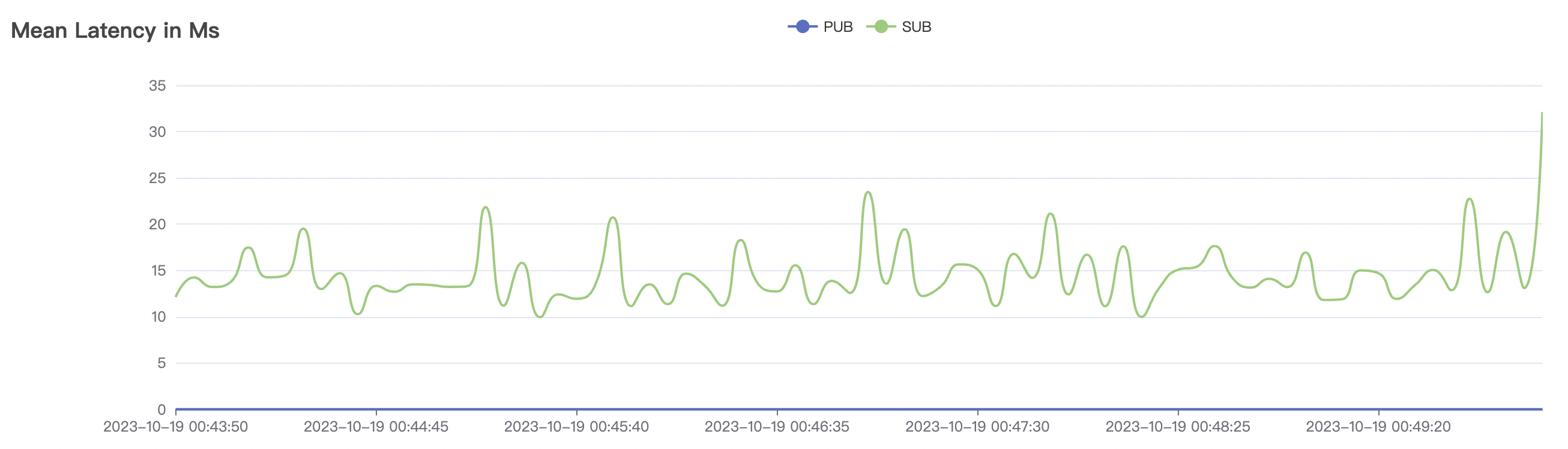
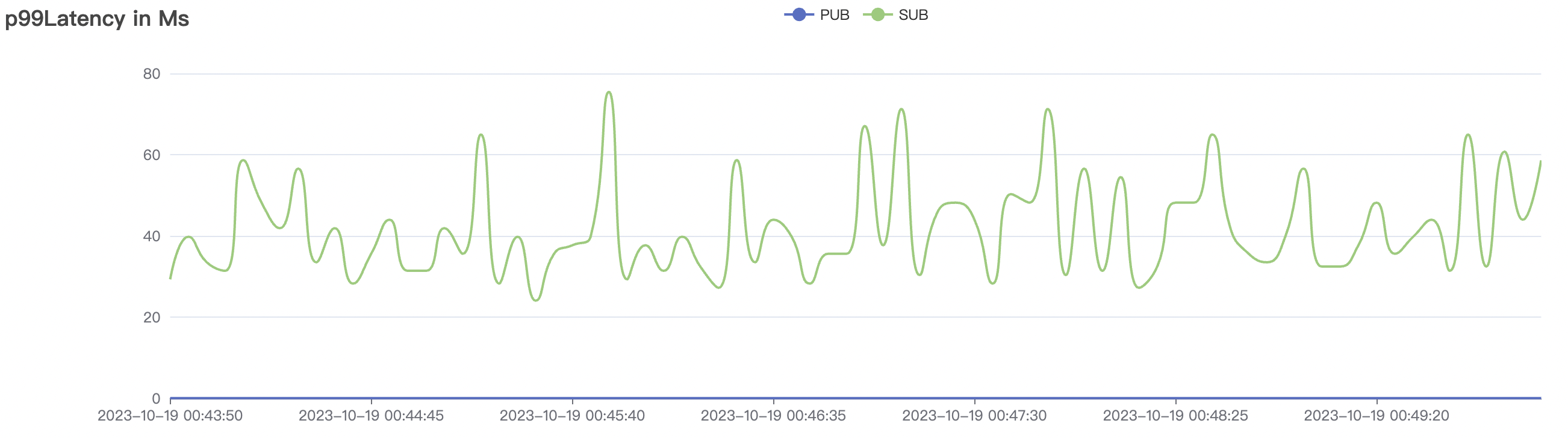
| 300_300_qos0_p32_50mps_1n_1v | 0 | 50 | 32 | 0.6k | 15k | 14.38 | 50.27 | 70% | 3~15 |
| 300_300_qos1_p32_50mps_1n_1v | 1 | 50 | 32 | 0.6k | 15k | 16.5 | 52.4 | 75% | 5~15 |
| 900_900_qos0_p32_50mps_3n_1v | 0 | 50 | 32 | 1.8k | 45k | 82.36 | 243.2 | 55% | 5~18 |
| 900_900_qos1_p32_50mps_3n_1v | 1 | 50 | 32 | 1.8k | 45k | 95.74 | 369.03 | 65% | 5~20 |
| 300_300_qos0_p32_50mps_3n_3v | 0 | 50 | 32 | 0.6k | 15k | 22.91 | 75.43 | 70% | 5~15 |
| 300_300_qos1_p32_50mps_3n_3v | 1 | 50 | 32 | 0.6k | 15k | 26.96 | 88.01 | 70% | 5~15 |
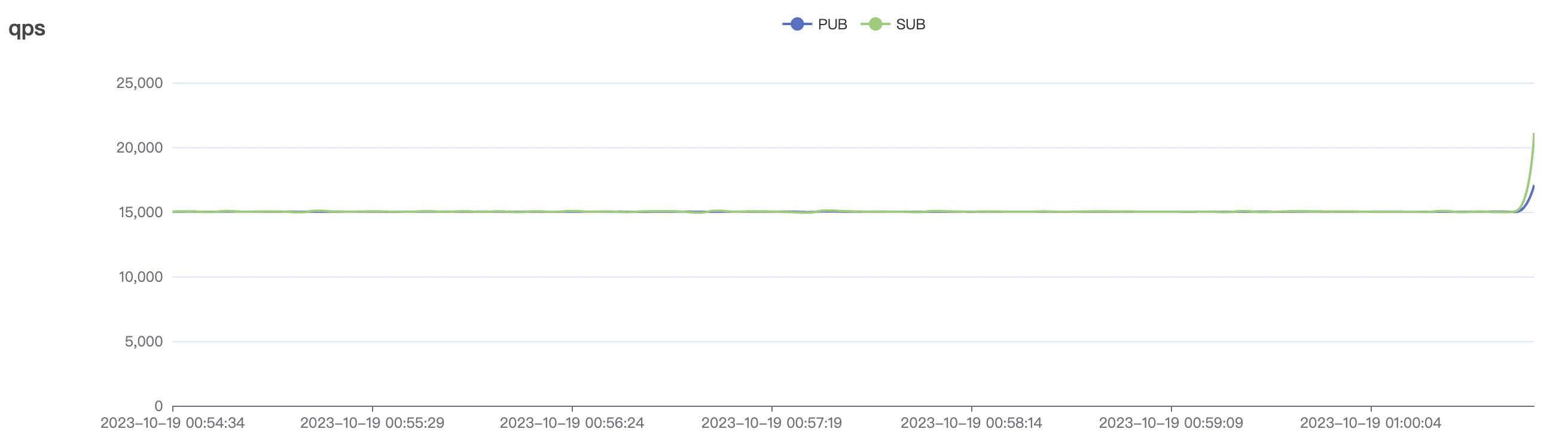
300_300_qos0_p32_50mps_1n_1v场景附图:
 |  |
|---|---|
 | 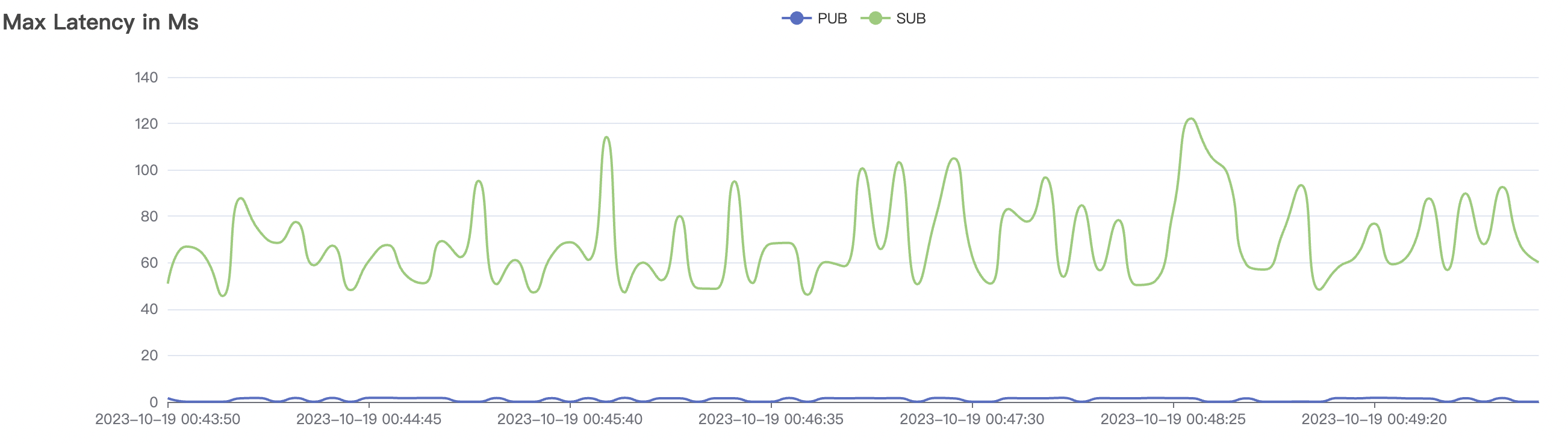 |
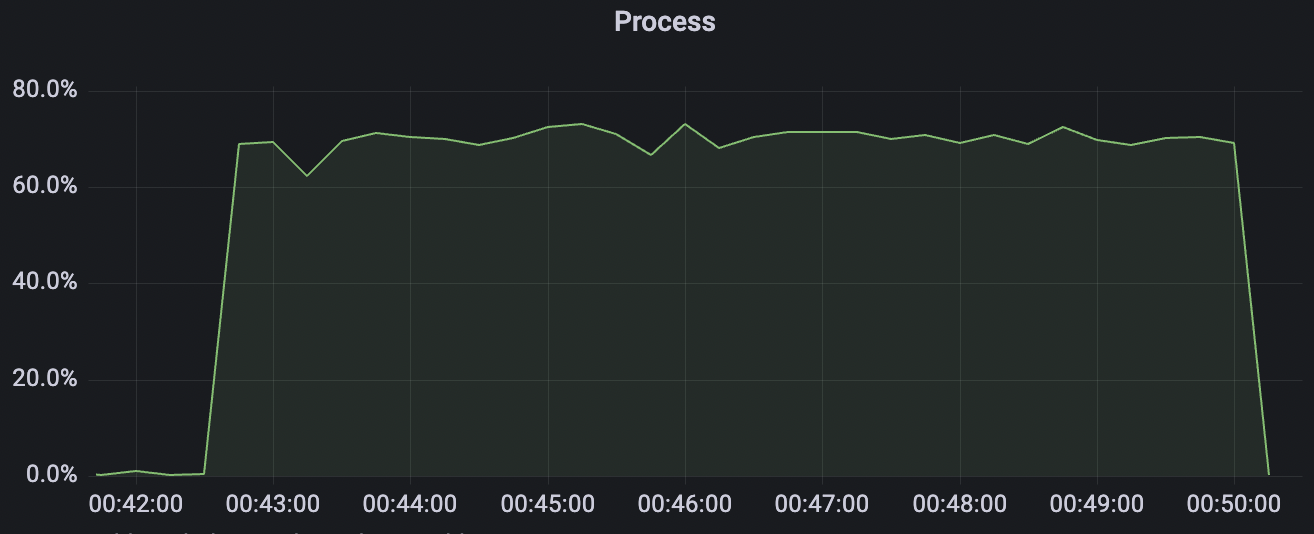 | 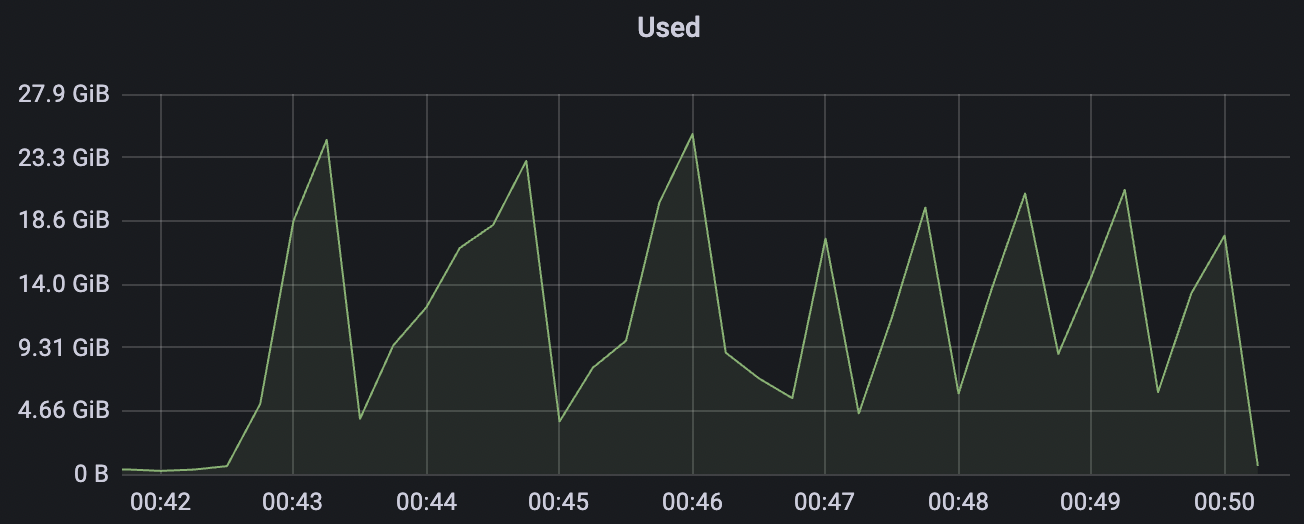 |
300_300_qos1_p32_50mps_1n_1v场景附图:
 | 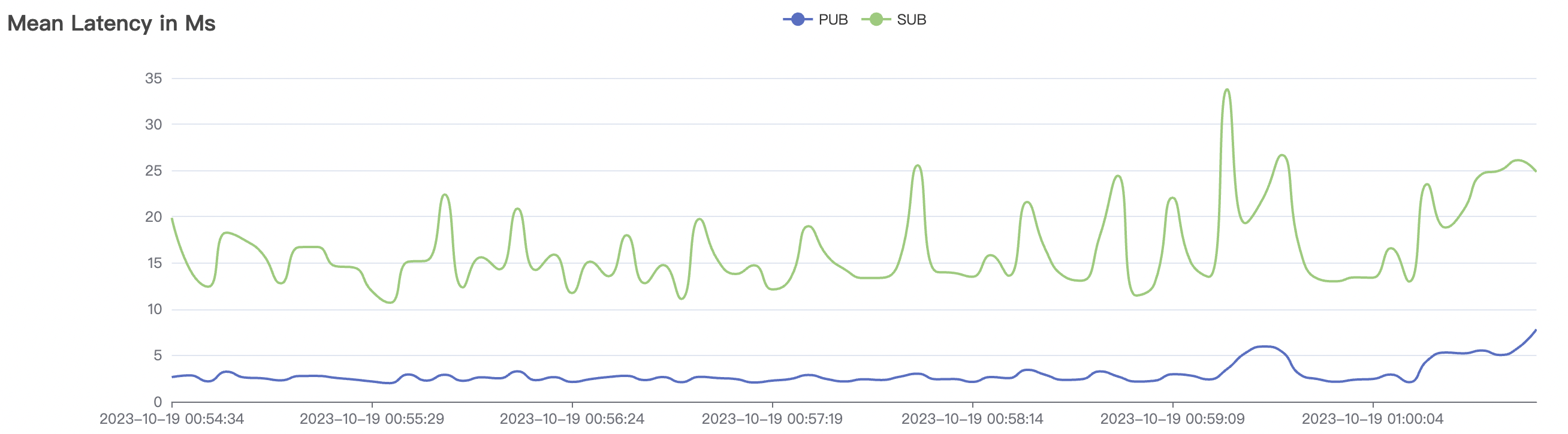 |
|---|---|
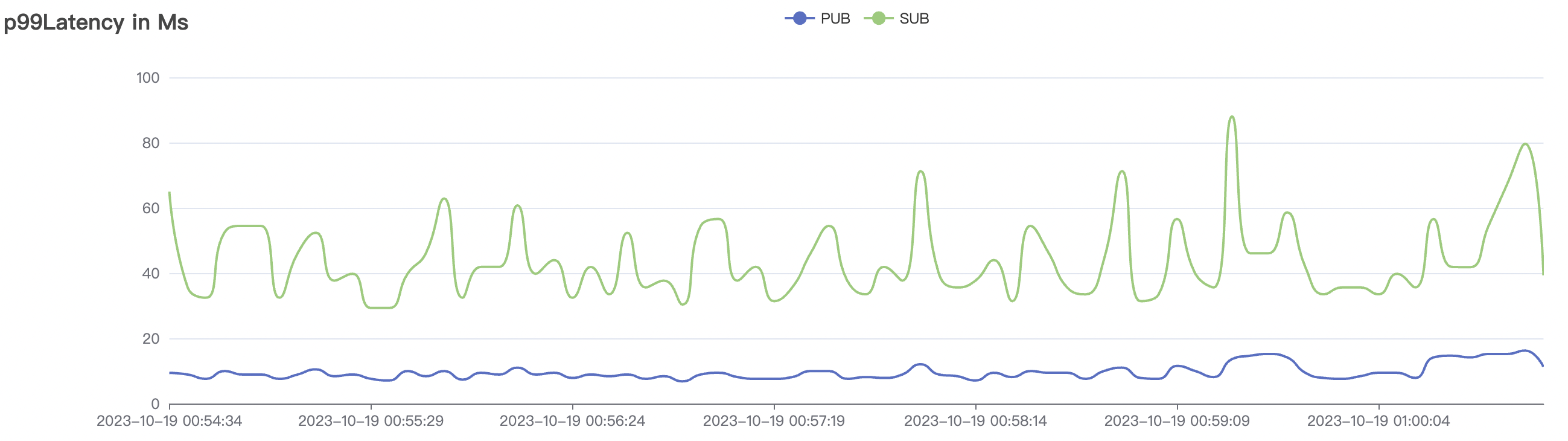 | 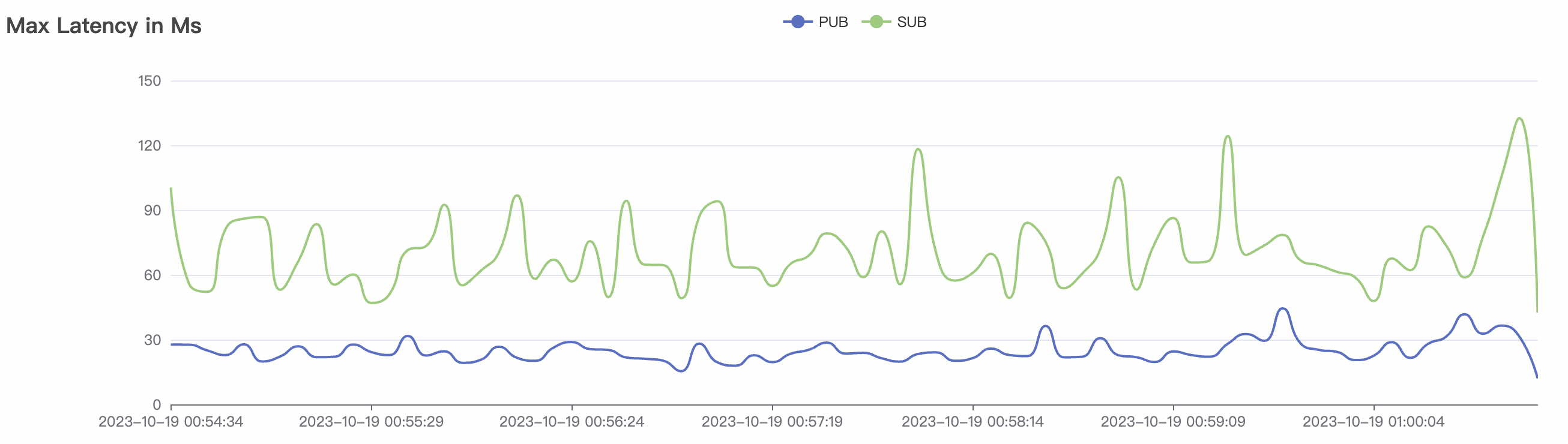 |
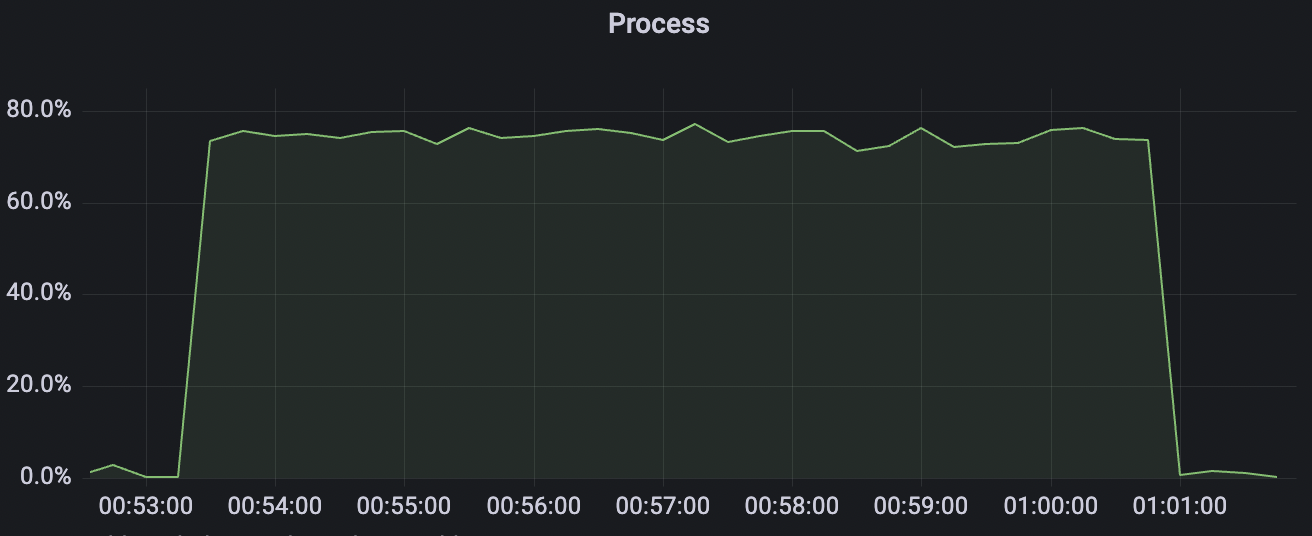 | 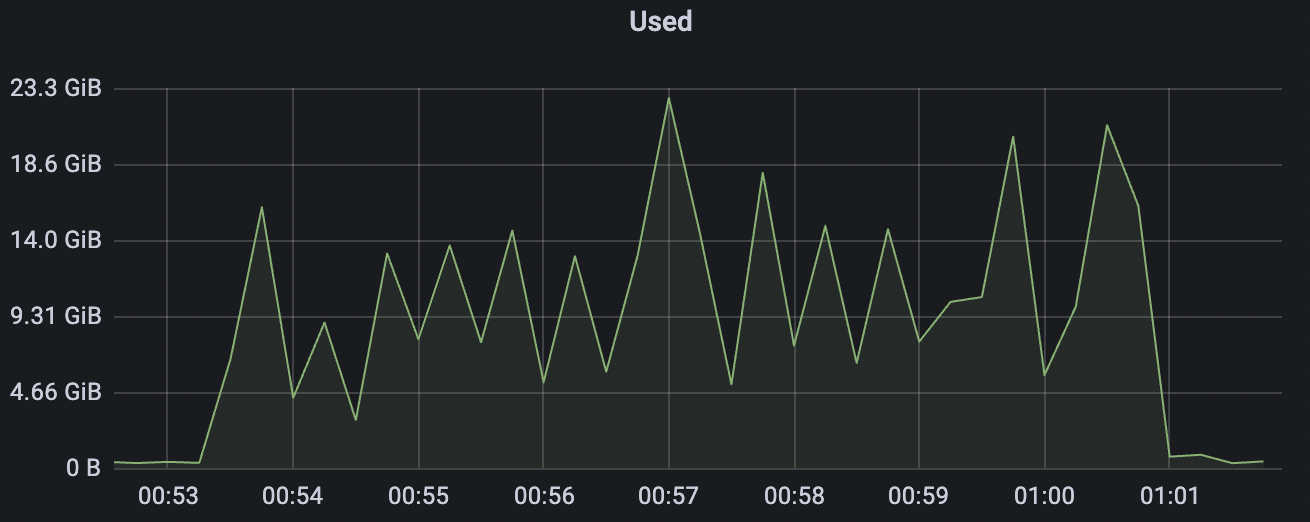 |
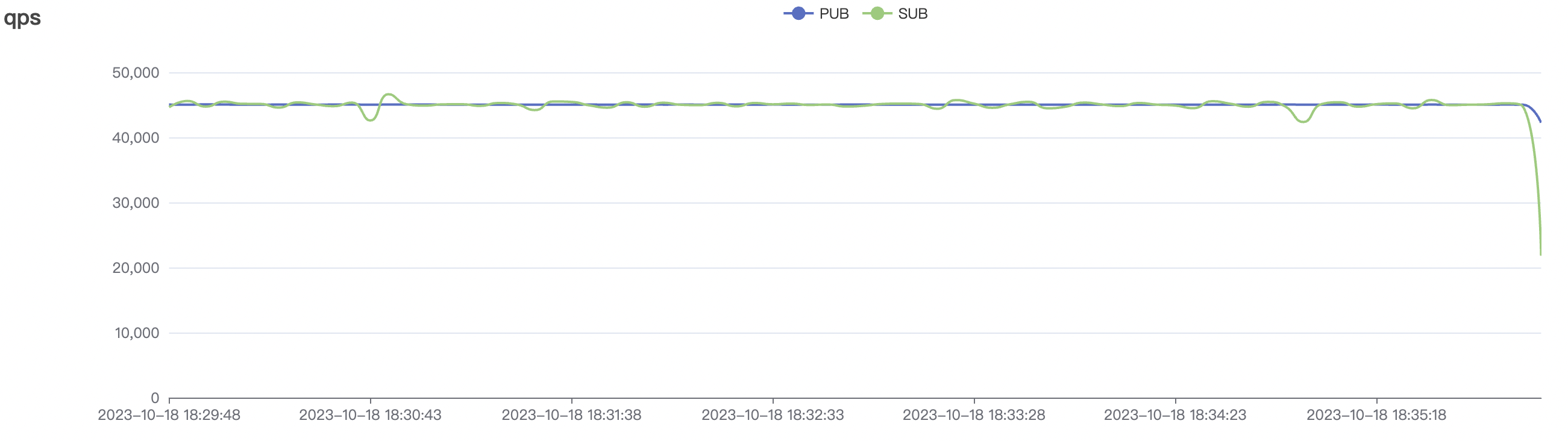
900_900_qos0_p32_50mps_3n_1v场景附图:
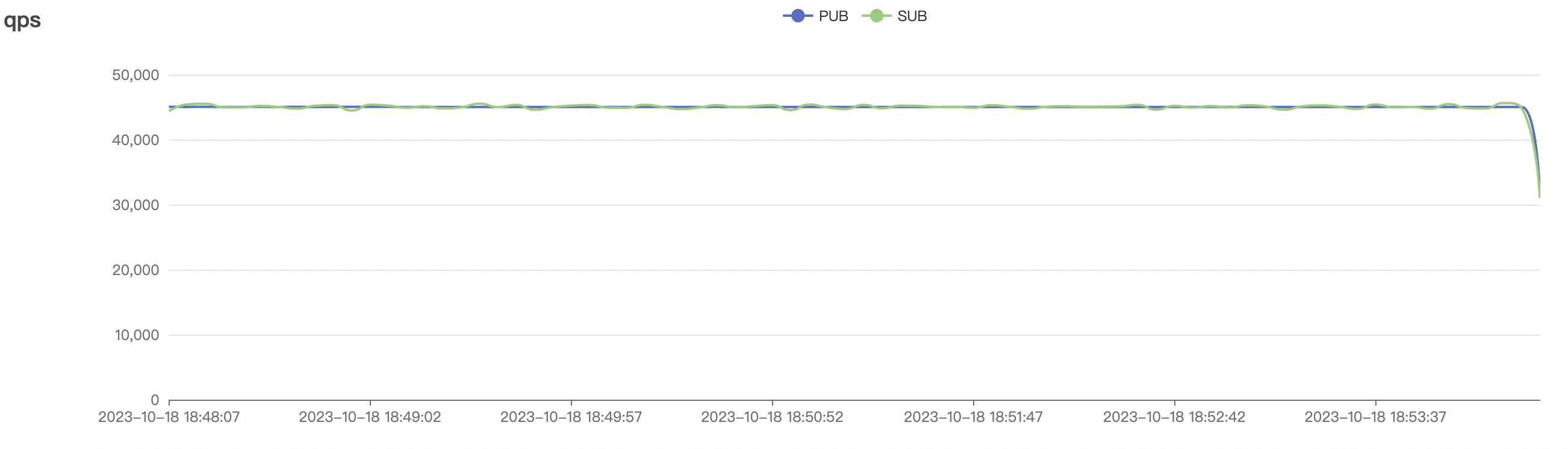 | 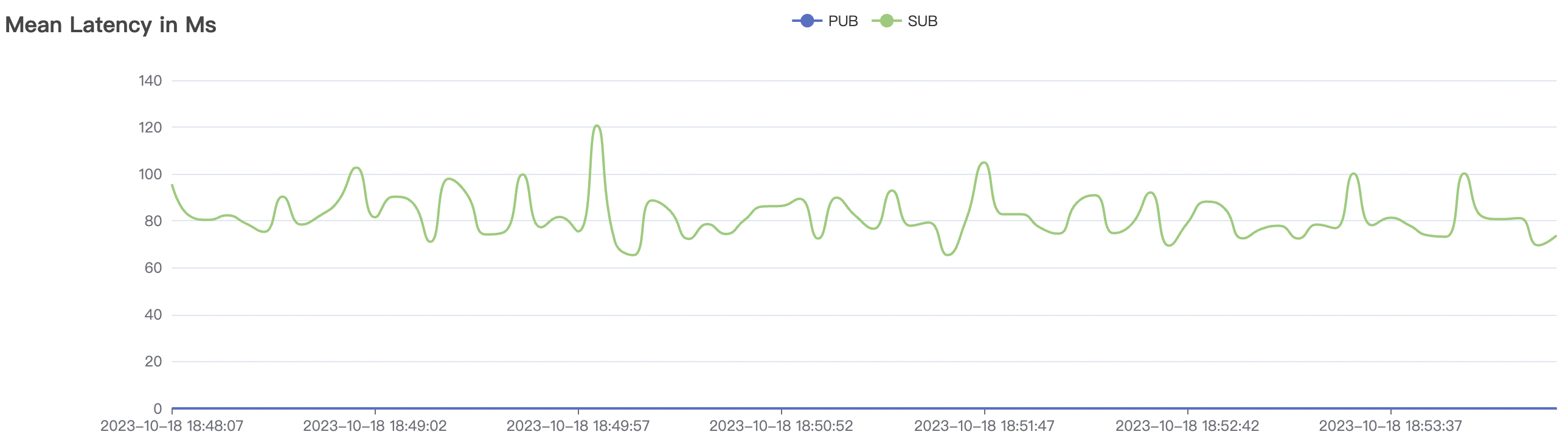 |
|---|---|
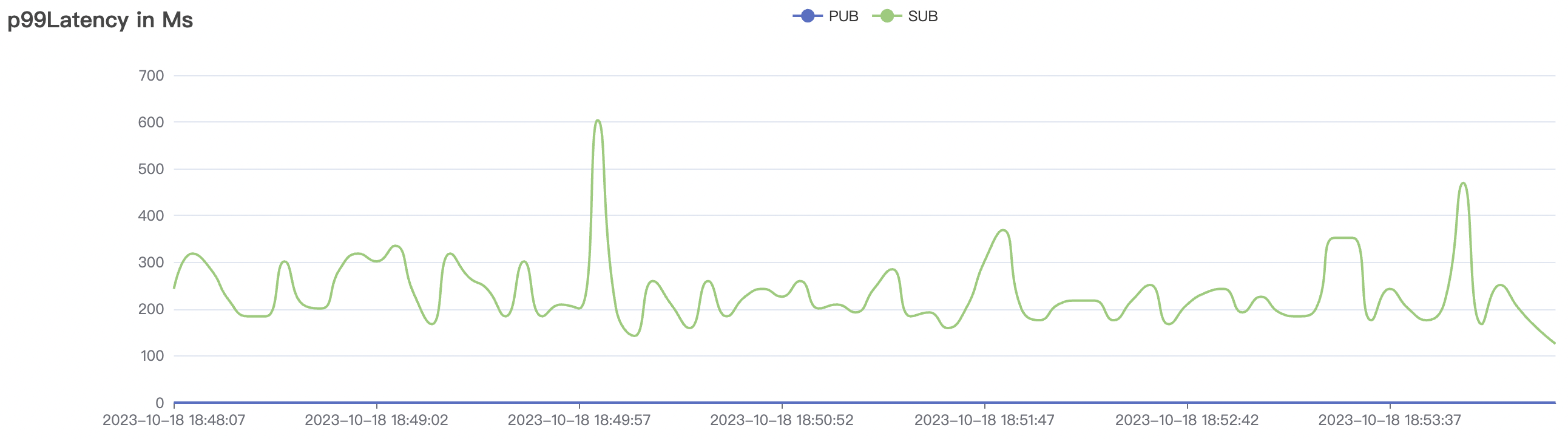 |  |
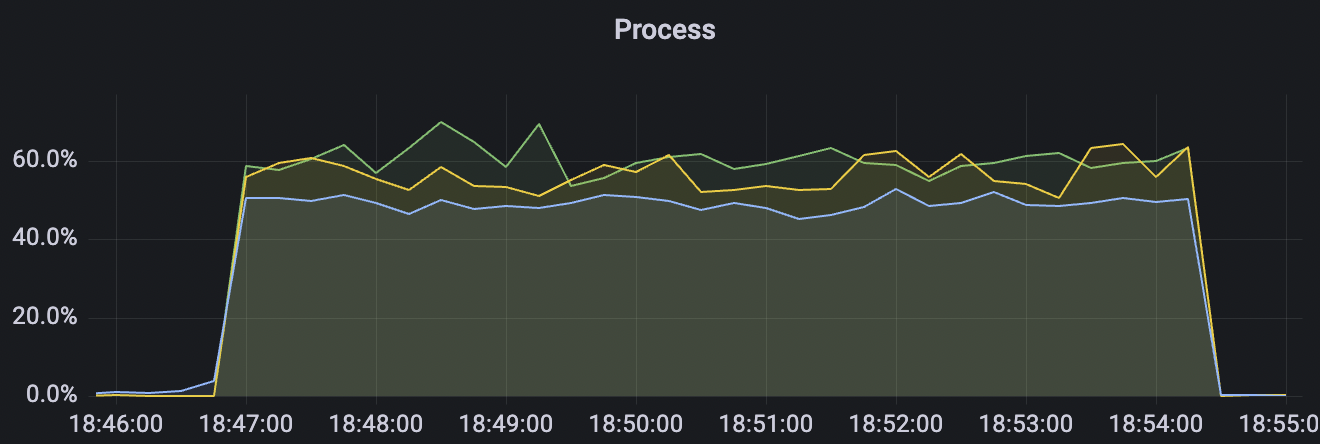 | 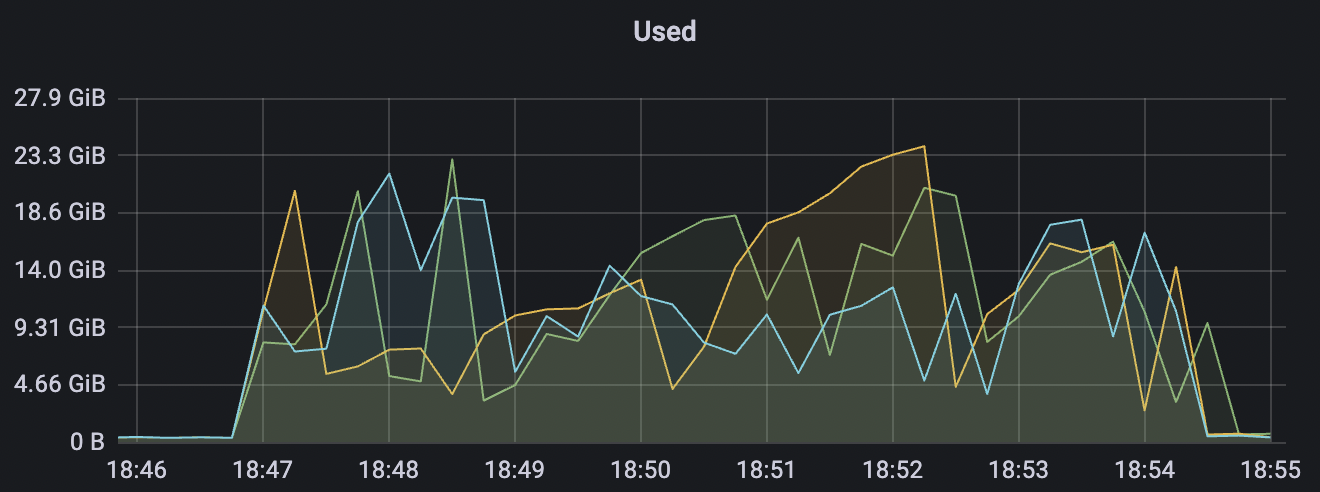 |
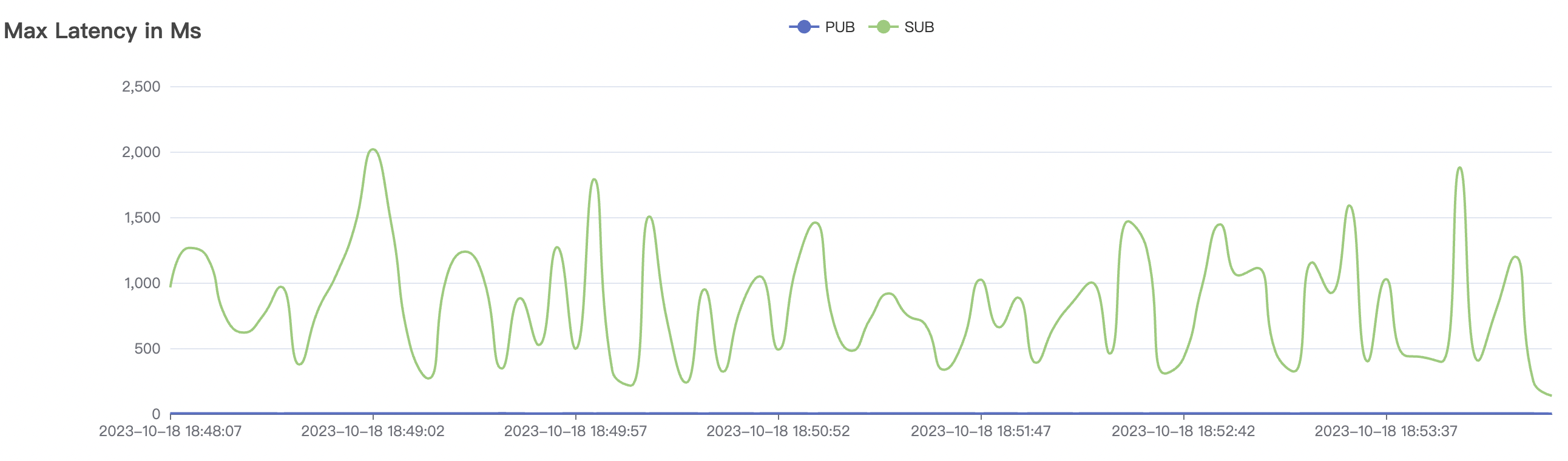
900_900_qos1_p32_50mps_3n_1v场景附图:
 | 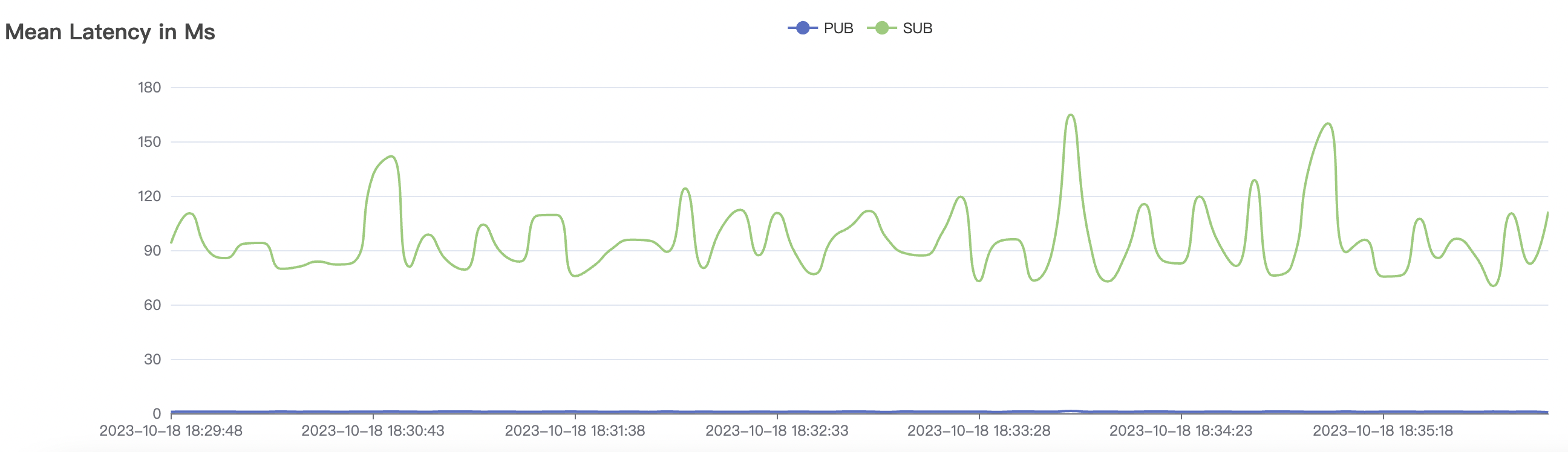 |
|---|---|
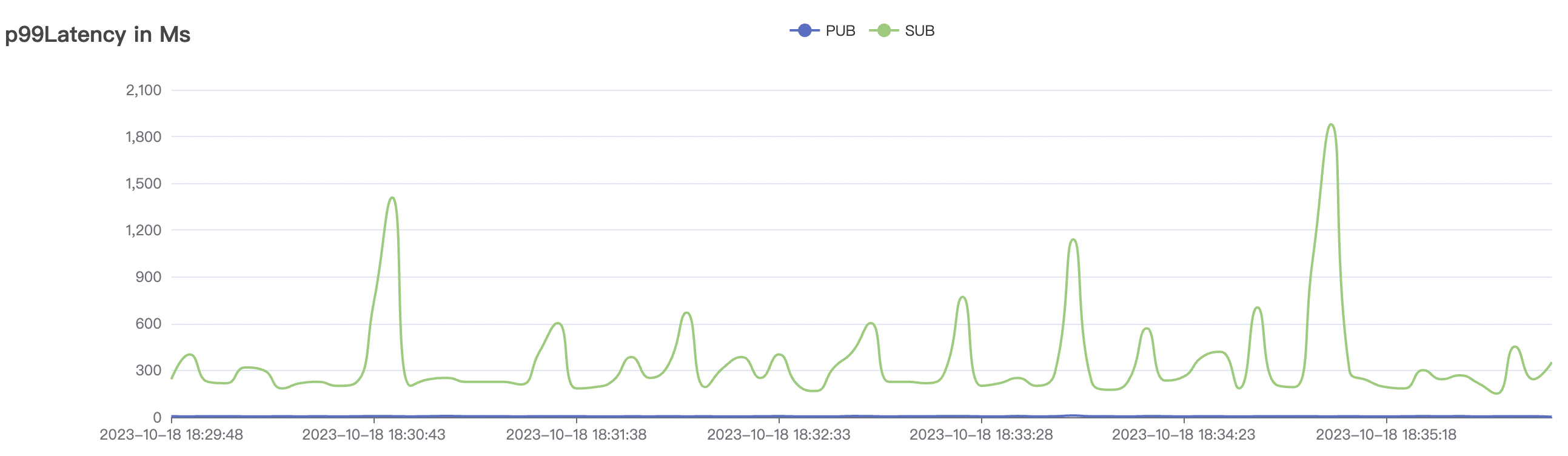 | 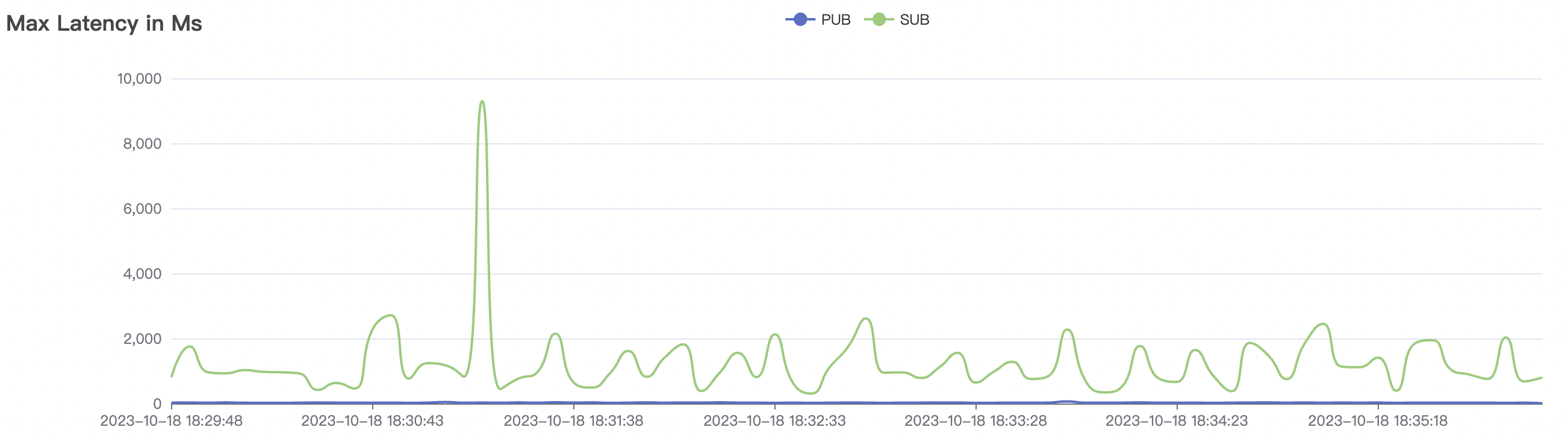 |
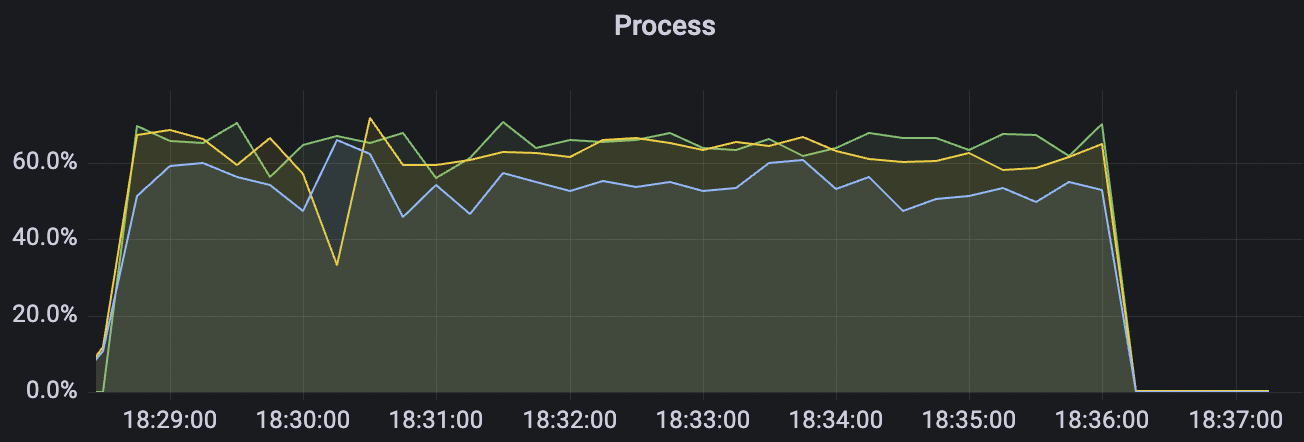 | 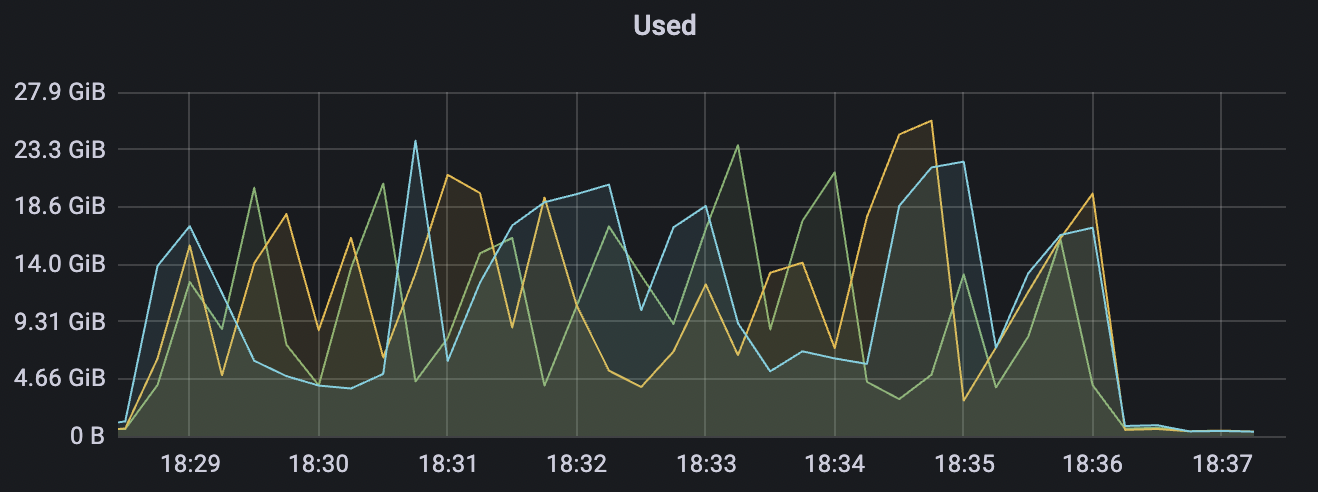 |
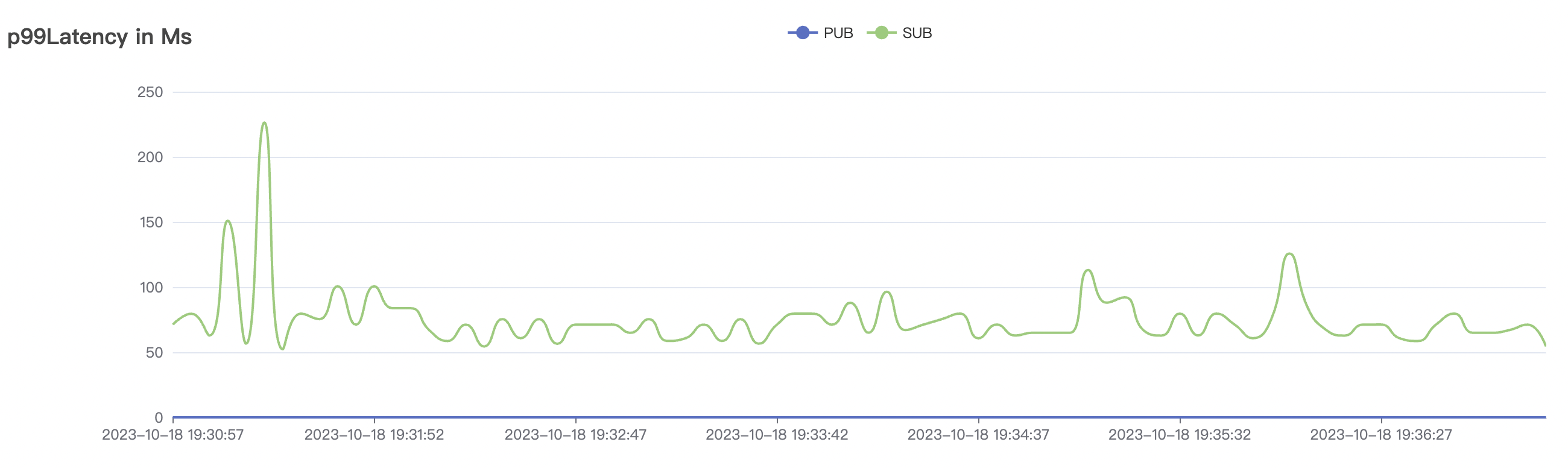
300_300_qos0_p32_50mps_3n_3v场景附图:
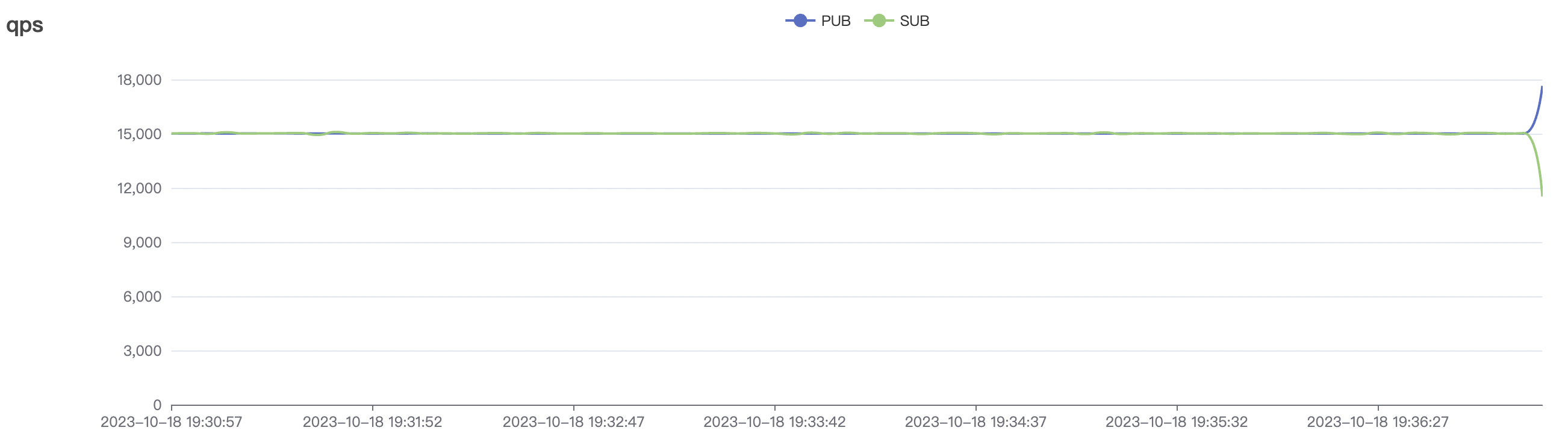 | 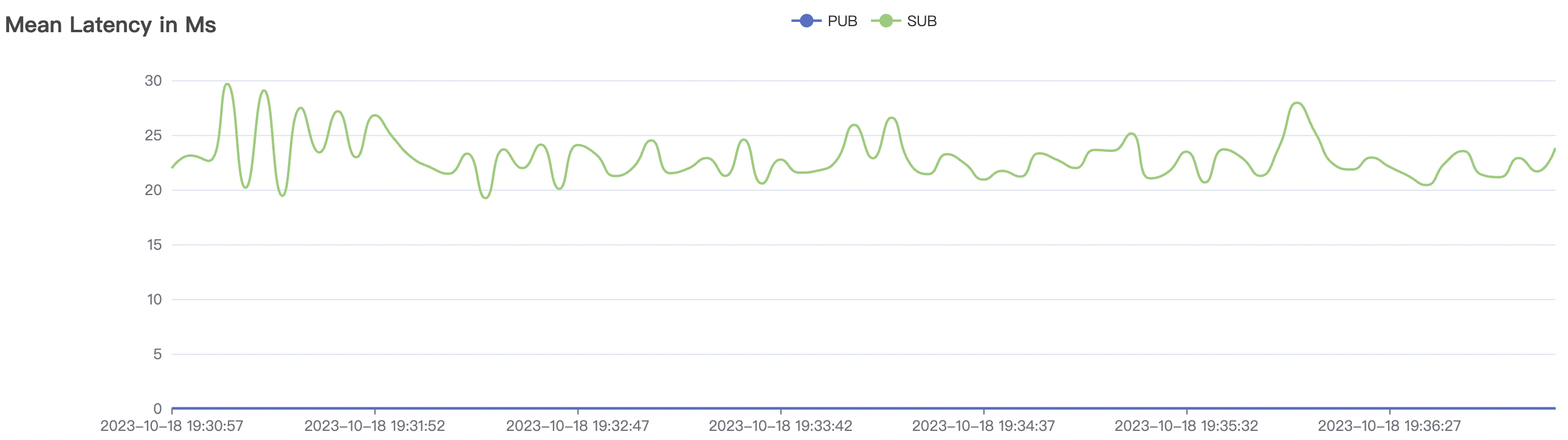 |
|---|---|
 |  |
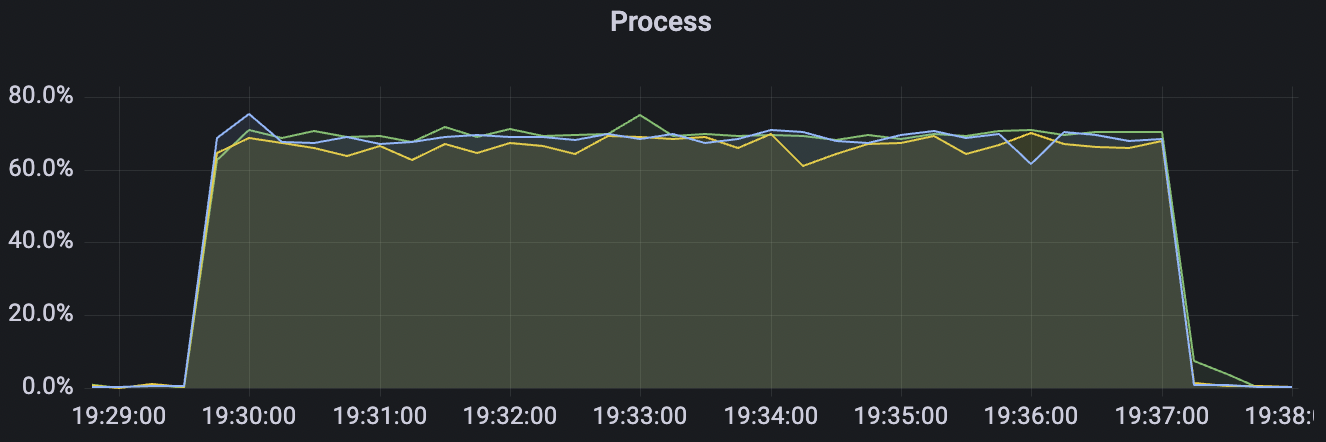 | 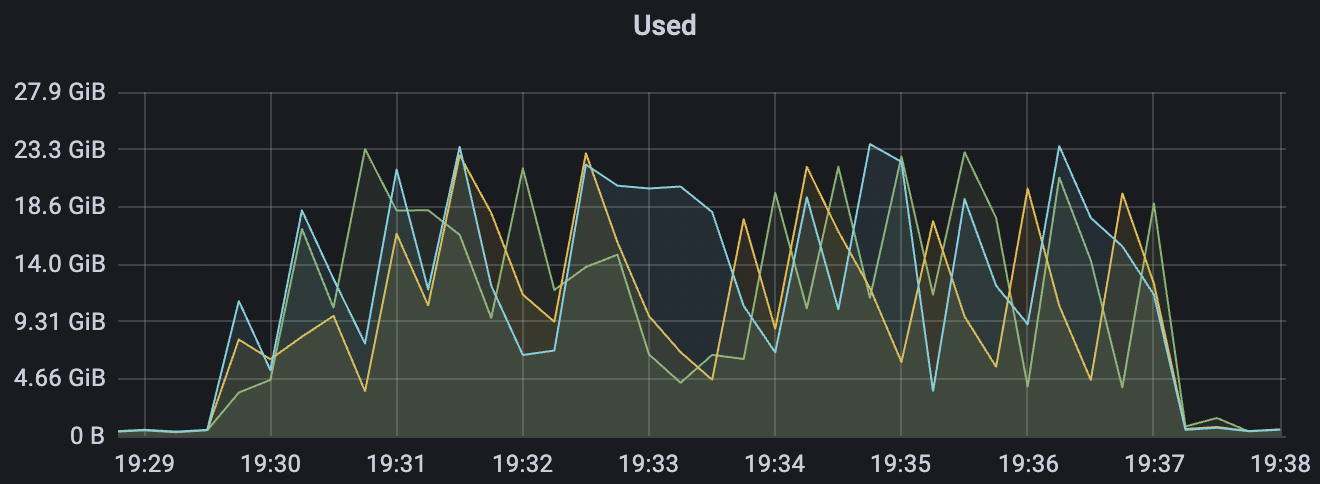 |
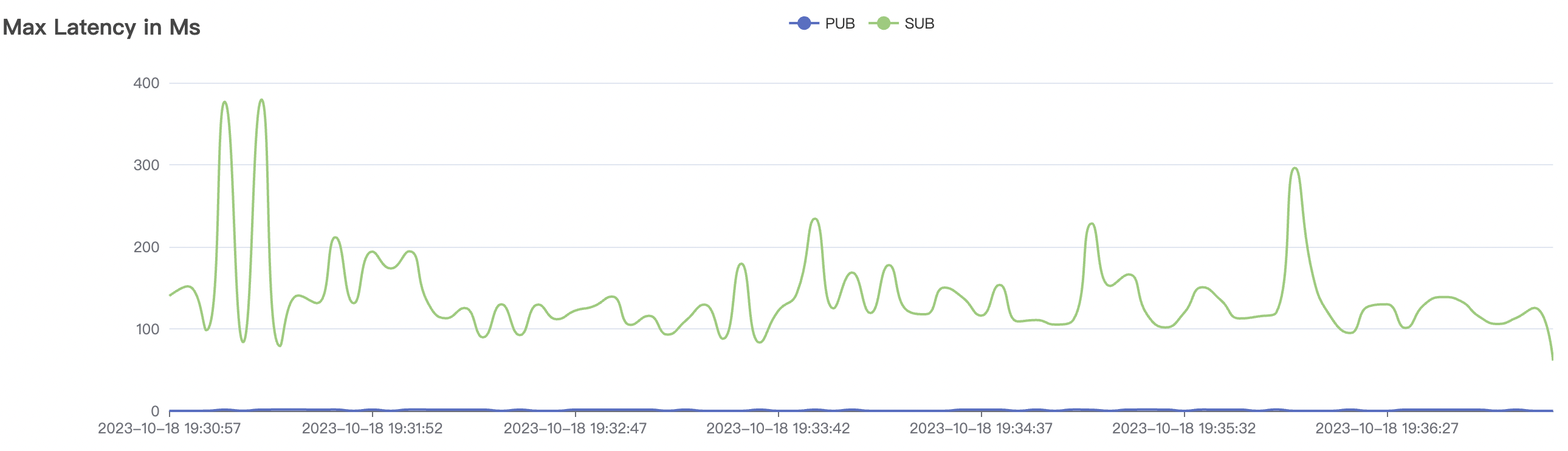
300_300_qos1_p32_50mps_3n_3v场景附图:
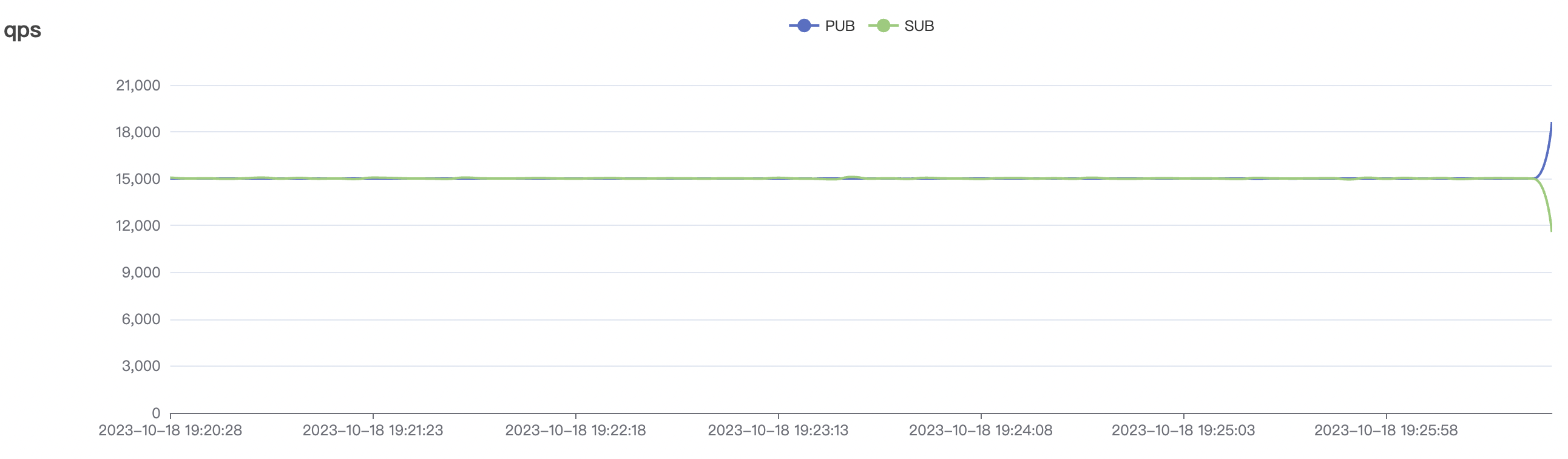 | 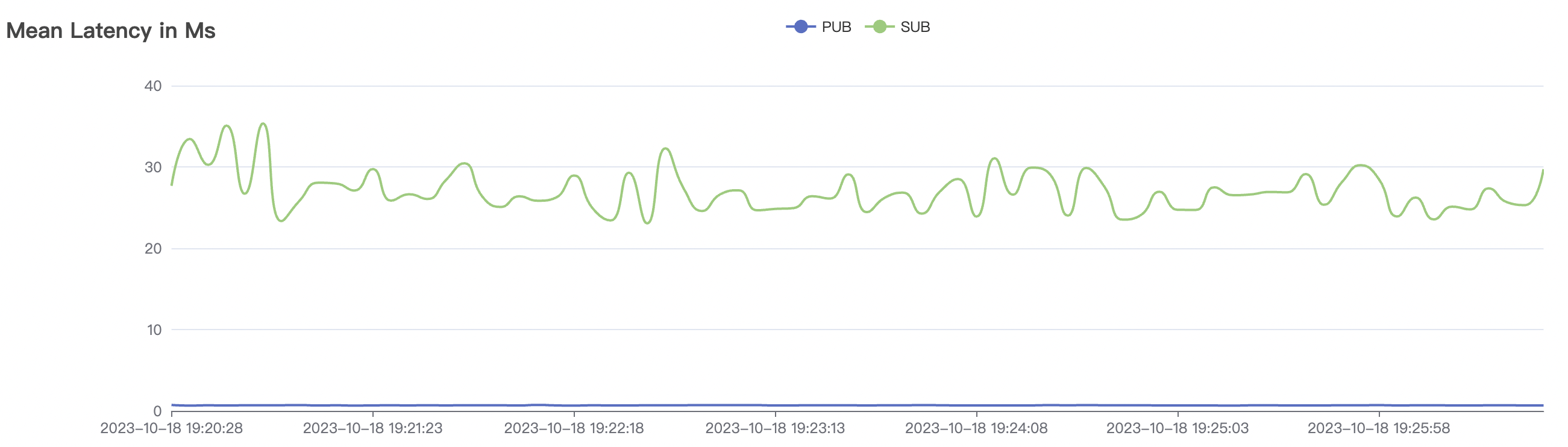 |
|---|---|
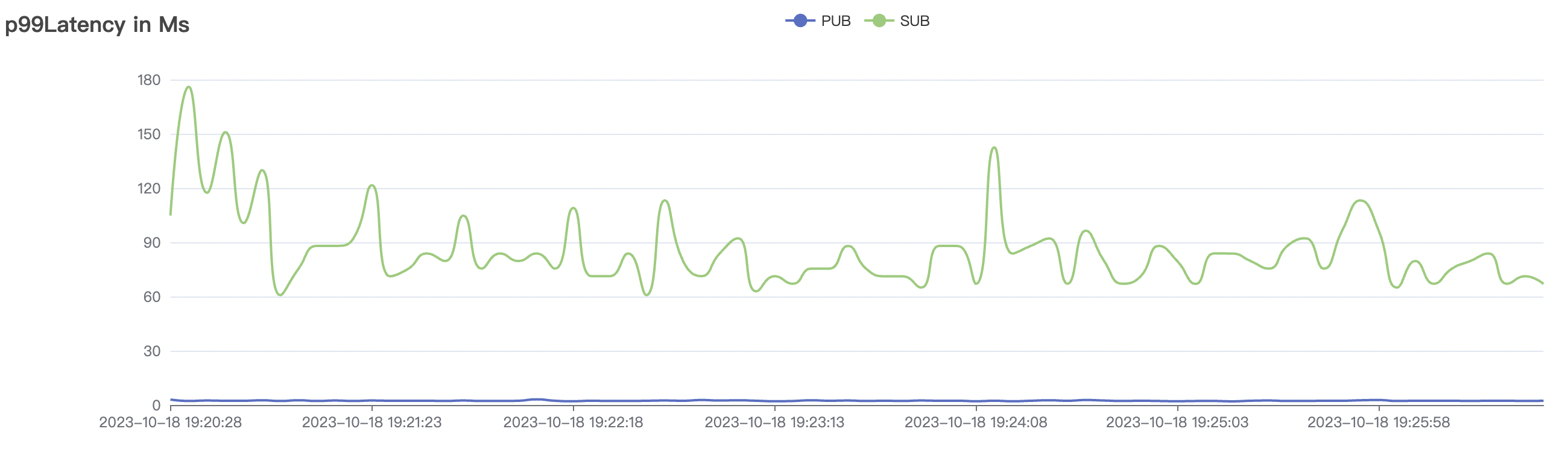 | 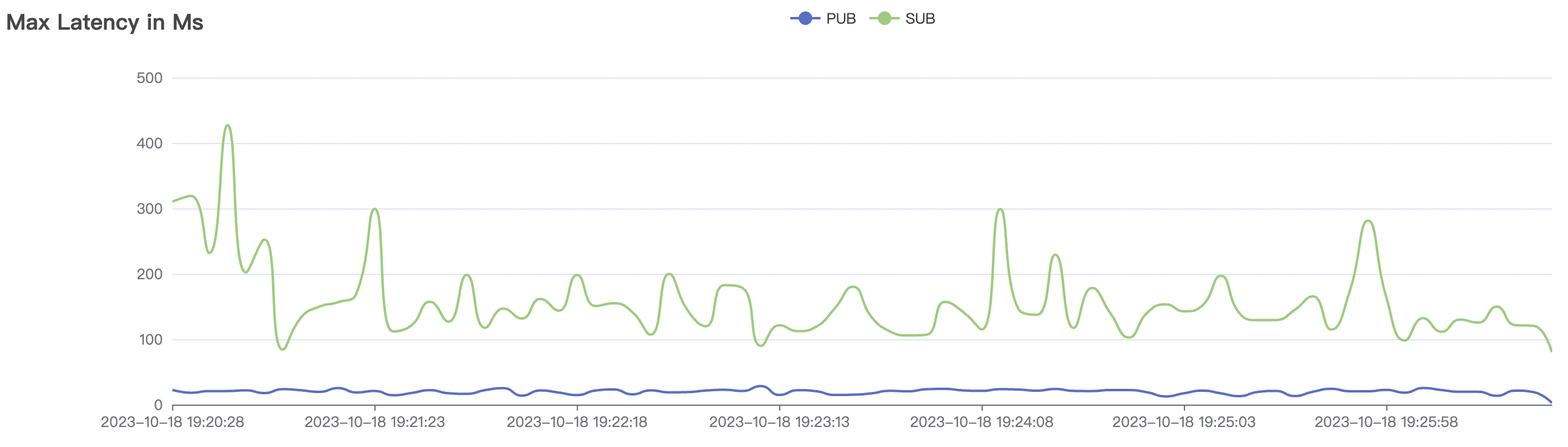 |
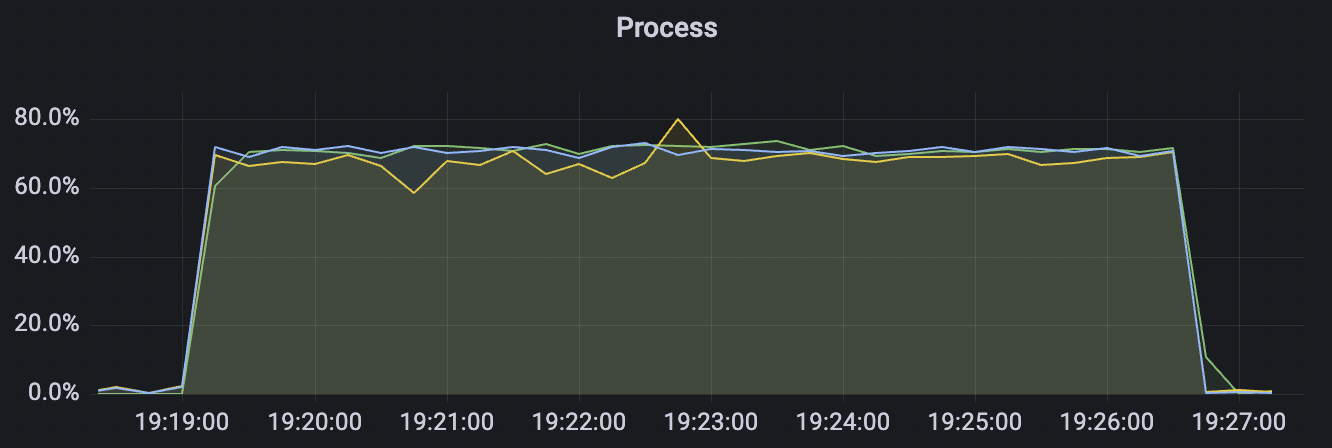 | 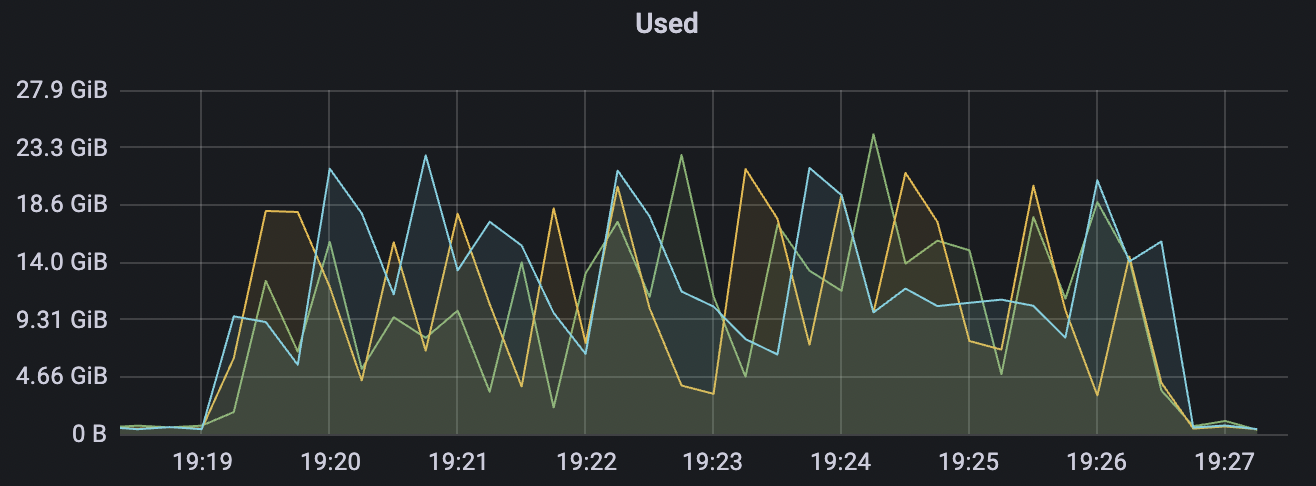 |
冷启动场景
冷启动即集群启动后,直接开始以大压力开始cleansession=false的测试,此时集群内部存储引擎会先随着压力进行分片,达到合适的数目后,开始稳定工作。
| 场景组合 | QoS | 单连接m/s | Payload (byte) | 连接数C | 总消息m/s |
|---|---|---|---|---|---|
| 30k_30k_qos1_p256_1mps_3n_1v | 1 | 1 | 256 | 60k | 30k |
冷启动场景附图:
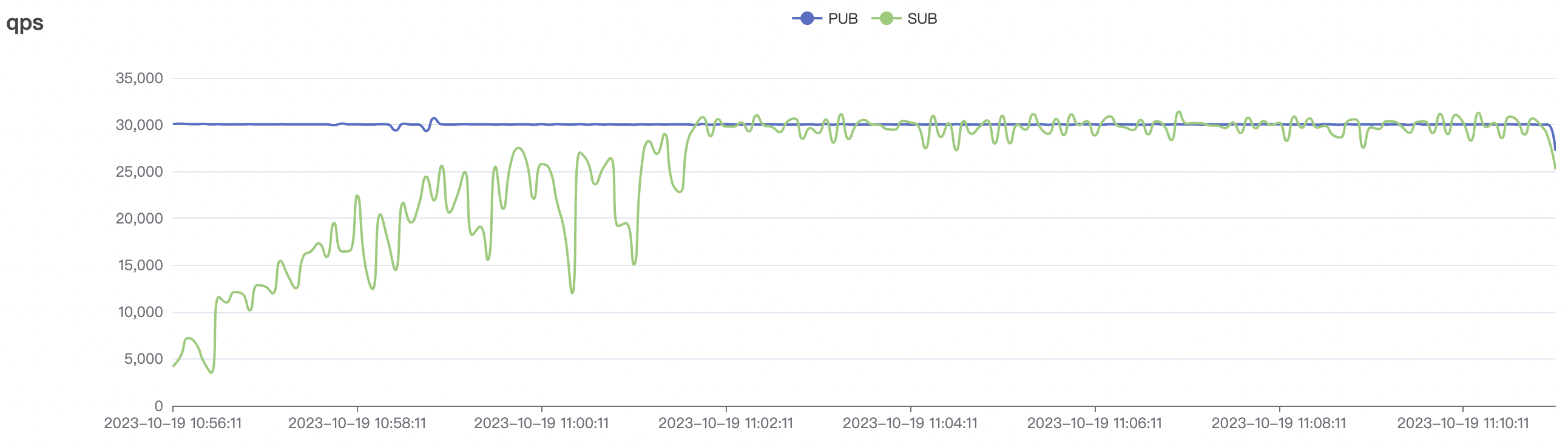 | 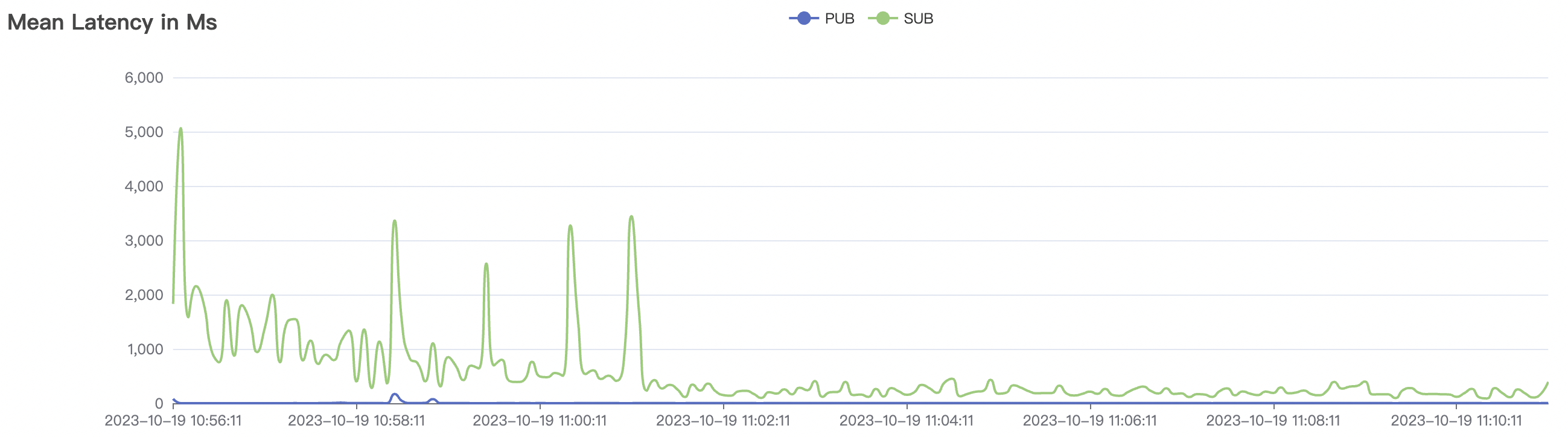 |
|---|---|
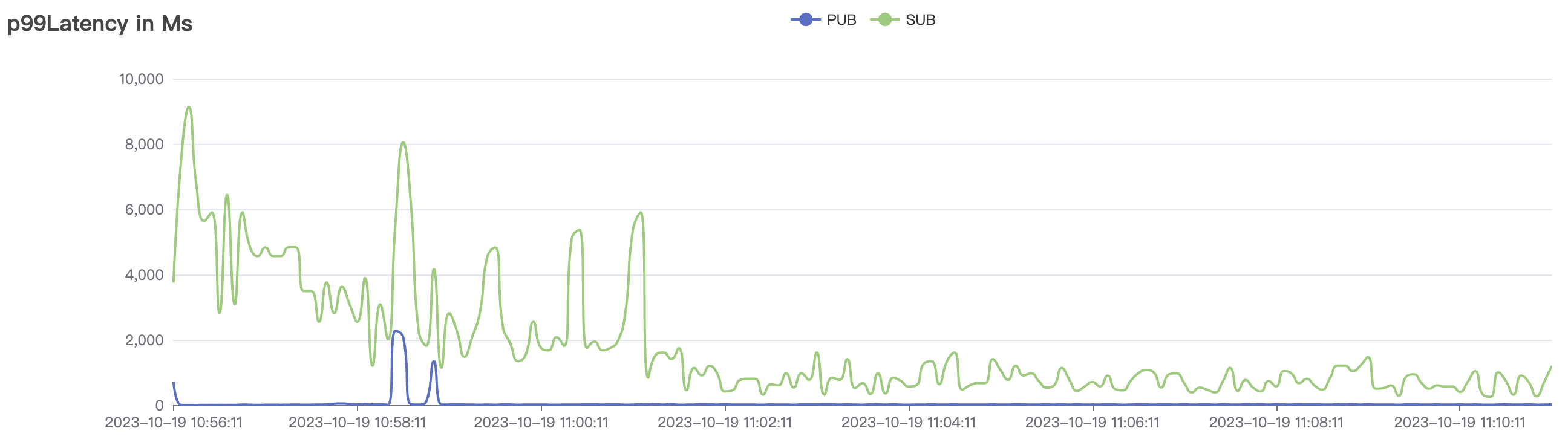 | 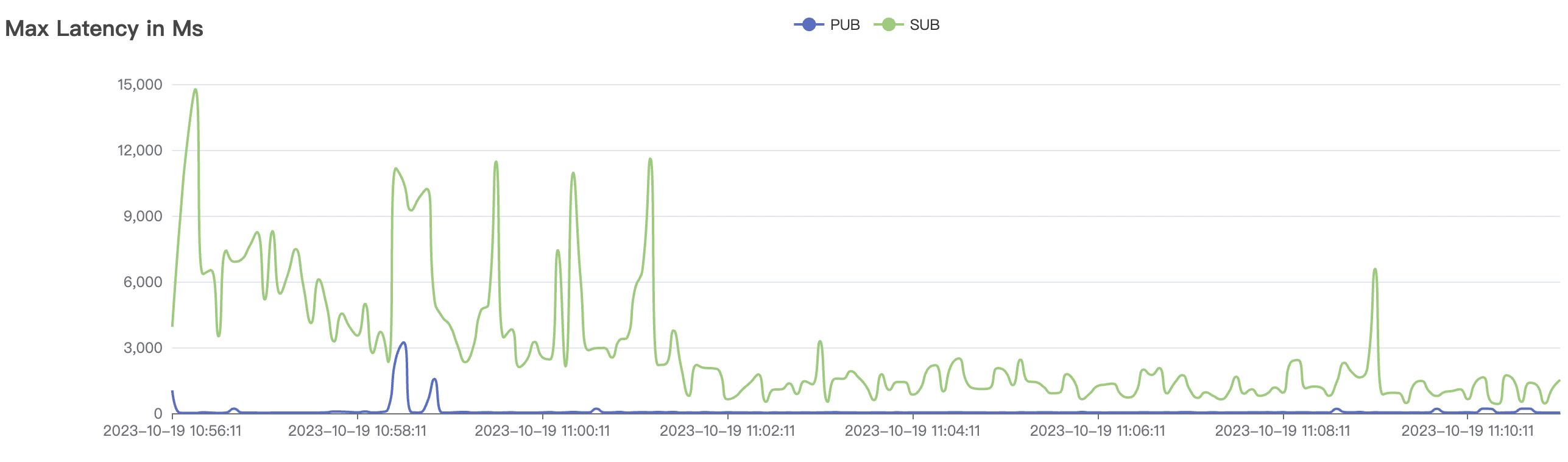 |
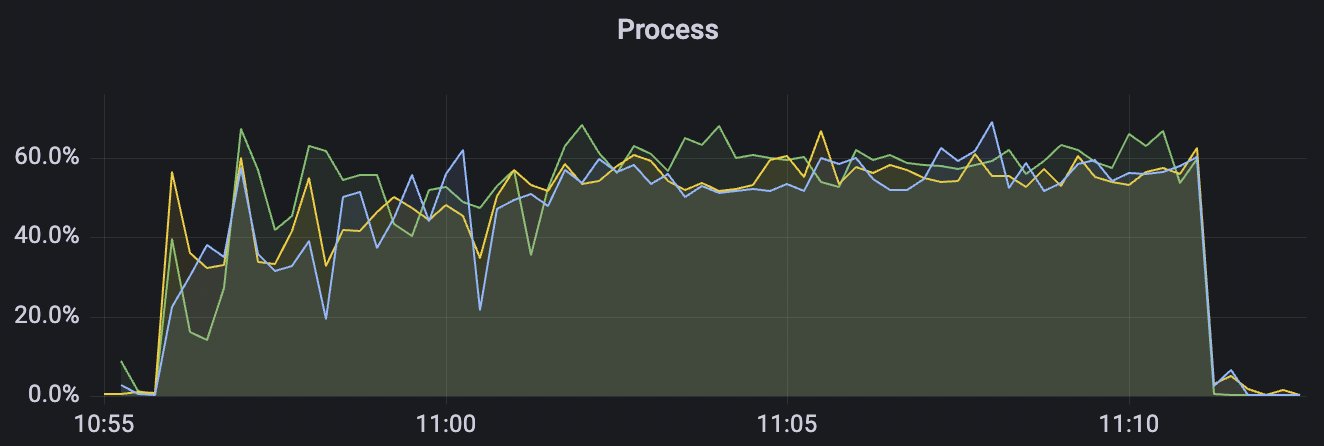 | 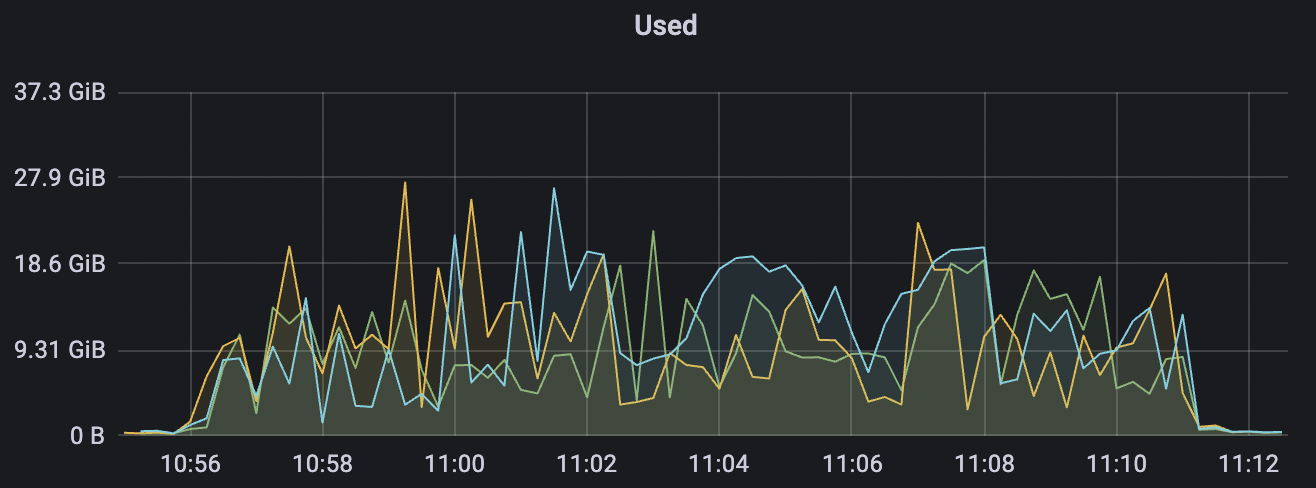 |
百万连接
此场景主要为了测试BifroMQ在承载大量连接时的资源消耗。
| 场景组合 | cleansession | 连接数 | 建立连接速率 | cpu | 内存占用GB |
|---|---|---|---|---|---|
| conn-tcp-1M-5K_1n_true | true | 1M | 5k | 30% | 7.2G |
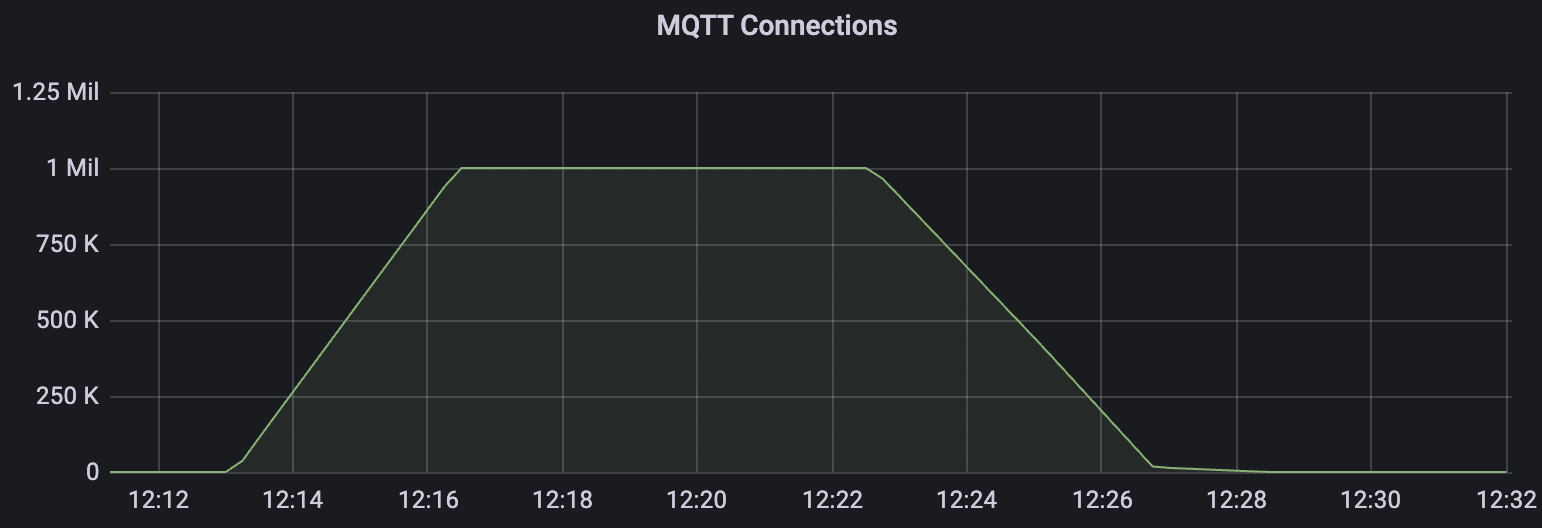
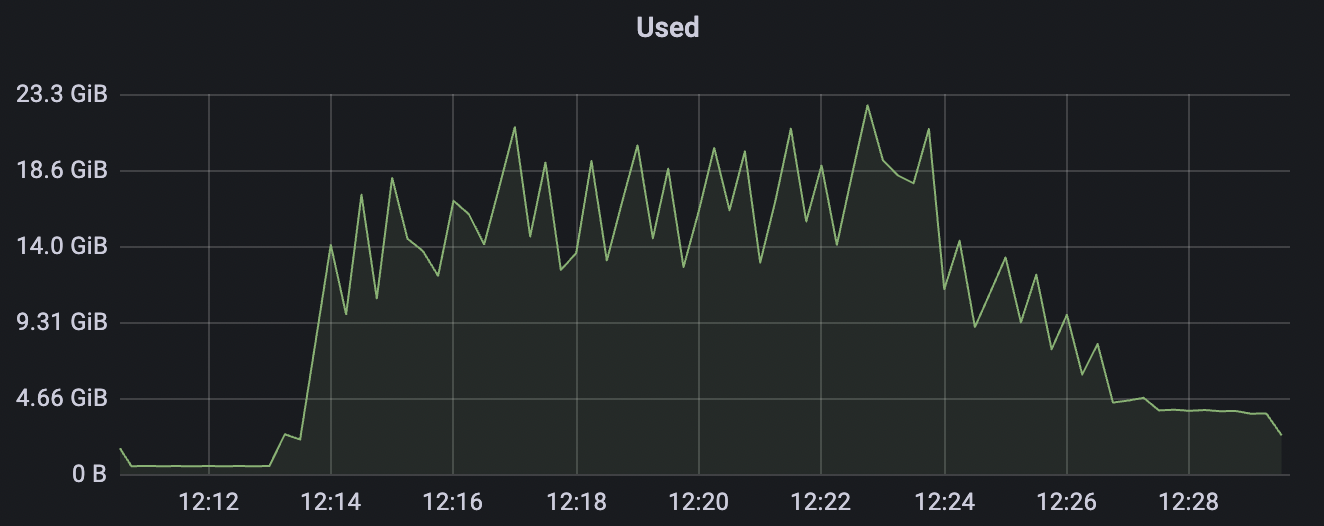
| conn-tcp-1M-5K_1n_false | false | 1M | 5k | 40% | 13G |
conn-tcp-1M-5K_1n_true场景附图:
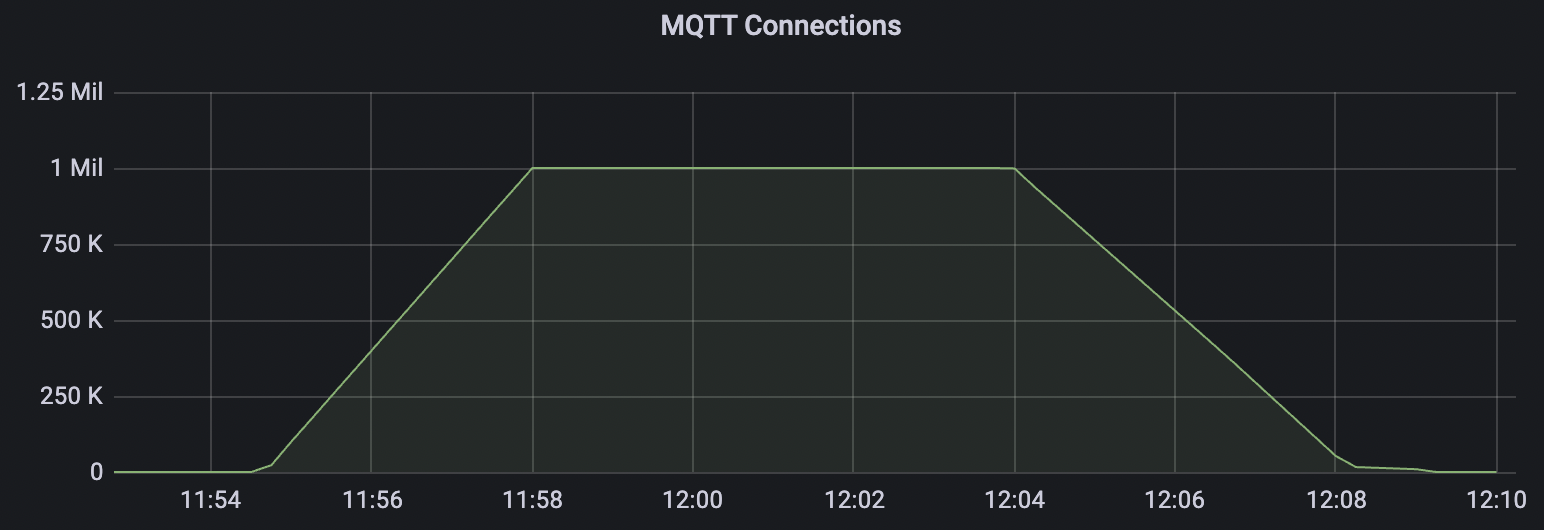
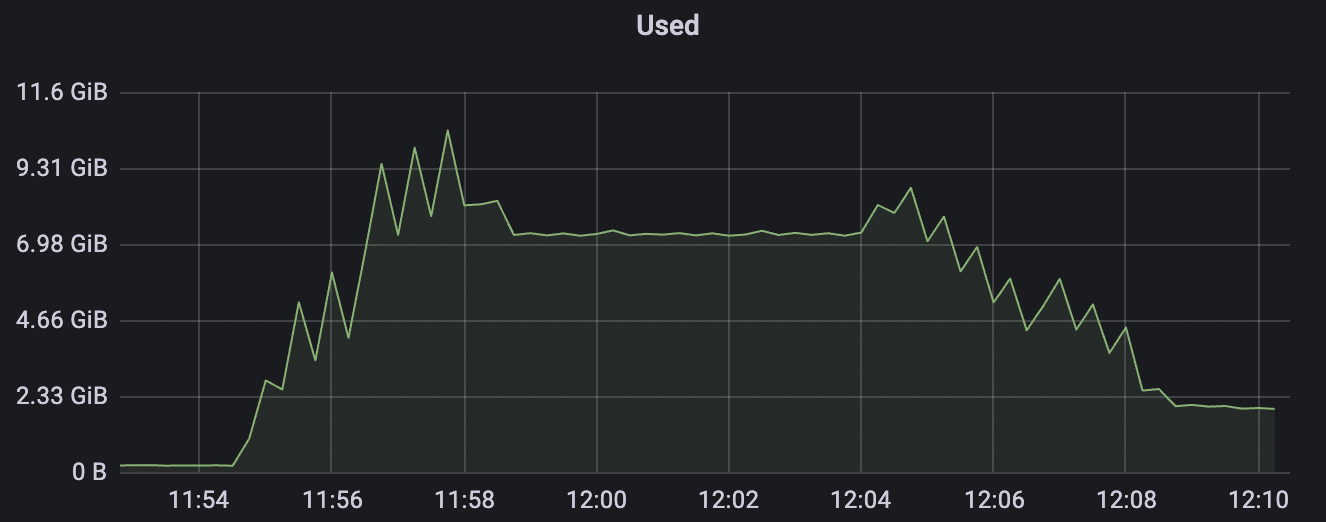
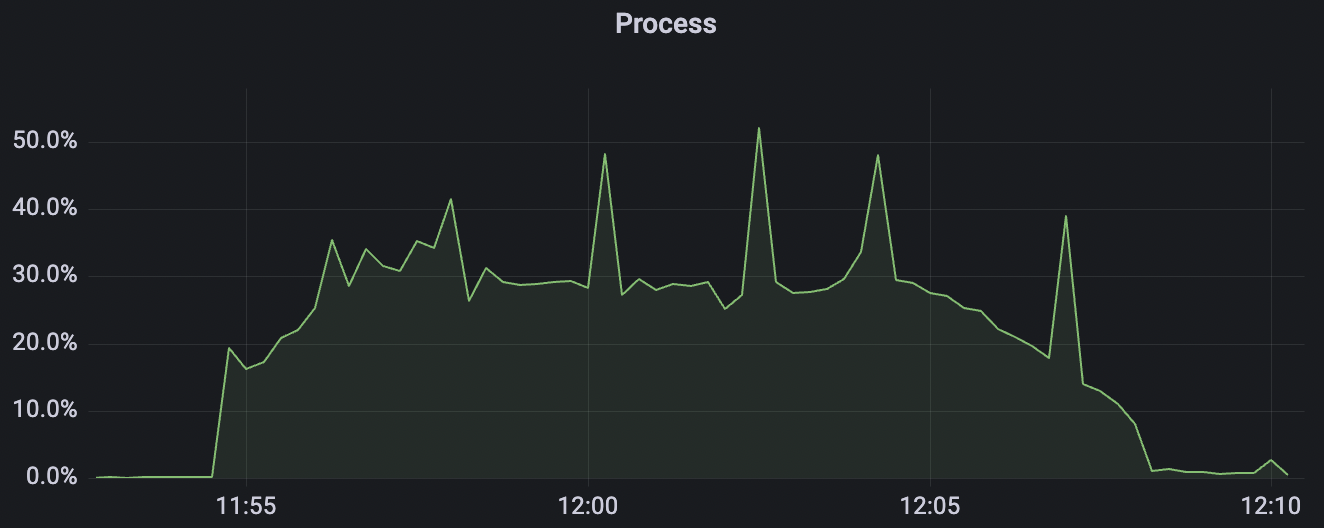
conn-tcp-1M-5K_1n_false场景附图:
系统参数优化
以下Kernel参数会影响BifroMQ所在机器能接受的最大连接数
内存
- vm.max_map_count: 限制一个进程可以拥有的VMA(虚拟内存区域)的数量, 可放大到221184
最大打开文件数
- nofile: 指单进程的最大打开文件数
- nr_open: 指单个进程可分配的最大文件数,通常默认值为1024*1024=1048576
- file-max: 系统内核一共可以打开的最大值,默认值是185745
NetFilter调优
通过sysctl -a | grep conntrack查看当前的参数,以下几个参数决定了最大连接数:
- net.netfilter.nf_conntrack_buckets: 记录连接条目的hashtable的bucket大小
- 修改命令:
echo 262144 > /sys/module/nf_conntrack/parameters/hashsize
- 修改命令:
- net.netfilter.nf_conntrack_max: hashtable最大的条目数,一般为nf_conntrack_buckets * 4
- net.nf_conntrack_max: 同net.netfilter.nf_conntrack_max
- net.netfilter.nf_conntrack_tcp_timeout_fin_wait: 默认 120s -> 30s
- net.netfilter.nf_conntrack_tcp_timeout_time_wait: 默认 120s -> 30s
- net.netfilter.nf_conntrack_tcp_timeout_close_wait: 默认 60s -> 15s
- net.netfilter.nf_conntrack_tcp_timeout_established: 默认 432000 秒(5天)-> 300s
以下sysctl参数会影响大压力下tcp channel性能表现
Server端及测试发压端TCP相关调优
推荐使用centos7环境进行部署及压力测试。
centos6环境需要进行系统参数调优:
- net.core.wmem_max: 最大的TCP数据发送窗口大小(字节)
- 修改命令:
echo 'net.core.wmem_max=16777216' >> /etc/sysctl.conf
- 修改命令:
- net.core.wmem_default: 默认的TCP数据发送窗口大小(字节)
- 修改命令:
echo 'net.core.wmem_default=262144' >> /etc/sysctl.conf
- 修改命令:
- net.core.rmem_max: 最大的TCP数据接收窗口大小(字节)
- 修改命令:
echo 'net.core.rmem_max=16777216' >> /etc/sysctl.conf
- 修改命令:
- net.core.rmem_default: 默认的TCP数据接收窗口大小(字节)
- 修改命令:
echo 'net.core.rmem_default=262144' >> /etc/sysctl.conf
- 修改命令:
- net.ipv4.tcp_rmem: socket接收缓冲区内存使用的下限 警戒值 上限
- 修改命令:
echo 'net.ipv4.tcp_rmem= 1024 4096 16777216' >> /etc/sysctl.conf
- 修改命令:
- net.ipv4.tcp_rmem: socket发送缓冲区内存使用的下限 警戒值 上限
- 修改命令:
echo 'net.ipv4.tcp_wmem= 1024 4096 16777216' >> /etc/sysctl.conf
- 修改命令:
- net.core.optmem_max: 每个socket所允许的最大缓冲区的大小 (字节)
- 修改命令:
echo 'net.core.optmem_max = 16777216' >> /etc/sysctl.conf
- 修改命令:
- net.core.netdev_max_backlog: 网卡设备将请求放入队列的长度
- 修改命令:
echo 'net.core.netdev_max_backlog = 16384' >> /etc/sysctl.conf
- 修改命令:
修改完配置通过sysctl -p并重启服务器生效。